Orchestra-o1:全模态智能体编排详解
Orchestra-o1 把文本、图像、音频、视频拆给子智能体并行跑,GPT-5 当大脑在 OmniGAIA 拿 72.8%,训练的 8B 编排器拿 30.0%,居开源全模态智能体首位。
快速答案
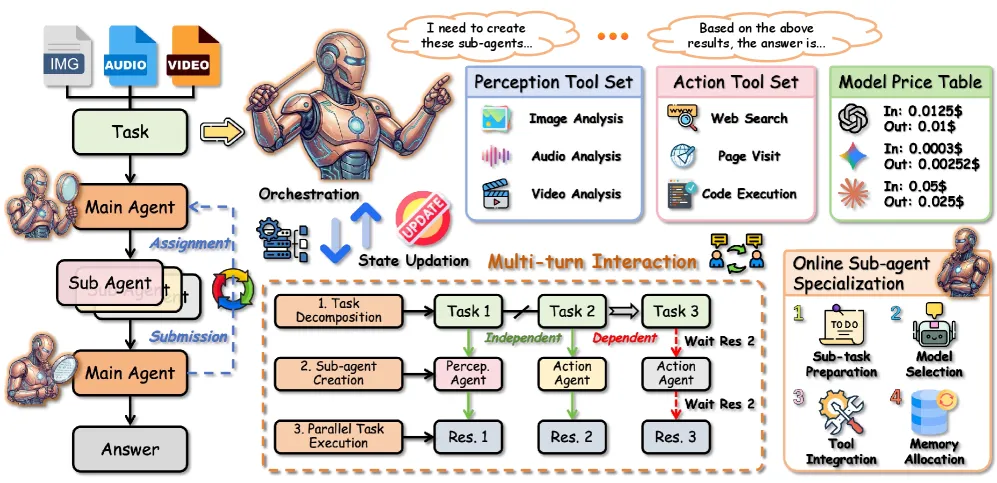
Orchestra-o1 是一套智能体编排框架,把全模态任务拆给文本、图像、音频、视频和工具的专门子智能体,再把彼此独立的子任务并行跑。用 GPT-5 当编排大脑时,它在 OmniGAIA 上拿 72.8%,比 Gemini-3-Pro(62.5%)高 10.3 分,比同样跑在 GPT-5 上的旧编排框架 AOrchestra(40.0%)高 32.8 分。读这篇要分清两个数。72.8% 来自闭源的 GPT-5 后端,不是论文训出来的任何东西。论文真正训练的是一个用 DA-GRPO 方法做出来的 8B 编排器,它拿 30.0%,这才是模型层面的贡献,也是开源全模态智能体里最高的(OmniAtlas-Qwen3-30B 是 20.8%)。
这套框架到底做什么
一个全模态任务,比如看一段视频、读一张图表、回答一个两者都要的问题,会把单个智能体的上下文和工具集撑爆。Orchestra-o1 的主智能体在子目标上建一张依赖图,每个子目标带一个模态掩码(文本/图像/音频/视频)和一个工具掩码。掩码是有意思的地方:不是每个子智能体都看到所有工具和所有输入流,而是各自被限定在它需要的证据上。一个只需要音频分析的子目标,根本不碰视频管线。
上面架着三个机制。模态感知拆解负责建图。在线子智能体特化按一个成本感知的匹配分给每个子任务挑后端,在能力、延迟和价格之间权衡,再分一个稀疏的工具子集。并行执行把一轮派发里所有独立子任务一起跑;论文的命题 1 把单轮加速比卡在 1 倍到任务数 K 之间,上界是同步开销。主智能体自己不带工具,只做编排,所以它的上下文窗口很小(24576 token),重活交给子智能体(每个最多 30 步)。
工具集是六个函数:图像、音频、视频分析,网页搜索,页面访问,代码执行。MemDreamer 攻的是相邻问题:在长程多模态上下文上做智能体检索,两篇对着读很合适。Orchestra-o1 把上下文分散到子智能体,而不是压进一份记忆里。
DA-GRPO 怎么训练这个 8B 编排器
标准 GRPO 奖励的是最终答案。对编排器来说,问题在于:好答案可能来自糟糕的派发,坏答案可能来自合理的派发,所以最终答案奖励对编排决策是个很吵的老师。决策对齐的 GRPO(DA-GRPO)换成一个多维度评分卡奖励,由一个外部模型(Claude Haiku 4.5)打分:格式正确(权重 0.1)、动作有效(0.1)、工具合理(0.2)、决策质量(0.6)。0.6 这个重权压在决策质量上,是设计上的赌注:梯度主要追的是拆解和派发对不对,而不是最终字符串匹不匹配。
在 8B 底座(Qwen3-8B)上,这套配方是一点点叠上去的。光框架就把 ReAct 基线从 12.5% 抬到 26.3%。在筛过的轨迹上做 SFT 加到 28.6%。普通 GRPO 反而更低,27.7%,只有 DA-GRPO 到 30.0%。所以 DA-GRPO 比普通 GRPO 高 2.3 分,比 SFT 高 1.4 分,确实有,但 8B 分数的大头来自编排 harness,不是 RL 目标。用步级奖励而不是只看结果来训智能体的思路,在 DenovoSWE 这类代码智能体里也出现过,长动作链里中间信号很要紧。
关键结果
- OmniGAIA 闭源设定: Orchestra-o1-GPT-5 拿 72.8%,Gemini-3-Pro 62.5%(+10.3),Gemini-3-Flash 51.7%,AOrchestra-GPT-5 40.0%(+32.8),Gemini-2.5-Pro 30.8%。对 AOrchestra 的大差距是编排设计带来的,因为两者都跑在 GPT-5 上。
- 不只是准确率,还有成本: Orchestra-o1-GPT-5 报告成本 341.6,AOrchestra-GPT-5 是 565.7。准确率更高,成本约为对方六成,这个结论比单看准确率更站得住。
- 开源设定: DA-GRPO 训出的 Orchestra-o1-8B 拿 30.0%,OmniAtlas-Qwen3-30B 是 20.8%(+9.2),打赢了一个近 4 倍参数的模型。
