Vision-Language-Action · Robotics · Multimodal Models
ACE-Ego-0: Unifying Egocentric Human and Robot Data for VLA Pretraining
ACE-Ego-0 pretrains a VLA on 6,000+ hours mixing robot trajectories with human egocentric video turned into pseudo-actions. It averages 78.3% on six real bimanual tasks vs 71.7% for pi-0.5 and 35.6% for GR00T-N1.7.
Quick answer
ACE-Ego-0 is a vision-language-action model pretrained on a 6,013-hour pool that mixes 4,534 hours of robot demonstrations with 1,479 hours of human egocentric video converted into robot-shaped pseudo-actions. On six real bimanual tasks (ARX platform) it averages 78.3% success, ahead of pi-0.5 at 71.7% and GR00T-N1.7 at 35.6%. On the RoboCasa GR1 TableTop sim benchmark it hits 72.8%. The headline is not the human-video pipeline by itself: in the data ablation, adding human video lifts RoboCasa from 68.3% (robot-only) to 72.8%, a +4.5 point gain, while the reliability-aware loss that keeps the noisy human signal from poisoning training is the single most important component (-3.6 points when removed).
The data-scaling problem it targets
Collecting robot trajectories is slow and expensive, so VLA pretraining is starved for embodied data. Human egocentric video is abundant and cheap, but a person’s hand and a robot’s gripper live in different action spaces and embodiments, and human video has no recorded actions at all. ACE-Ego-0’s bet is that you can recover usable pseudo-actions from human video and pour it into the same pretraining pool as robot data, as long as you tell the model how reliable each source is.
The interesting part is the honesty about reliability. Reconstructed human hand poses are good for where the hand goes and weak for how it is oriented and whether the gripper is open. So the model is trained to trust human video for position and almost ignore it for rotation and gripper state.
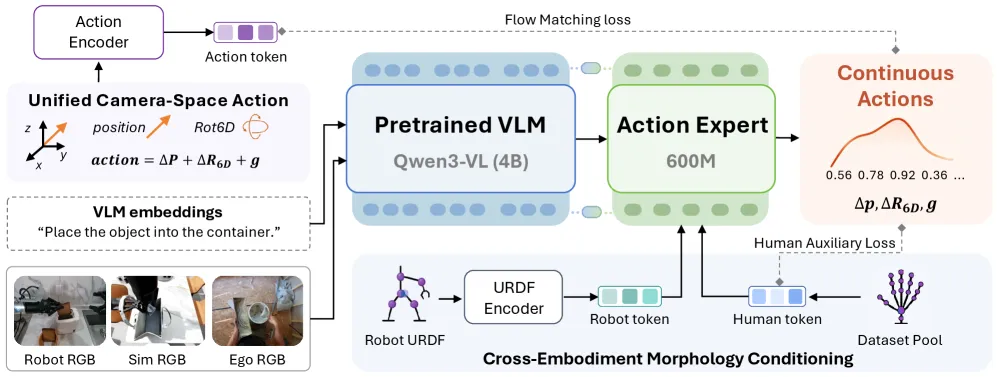
How human and robot data are unified
Three alignments put both sources into one canonical format:
- Spatial: robot end-effector poses and reconstructed human wrist trajectories are both expressed in the head-camera frame. For humans the wrist is the end-effector, hand orientation comes from the palm plane, and thumb-to-palm distance is a gripper proxy normalized to the robot’s stroke range. Output is a 22-D bimanual vector (11-D per arm: 3-D position, 6-D orientation, gripper, activity flag).
- Structural: each embodiment is described by a morphology token. Robots get a URDF graph encoding (joints, limits, chains); human datasets get learned surrogate embeddings. These tokens condition the action expert but never enter the shared vision-language backbone, so morphology stays out of the perception features.
- Temporal: action chunks are cut by physical duration (2 seconds), not step count, so a 30 Hz human clip and a 10 Hz robot log describe the same real time window. H_d = round(f_d x T*).
The video-to-action pipeline is a five-stage funnel: curate egocentric clips, filter to manipulation segments, reconstruct 3-D hands with SAM3 tracking plus HaMeR pose estimation, parameterize MANO poses into camera-space pseudo-actions, then drop clips with NaNs, no motion, or spike artifacts.
Why the reliability weighting carries the result
The pseudo-actions are noisy, and naively training on them as if they were sensor logs would corrupt the robot-anchored objective. ACE-Ego-0 uses a per-channel, per-step weight W. The channel prior is blunt: position channels get weight 1.0, rotation and gripper get 0.001. So human video supervises where to move and is effectively muted on orientation and grasp. On top of that a step weight down-weights frames with large jumps or jerk. The human auxiliary loss is a Huber loss scaled by W, added to the main robot flow-matching loss at lambda = 0.1.
This is the component the ablation rewards most. Removing the reliability-aware human auxiliary loss drops RoboCasa from 72.8% to 69.2%, a 3.6-point fall, larger than removing morphology tokens (1.9) or time-aligned chunking (1.1). Cheap human video helps, but only because the training is set up to treat it as a weak position prior rather than ground truth.
Key results
- Real-robot average (6 ARX bimanual tasks, 30 trials each): 78.3% for ACE-Ego-0 vs 71.7% for pi-0.5 (+6.6) and 35.6% for GR00T-N1.7 (+42.7). Per Figure 5(a), ACE-Ego-0 leads or ties on all six tasks. The GR00T gap is huge on dynamic tasks: Sweep Cubes 73.3% vs 6.7%, Scoop Coffee 83.3% vs 36.7%, Pack Shoes 60.0% vs 10.0%.
