让 VLM 当老师:测试时优化撬动视频推理
不让视频模型自己硬推,而是让 VLM 给中间帧打分、逐样本微调一个 LoRA。RULER-Bench 从 46.4 拉到 68.2。
快速答案
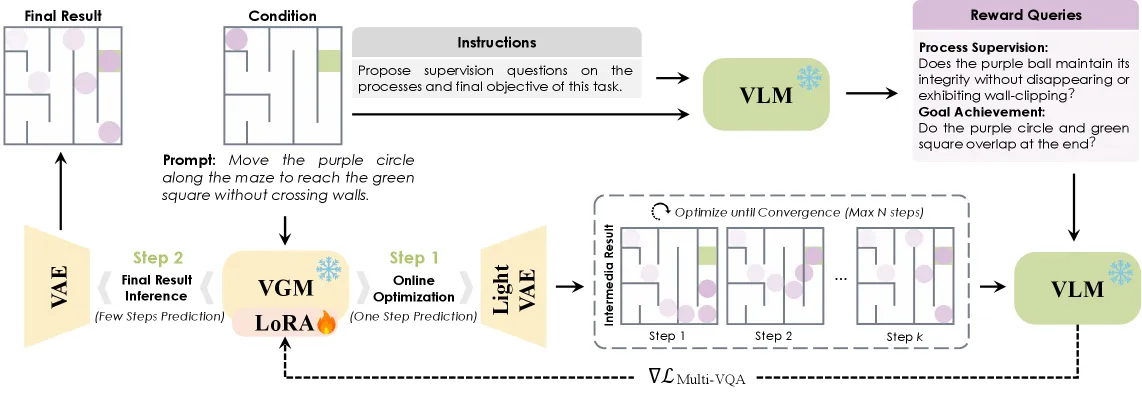
这篇论文把常规思路反了过来。它不去训练一个会”推理”的视频生成模型(VGM),而是冻住视频模型,让一个视觉语言模型(VLM)坐到”阅卷人”的位置。对每一个输入,VLM 先读懂任务、自己写出二元奖励问题,然后盯着视频模型生成的中间帧,把 VQA 损失反传回一个逐样本的小 LoRA。视频模型是学生,VLM 是老师。老师从不亲自解题,只负责告诉学生哪里错了。
收益主要集中在更难、更通用的基准上:RULER-Bench 从冻结基线的 46.4 一路涨到 68.2,提升 21.8 分。符号类的 VBVR-Bench 也涨,但幅度小,从 0.666 到 0.781(+0.115)。一句实话:这本质是一种测试时计算方法。它在每个样本上花优化步数,去换取基础模型一次前向算不出来的推理能力。
老师如何”不解题”却能打分
老师从不产出答案视频。它做两件事。第一,给定任务条件,它合成一个目标达成问题(最终帧满足目标了吗?)和 M 个过程监督问题(M 通常在 1 到 3 之间)来检查中间步骤。第二,在视频模型去噪的过程中,它把预测帧当成一道多问 VQA 题来评判,再把答案 logits 转成可微的奖励。
这个奖励正是闭环跑得通的关键。因为 VLM 的 VQA 损失是可微的,梯度可以穿过预测帧、回流到 VGM Reasoner 的 LoRA 权重上。没有强化学习、不训练奖励模型、没有策略梯度的噪声,只有一个冻结的视频主干,加上几十万个被老师问题牵着走的适配器参数。标题里的”自适应”指的是基于损失的提前停止:多问 VQA 损失一旦低于阈值、或者步数撞到上限 N,优化就停。于是简单样本早早收手,难样本拿到更多算力。
为什么两路奖励缺一不可
VBVR-Bench 上的消融实验是全文最有说服力的部分,因为它把每个零件的贡献拆开了。完全去掉任务专属奖励,分数从 0.781 掉到 0.712(−0.069)。去掉最终目标奖励更糟,0.692(−0.089):没有明确目标,优化就乱走。只去掉过程监督问题代价较小,0.758(−0.023),但仍然伤分。所以目标问题提供方向、过程问题提供塑形;两者都要,而最终目标权重最重。
跟几个显而易见的替代方案比,它赢在”单位成本的质量”而不只是绝对分数。Pass@5(采样五个视频取最好的)在 VBVR-Bench 上只到 0.683、RULER-Bench 上只到 49.1,远低于本方法;而 VideoTPO 甚至把 VBVR-Bench 拉低到 0.634。蛮力采样换不来推理,有针对性的逐样本优化才行。
关键结果
- RULER-Bench:46.4 → 68.2(+21.8)。 这是头条数字,也是通用测试;这么大的差距说明基础视频模型本就有被老师”解锁”出来的潜在能力。
- VBVR-Bench:0.666 → 0.781(+0.115)。 符号推理也涨,但幅度小,暗示这类任务更靠近 VLM 老师自身的感知天花板。
- 碾压 Pass@5 与 VideoTPO。 Pass@5 只带来 +0.017 / +2.7;VideoTPO 涨跌不一(VBVR −0.032、RULER +3.9)。结构化奖励两边都赢。
- 消融证明因果。 最终目标奖励是最关键的一路(去掉 −0.089);过程监督的增益较小但真实存在。
- R²=0.733: 老师 VLM 的理解能力与 RULER-Bench 分数高度相关,方法上限就是老师的眼力。
局限与存疑
作者对失败模式格外坦诚。在对 50 个失败案例的人工审查中,只有 8 个(16%)源于奖励问题写错;另外 42 个(84%)是 VLM 感知错误:老师压根没看出一处细微视觉错误,于是给错误视频打了高分。这意味着天花板是老师而非优化器:R²=0.733 的相关性把这一点摊开来说了。换上一个更敏锐的 VLM,数字应该会动;但这套方法本身修不了一个”看错帧”的老师。
还有两点要留意。实验里的学生主干是 Wan2.2-5B-Distilled,一个步数蒸馏模型,所以论文得专门处理少步预测带来的解码器伪影;在全步、更大的 VGM 上表现如何,尚不清楚。而且逐样本的测试时 LoRA 优化不是免费的:这是推理时训练,每条查询的延迟和算力远高于一次前向。如果你要的是实时视频推理,它现在还不是合适的工具。
常见问题
”VLM 当视频推理的老师”到底是什么意思?
VLM 从不生成答案视频。它写出关于任务的二元奖励问题,盯着冻结视频模型的中间帧,把自己的 VQA 判断变成可微损失,去微调视频模型上的一个逐样本小 LoRA。老师打分,学生(视频模型)变好。
比起多采样几个视频,提升有多大?
大得多。Pass@5(五选一取最好)在 VBVR-Bench 上只加 +0.017、RULER-Bench 上只加 +2.7,而本方法分别加 +0.115 和 +21.8。多采样造不出推理,结构化奖励加逐样本优化才行。
这套方法最大的瓶颈在哪?
老师的感知力。按论文自己的审查,84% 的失败是 VLM 漏看了一处细微视觉错误、给错误视频打了高分;RULER-Bench 分数与 VLM 理解能力的相关性达到 R²=0.733。老师太弱或太”近视”,整个系统就被它卡住。