Language Models · Transformers
NITP: Predict the Next Token's Meaning, Not Just Its ID
NITP adds a dense target to next-token prediction: forecast a shallow-layer embedding of the next token. On a 9B MoE it lifts MMLU-Pro by 5.71 points for about 2 percent extra training FLOPs and zero inference cost.
Quick answer
NITP (Next Implicit Token Prediction) augments standard next-token prediction with a second, continuous objective: predict a shallow-layer hidden representation of the next token, not just its discrete ID. The signal is dense and self-supervised, so it costs roughly 2 percent additional training FLOPs and zero inference overhead. On a 9B Mixture-of-Experts model it raised MMLU-Pro from 15.29 to 21.00, a 5.71-point absolute gain, with a +2.67-point average across 13 benchmarks.
The problem NITP targets
Standard next-token prediction (NTP) supervises a model with one scalar per position: the cross-entropy on the correct token ID. That target is discrete and sparse. The full hidden state at each position carries far more structure than a single label can pin down, so most of the representation’s geometry is shaped only indirectly. The authors argue this leaves the optimization landscape under-constrained and lets representations collapse toward low-rank, less expressive geometry. NITP’s premise: hand the model a richer, continuous target at every position so the representation space is supervised directly, not just read out at the very end.
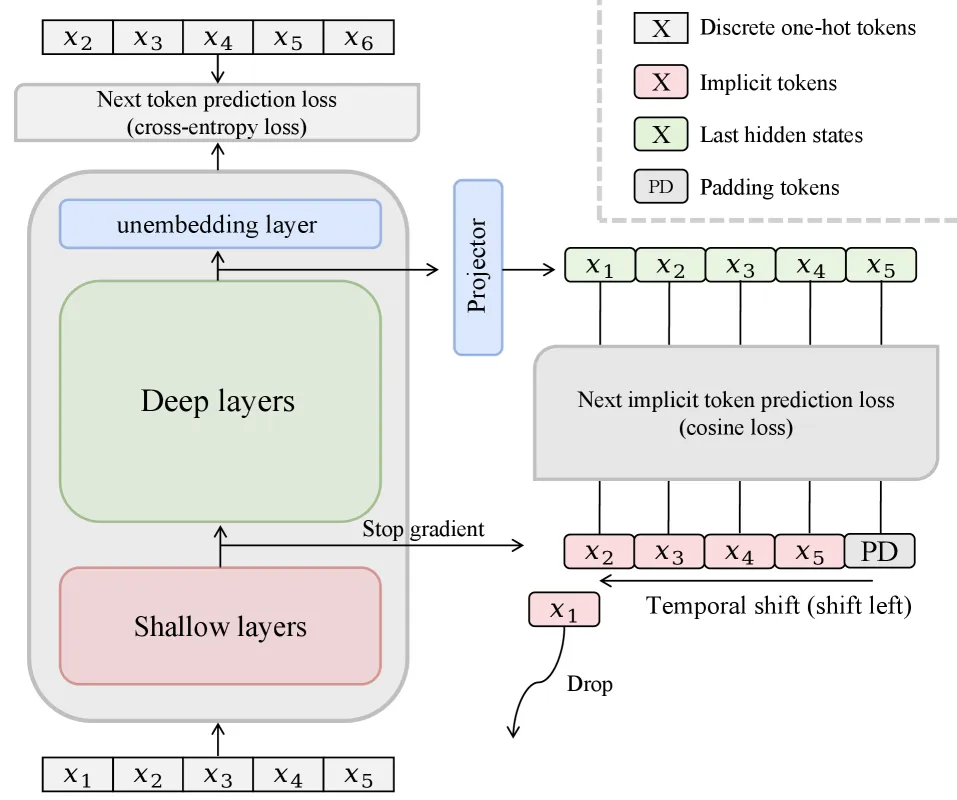
How NITP works
NITP keeps the NTP head untouched and adds a parallel “implicit token” objective. The recipe has three deliberate choices:
- Target source — shallow layers. The prediction target is the hidden representation drawn from an early layer (around 20 percent of model depth), passed through a stop-gradient so it acts as a stable self-supervised teacher rather than a moving target. Ablations show shallow-layer targets clearly beat middle- or deep-layer ones.