- RoboCasa GR1 TableTop (24 tasks, 50 rollouts each): 72.8% average, ahead of DIAL (70.2%), JoyAI-RA (63.2%), and GR00T-N1.6 (47.6%).
- RoboTwin 2.0 (50 tasks): 91.12% easy / 90.62% hard, narrowly topping JoyAI-RA (90.48 / 89.28) and well above pi-0.5 (82.74 / 76.76).
- Data ablation: Robot+Human 72.8%, Robot-only 68.3% (+4.5 from human video), Qwen-only with no embodied pretraining 65.4%.
- Component ablation: reliability-aware human loss is worth 3.6 points, the largest of any single piece.
- Data-scarce fine-tuning: on Sweep Cubes with only 34 robot demos (0.062 m2 workspace), adding 419 human episodes that cover 0.296 m2 (4.8x broader) lifts success from 10% to 40%. The human video fills workspace regions the robot teleoperation never reached.
How to read the comparisons
The +42.7 point margin over GR00T-N1.7 on real robots is the loudest number, and it is the easiest to misread. GR00T is a generalist not specialized to this exact ARX bimanual setup, and a single hardware platform with six tasks is a narrow slice. The fairer signal is the +6.6 over pi-0.5, a strong same-class baseline, and the controlled data ablation showing +4.5 from human video on a fixed architecture. Treat ACE-Ego-0 as evidence that filtered human video is a useful position prior for tabletop manipulation, not as proof of a general VLA frontier. The “leads on every task” framing also needs a second look: on Pick Tea ACE-Ego-0 only ties pi-0.5 (86.7% each, no human-video gain there), and on Sweep Cubes and Stack Bowls its edge over pi-0.5 is a single trial (73.3% vs 70.0%, 80.0% vs 76.7%) on a 30-trial denominator, well inside the noise. The win over pi-0.5 is real on average but thin task-by-task.
Limits and open questions
Evaluation is tabletop manipulation only; mobile manipulation, whole-body humanoid, and deformable objects are untested. The pretraining pool has no dexterous-hand, force, or torque data, which is exactly what contact-rich tasks need. The pseudo-action pipeline’s own admitted weakness is rotation and fine finger motion, and the model papers over this by setting the rotation weight to 0.001, so human video contributes essentially nothing to orientation learning. There is no token, wall-clock, or compute cost reported for the 6,000-hour pretraining, so the practicality of the recipe at smaller budgets is unknown. The 4x data-scarce result is one task with a 10-trial denominator, so 10% to 40% is 1/10 to 4/10, encouraging but statistically thin.
FAQ
How much does human video actually add in ACE-Ego-0?
In the controlled RoboCasa ablation, adding human egocentric video lifts success from 68.3% (robot-only) to 72.8%, a +4.5 point gain on the same architecture. In a deliberately data-scarce fine-tuning setup (Sweep Cubes, 34 robot demos), adding 419 human episodes raised success from 10% to 40%. The gain is real but largest when robot data is sparse, because human video covers workspace regions the robot demos missed.
Does ACE-Ego-0 beat pi-0.5 and GR00T on real robots?
On six real bimanual ARX tasks ACE-Ego-0 averages 78.3% vs 71.7% for pi-0.5 (+6.6) and 35.6% for GR00T-N1.7 (+42.7), and per Figure 5(a) it leads or ties on all six. The margins are thin, though: it merely ties pi-0.5 on Pick Tea (86.7% each), and its lead on Sweep Cubes (73.3% vs 70.0%) and Stack Bowls (80.0% vs 76.7%) is one trial out of 30. The large GR00T gap is partly because GR00T is a generalist not tuned for this specific platform. For background on this class of model see the VLA topic.
Why does ACE-Ego-0 down-weight rotation from human video?
Reconstructed human hand poses are reliable for hand position but weak for orientation and gripper state. ACE-Ego-0 sets the channel-level weight to 1.0 for position and 0.001 for rotation and gripper, so human video trains the model on where to move while contributing almost nothing to how to orient or grasp. Removing this reliability-aware weighting costs 3.6 points on RoboCasa, the largest single ablation drop.
What data does ACE-Ego-0 train on?
A 6,013-hour mixed pool: 4,534+ hours of robot demonstrations (AgiBot Alpha/Beta 1,937h, Galaxea R1Lite, RoboCasa, Galbot self-collected 1,800h+) and 1,479 hours of human egocentric video (EgoDex 776.8h, Xperience-10M 435.7h, Ego4D, EgoExo4D, EPIC-KITCHENS-100, HOI4D). Human clips are converted to camera-space pseudo-actions before mixing.
Is the human-video idea here new compared with prior VLA work?
The use of human video for manipulation is not new, but the unification recipe is the contribution: a shared 22-D canonical action space, morphology tokens that condition the action expert without touching the backbone, time-aligned chunking, and per-channel reliability weighting. It builds on flow-matching action experts like pi-0 and the broader robotics line of VLA pretraining rather than introducing a new backbone.
One line: ACE-Ego-0 shows filtered human egocentric video is a usable position prior for VLA pretraining (+4.5 on RoboCasa, 78.3% real-robot average), but the gain depends on reliability-aware weighting that mutes the noisy rotation and gripper signal. Read the original paper on arXiv.