VLM3:视觉语言模型天生就是 3D 学习者
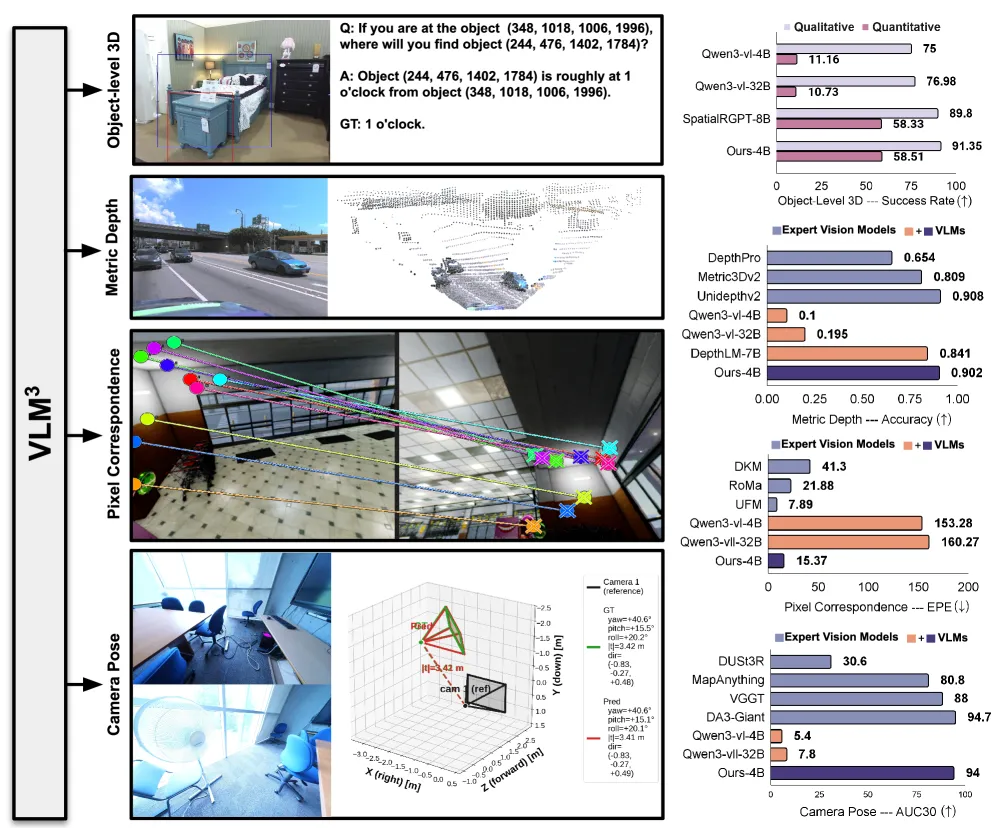
VLM3 证明一个标准 4B 视觉语言模型无需 3D 专用架构就能比肩专家模型:深度精度 0.904、相机位姿 AUC 94.0%、物体级 3D 精度 91.35%。
快速答案
VLM3 的主张很直接:一个普通的视觉语言模型,不加任何 3D 专用架构、不用专门的几何损失,学 3D 学得和专家模型一样好。4B 模型在 8 个数据集上的度量深度平均 δ₁ 达到 0.904,与 UnidepthV2、MoGe-2 持平,并把 DepthLM 的 0.84 提升到 0.90。相机位姿在 ETH3D 与 ScanNet++ 上拿到 94.0% 的 AUC@30°,与 DA3-Giant 的 94.7% 统计上打平,超过 VGGT。论文原话是:「焦距统一、文本像素引用、数据混合与扩展,就是有效 3D 学习的全部所需。」言下之意是,整个领域一直在过度设计 3D——堆代价体、深度解码器、定制损失去解决一个通用 Transformer 本就能从数据中吸收的问题。
问题:为什么过去认为 VLM 不擅长 3D
视觉语言模型读像素、输出文本,而 3D 视觉活在连续几何里——以米为单位的深度、相机旋转、稠密的逐像素对应。过去的共识是文本解码会丢掉 3D 所需的空间精度,于是大家不断堆带几何组件的专家模型。VLM3 攻击的不是架构本身,而是两个让 VLM 落后的具体障碍。
第一是相机歧义:同一场景在不同焦距下拍摄,像素到深度的关系不同,于是在混合数据上训练时,视觉上相同的输入却收到矛盾的监督信号。第二是如何指向一个像素:早期的视觉提示法要在图上叠加标记来指定位置,既笨重又破坏了干净的文本接口。
方法:三处改动,不动架构
VLM3 保留标准 VLM 栈和基于文本的训练范式,只加三样东西。
焦距统一把每张图缩放到等效焦距 1000 像素,消除上述相机歧义,让不同相机、不同数据集的数据可以直接混合——这是扩展的前提。
文本像素引用彻底丢掉视觉标记,模型用 [0, 2000) 范围内的归一化整数坐标以文本形式指代像素。论文报告这种方式精度与视觉提示相当,却让对应与位姿任务变成普通的文本生成。
数据混合与扩展是作者最看重的一环。他们发现前两项就位后,数据集权重「在扩大训练时(几乎)成了最重要的事」——按数据集规模加权,防止模型过拟合到最大的那个语料。整套方法没有新损失、没有 3D 解码器,收益全来自把异构 3D 数据变得可大规模训练。
关键结果
单个 4B 的 VLM3 覆盖了通常需要四套专家系统的四类任务:
- 度量深度(δ₁,越高越好):8 数据集平均 0.904,比肩 UnidepthV2 与 MoGe-2;把 DepthLM-7B 的 0.84 提升到 0.90,且参数更少。
