WASH: Averaging 3 LLMs Erases Text Watermarks
Averaging the output distributions of 3 independent LLMs collapses watermark detection z-scores from 5-300 down below 2, and the WASH paper proves why it works with an O(1/sqrt(N)) error bound.
Quick answer
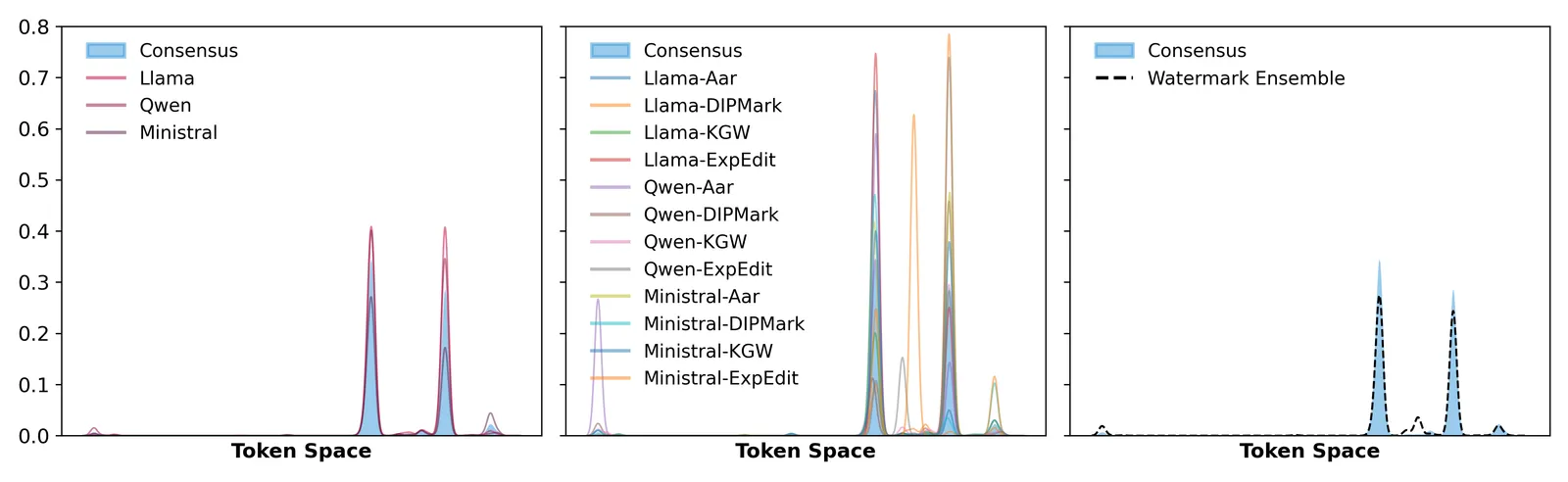
Averaging the next-token probability distributions of just 3 independent language models pushes watermark detection z-scores from a range of 5 to 304 down below 2, under the typical detection threshold of 4. That is the headline of WASH (Watermark Attenuation via Statistical Hybridisation). The attack does not need the watermark key, does not retrain anything, and does not even need to know which scheme is in use.
The core insight is almost embarrassingly simple. A watermark works by nudging a model’s output distribution away from the “honest” one in a key-dependent direction. In a competitive market, OpenAI, Google, and an open model each nudge in their own independent direction. Average those nudges together and they cancel, the same way independent noise averages toward zero. WASH applies this across heterogeneous models and shows it holds empirically across six watermarking schemes and three 8B-class LLMs.
If you build watermark-based provenance or “is this AI text” detection, this paper is a direct threat model you cannot ignore. If you only ever ship a single model, the attack does not apply to you today. The trend toward multi-model routing makes that a shrinking comfort.
How linear ensembling cancels a watermark
A distributional watermark adds a perturbation p_i to the clean consensus distribution p*. The detector later looks for the statistical fingerprint of that specific perturbation. WASH’s claim is that if you query N providers whose perturbations are statistically independent, the simple average of their distributions converges back to p*.