- Temporal shift — predict the next token’s representation. The model at position t is trained to match the implicit token of position t+1, mirroring NTP’s look-ahead. Aligning to the current position instead substantially underperforms.
- Loss — cosine similarity. Alignment uses a scale-invariant cosine loss; the authors report MSE caused divergence. The combined objective is L_total = L_NTP + lambda * L_NITP, with lambda = 1.0 optimal.
Because the target is built from the model’s own early activations, there is no extra parameter to ship at inference and no labeled data to collect.
Why this matters now
Frontier pre-training is FLOP-bound, so a method that buys multi-point benchmark gains for a ~2 percent training surcharge and nothing at inference is unusually cheap. NITP also sits in the same lineage as multi-token prediction and other auxiliary pre-training objectives, but its target is a continuous representation rather than additional discrete tokens — a different lever on the same problem of making NTP’s supervision denser. The reported effective-rank and cosine-geometry measurements give a concrete story for why it helps: representations stay higher-rank and better-structured.
Key results
- 9B MoE (1B activated): MMLU-Pro 15.29 to 21.00 (+5.71), C3 56.65 to 63.01 (+6.36), CommonsenseQA 45.70 to 49.96 (+4.26), and a +2.67-point average over 13 tasks (40.27 to 42.94).
- 3B dense: +1.35-point average across seven benchmarks, with C3 +4.66 and MMLU +1.41 — gains hold for dense models, not only MoE.
- Scale coverage: evaluated across MoE configurations from 1.9B to 45B (0.3B to 5.5B activated) and dense models from 0.5B to 3B.
- Cost: about 2 percent additional training FLOPs with negligible wall-clock increase, and no inference-time cost since the implicit-token head is dropped after training.
- Geometry: representations trained with NITP show higher effective rank, supporting the claim that the dense target counters representation collapse.
Limits and open questions
The paper does not provide a dedicated limitations section, so read the boundaries from what it tested. The largest reported model is 45B MoE with 5.5B activated parameters — well below frontier scale, so whether the 2-percent-for-multi-point trade survives at hundreds of billions of parameters is unverified. The shallow-layer target, temporal shift, and cosine loss are presented as the winning configuration via ablation, but the sensitivity around the 20-percent-depth choice and lambda = 1.0 across very different architectures is not exhaustively mapped. The benchmark gains are largest on knowledge and reading-comprehension tasks like MMLU-Pro and C3; how much transfers to generation quality, long-context, or reasoning chains is not directly measured. Finally, the result that MSE diverges while cosine is stable hints the method is sensitive to target normalization, which deployment teams should treat as a tuning risk rather than a free lunch.
FAQ
What does NITP actually predict that NTP does not?
NITP predicts a continuous representation of the next token — specifically a shallow-layer hidden state from the model itself, used as a stop-gradient target — in addition to NTP’s discrete next-token ID. It is a dense, self-supervised signal layered on top of cross-entropy, not a replacement for it.
How much does NITP cost to add?
About 2 percent extra training FLOPs with negligible wall-clock impact, and zero inference cost. The implicit-token prediction head is used only during training and dropped afterward, so deployed models run identically to an NTP baseline.
Does NITP help dense models or only Mixture-of-Experts?
Both. The headline 9B result is MoE (+2.67 average, +5.71 on MMLU-Pro), but a 3B dense model also gained +1.35 on average across seven benchmarks, with +4.66 on C3, indicating the objective is not specific to MoE routing.
Why does NITP use a shallow layer as the target instead of a deep one?
Ablations show shallow-layer targets (around 20 percent depth) outperform middle and deep alternatives. The intuition is that early-layer representations are more stable and token-grounded, making them a cleaner self-supervised teacher than late layers that are already specialized for the NTP readout.
One line: give next-token prediction a dense companion target — the next token’s shallow-layer representation — and a 9B MoE gains 5.71 points on MMLU-Pro for roughly 2 percent more training compute. Read the original paper on arXiv.