- 相机位姿(AUC@30°,越高越好):ETH3D 与 ScanNet++ 平均 94.0%,与 DA3-Giant 的 94.7% 统计打平,超过 VGGT。
- 物体级 3D 理解:定性精度 91.35%、定量精度 58.51%,两项均超过 SpatialRGPT-8B。
- 像素对应(EPE,越低越好):平均 15.37 像素,相对基线 VLM 约降低 10 倍,胜过专家匹配器 DKM 与 RoMa。
实话实说:深度与位姿是真正的亮点,VLM3 在这里确实追平了最强专家。对应任务它有竞争力,但没领先。
局限与存疑
最重要的保留意见在对应任务。VLM3 的 15.37 EPE 胜过 DKM 和 RoMa,却落后专家匹配器 UFM 的 7.89 EPE——误差约为两倍。所以「VLM 比肩专家」对深度、位姿、物体级 3D 成立,但对稠密匹配还不成立,专用模型仍领先 2 倍。
作者把剩下的差距归因于数据而非架构,认为「进一步扩展和更精细的数据混合调优」能补上——这是假设,不是已证明的结果。由此引出若干疑问:在匹配这个最前沿,无 3D 架构的叙事还成立吗,还是说对应任务需要文本接口表达不出的精度?焦距统一对极端或未知内参的泛化到哪一步?而 [0, 2000) 的坐标量化本身就给空间精度设了上限——这是用文本指像素的内在天花板。
常见问题
VLM3 是什么?
VLM3 是 Meta 与普林斯顿提出的视觉语言模型,无需任何 3D 专用架构或专门损失就能学习度量深度、相机位姿、像素对应、物体级 3D 等任务。其 4B 版本在多数任务上比肩专家视觉模型。
VLM3 为什么不用 3D 架构也能比肩专家模型?
靠对标准 VLM 的三处改动:焦距统一(把图缩放到 1000 像素焦距以消除相机歧义)、文本像素引用(用 [0, 2000) 文本坐标代替视觉标记指代像素)、以及按数据集规模加权的数据混合与扩展。
VLM3 比 DepthLM、SpatialRGPT 强吗?
深度上 VLM3 用更小的 4B 模型把 DepthLM-7B 的 δ₁ 从 0.84 提到 0.90;物体级 3D 理解上定性(91.35%)与定量(58.51%)均超过 SpatialRGPT-8B。
VLM3 有什么做不好的?
稠密像素对应。VLM3 的 15.37 EPE 优于 DKM 和 RoMa,但专家匹配器 UFM 以 7.89 EPE 大幅领先,误差约为其两倍——这是唯一仍被专家击败的任务。
VLM3 里的「焦距统一」是什么意思?
把每张图缩放到等效焦距恒为 1000 像素。因为焦距决定了像素如何映射到真实深度,固定焦距就消除了在多种相机图像上训练时本会出现的矛盾监督。