- 难度分档(GPT-5): 简单 80.3%,中等 75.0%,困难 56.4%。困难档 56.4% 是全模态编排仍吃力的地方,也是 72.8% 这个头条数字盖住的方差所在。
- 消融(Qwen3-8B): ReAct 12.5 -> 框架 26.3 -> SFT 28.6 -> 普通 GRPO 27.7 -> DA-GRPO 30.0。框架贡献 +13.8;DA-GRPO 比 SFT 多 +1.4。
- 后端决定上限: 72.8% 是 GPT-5 的结果。框架是可复用的部件,分数跟着你插进去的大脑走。
怎么读 72.8 这个数
72.8% 是”编排 + GPT-5”的数,它没说 Orchestra-o1 是个强模型。它说的是:一个好的编排层从 GPT-5 里多榨出 10.3 分,比 Gemini-3-Pro 自己跑高这么多,比旧编排框架在同一个 GPT-5 上高 32.8 分。作者真正做出来并训练的是那个 8B,它拿 30.0%。把这两个混为一谈,拿 72.8% 当成一个训练系统的能力,就是最容易犯的误读。框架的公平对照是相同后端下的 AOrchestra;训练模型的公平对照是别的开源全模态智能体。
局限与存疑
OmniGAIA 是沿用旧工作的基准,不是这篇新建的,所以泄漏风险和各类别样本量是继承来的,本文没有重新审。金融类 83.8% 对历史类 64.0% 的落差,说明各类别覆盖不均,信任任何单一类别数字前都该核一下。成本 341.6 用的是论文自己的单位,没有 token 或墙钟拆解,所以跨系统的成本结论都建在这套记账上。DA-GRPO 依赖一个外部评分器(Claude Haiku 4.5),意味着 30.0% 反映的是这个评分器对决策质量的判断;换个评分器可能挪动奖励信号,也挪动结果。并行执行的加速比是证了一个界,不是带真实同步开销端到端测出来的。还有,72.8%(GPT-5)和 30.0%(训练的 8B)差得够大,所以这套框架今天的价值主要是给前沿闭源模型当外壳,开源 8B 还落后不少。
常见问题
Orchestra-o1 是什么,谁做的?
Orchestra-o1 是 LUMIA Lab 做的全模态智能体编排框架,作者来自 CUHK、北京大学、清华、同济大学、中科院自动化所(CASIA)等机构。主智能体把任务拆成按模态界定范围的子目标(文本、图像、音频、视频),用成本感知的后端选择给子任务分专门子智能体,把独立子任务并行跑。用 GPT-5 时在 OmniGAIA 拿 72.8%。
为什么 Orchestra-o1 用 GPT-5 拿 72.8%,训练的 8B 只有 30.0%?
72.8% 是把编排框架跑在 GPT-5 后端上的结果,衡量的是 harness 加一个前沿模型。30.0% 是 Orchestra-o1-8B,作者用 DA-GRPO 在 Qwen3-8B 底座上真正训出来的模型。8B 这个数才是模型层面的贡献,领先开源全模态智能体(OmniAtlas-Qwen3-30B 是 20.8%);72.8% 是框架配上强大脑时的上限。
Orchestra-o1 里的 DA-GRPO 和标准 GRPO 有什么不同?
标准 GRPO 只奖励最终答案对不对,这对编排是个很吵的信号,因为好的派发也可能没答对。DA-GRPO 用一个由 Claude Haiku 4.5 打分的评分卡奖励,跨格式(0.1)、动作有效(0.1)、工具合理(0.2)、决策质量(0.6)。在 Qwen3-8B 上它拿 30.0%,普通 GRPO 是 27.7%,SFT 是 28.6%。
Orchestra-o1 比 AOrchestra 便宜多少?
在 OmniGAIA 上用 GPT-5,Orchestra-o1 报告成本 341.6,AOrchestra 是 565.7,而准确率是 72.8% 对 40.0%。所以它既更准又便宜约四成(按论文的成本单位),这让效率结论比单看准确率更有说服力。
OmniGAIA 是 Orchestra-o1 提出的新基准吗?
不是。OmniGAIA 是已有的全模态智能体基准,覆盖文本、图像、音频、视频输入,分难度档(简单/中等/困难)和主题类别。Orchestra-o1 是在它上面评测,不是提出它,所以它的构造、泄漏控制和样本量都来自原始基准论文。
一句话:Orchestra-o1 表明全模态编排能从 GPT-5 上多榨 10.3 分(OmniGAIA),而 DA-GRPO 训出的 8B 以 30.0% 领跑开源全模态智能体;把 72.8% 的框架结果和 30.0% 的模型结果分开看。阅读 arXiv 原文。