The paper proves this: the ensemble average recovers the consensus distribution up to a second-order error term, with a convergence rate of O(1/sqrt(N)). In plain terms, the first-order watermark signal (the part the detector keys on) averages out, leaving only a small residual that shrinks as you add models. That is why “3 to 5 models” is enough rather than “dozens”: the dominant term dies immediately, and the FAQ below covers why you do not need many more.
The hard part is not the math, it is making heterogeneous models actually averageable. Different LLMs have different vocabularies and tokenizers, so their probability vectors are not aligned and you cannot just add them. This is the engineering contribution.
Inside WASH: aligning mismatched vocabularies
WASH handles two practical obstacles: vocabulary misalignment and tokenization differences across models like Qwen3-8B, Llama-3.1-8B, and Ministral3-8B. When candidate tokens fall outside the shared vocabulary region, naive averaging breaks down. WASH uses fluency-aware routing that defers to a specialist model for those out-of-vocabulary regions rather than corrupting the average with zero-mass entries.
The payoff is that WASH is not just an attack proof-of-concept. It generates fluent text. The paper reports generation quality improved by 27.5% over the competing mixture method, while running about 6x faster than that best baseline on long-sequence generation, operating at only 1.0x to 2.4x the cost of single-model decoding. That cost profile matters: an attack that is 50x slower would be irrelevant in practice, but a 1-2x overhead is the kind of thing a real adversary would actually run.
Key results
- z-scores collapse from 5-304 to below 2. Watermarked single-model baselines produced detection z-scores spanning 5.245 to 304.022; WASH with N=3 suppressed them to roughly 0.059-1.732, and N=5 reached a near-zero 0.079-0.461 band. The detection threshold is 4, so WASH lands comfortably below it.
- TPR at 5% FPR drops below 50%. True-positive rate at a fixed 5% false-positive rate fell from 83.5-95.9% (watermarked) to 11.3-42.8% under WASH with N=5. Detection becomes close to a coin flip or worse.
- Six schemes, all broken. The attack worked across AAR, DIPMark, ITS-Edit, KGW, Exp-Edit, and Water-Bag, i.e. both the popular green-list family (KGW) and distribution-shift / edit-based schemes.
- 27.5% better quality, 6x faster than the strongest mixture baseline, at 1.0-2.4x single-model cost.
Limits and open questions
The whole attack rests on one assumption: that the watermark perturbations across providers are statistically independent. If two providers used a shared watermarking key or a coordinated industry standard, the perturbations would correlate and would not cancel: the second-order error term would no longer dominate. The paper’s threat model is “competitive market with independent providers,” which is realistic today but is also exactly the thing a coordinated standards body could undermine.
Second, the evaluation is all at the 8B scale across three model families. Whether the independence assumption and the quality gains hold when one of the ensembled models is far stronger (a frontier model averaged with weak ones) is not something I would assume transfers cleanly. Averaging in a weak model could drag quality down in a way three peers do not.
Third, this targets distributional watermarks. Semantic or post-hoc watermarks that operate outside the token distribution are out of scope, and the paper does not claim to defeat them.
FAQ
How does WASH remove LLM watermarks without the key?
WASH never touches the watermark key. It averages the output probability distributions of 3-5 independently watermarked models. Because each provider’s watermark perturbs the distribution in an independent direction, the average cancels the first-order signal and recovers the clean distribution up to an O(1/sqrt(N)) error, dropping detection z-scores below the threshold of 4.
Why are only 3-5 models enough to defeat the watermark?
The convergence is O(1/sqrt(N)), but the key point is that the first-order watermark term, the exact signal detectors test for, cancels immediately under independent averaging, leaving only a shrinking second-order residual. So 3 models already push z-scores under 2; adding more (N=5) only tightens the residual further rather than being strictly necessary.
Does WASH break every text watermark?
In this paper, WASH broke all six tested distributional schemes (AAR, DIPMark, ITS-Edit, KGW, Exp-Edit, Water-Bag) on three 8B LLMs. It explicitly targets distributional perturbation watermarks; it does not claim to defeat semantic or coordinated shared-key watermarks, and breaking those would violate its independence assumption.