Vision-Language-Action · World Models · Robotics
WALL-WM: Event-Grounded World Action Modeling for Robots
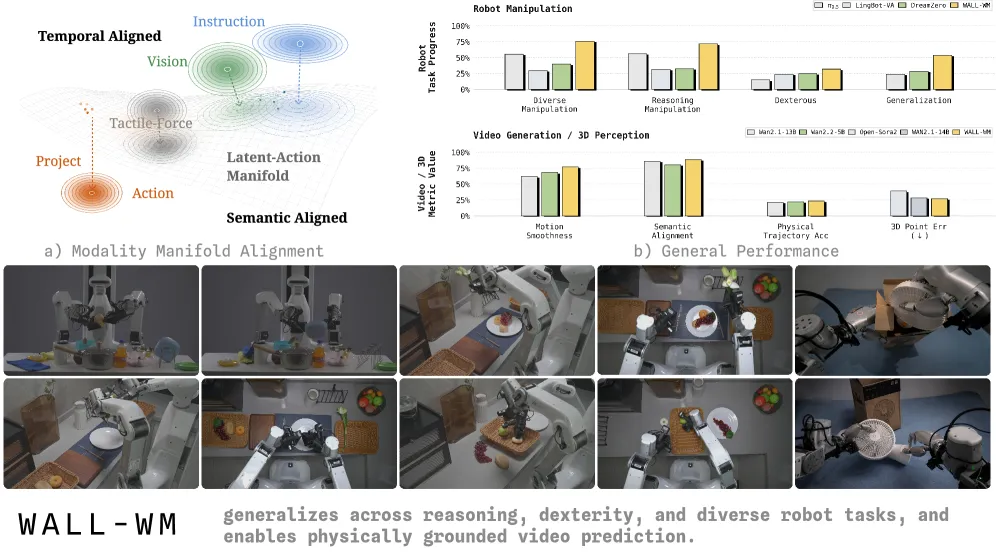
WALL-WM organizes VLA pretraining around semantic action events, not fixed-length chunks. Its event mode scores 75.86 Task Progress on diverse real-robot manipulation versus 55.64 for pi0.5.
Quick answer
WALL-WM is a World Action Model from X-Square-Robot that trains a vision-language-action policy on semantic action events rather than fixed-length action chunks. On real-robot diverse manipulation its event mode averages 75.86 Task Progress, against 55.64 for pi0.5, 39.97 for DreamZero, and 29.71 for LingBot-VA. The largest gap shows up in generalization: 53.75 for the event mode versus 18.50 for the same model trained as a fixed-length unified policy from scratch. The win comes from how supervision is sliced, not from a bigger backbone. Both modes share one event-pretrained denoiser.
The granularity mismatch WALL-WM targets
Most world action models start from a video or multimodal foundation model, then predict fixed-length action chunks from the current frame and instruction. The paper argues the chunk is the wrong unit. Language names goals and events. Vision moves through continuous scene dynamics. Actions run at control-rate timescales. Cramming all three into one fixed window turns VLA training into short-horizon correlation fitting, and that can overwrite the pretrained visual-semantic prior with chunk-specific shortcuts. WALL-WM instead cuts video, action, and caption at the same semantic event boundary, so a caption-to-video-action target is well posed.
How the event grounding works
The atomic unit is a semantically coherent action event. Data is built from event-level hierarchical captions across four tracks (task, subtask, action, segment) and sampled with cluster balancing so rare behaviors are not drowned out. The model is a layer-coupled video-action denoiser: given multi-view observation and a next-event instruction, it jointly denoises future video latents and end-effector action tokens. Cross-view attention uses a sight-cone mask so two view tokens attend only when their back-projected cones share 3D space in front of both cameras, which is the geometric prior that gives the model its multi-view consistency.
Two inference modes from one backbone
The same event-pretrained model runs two ways. Event mode consumes next-event descriptions and emits variable-length execution chunks, sized to the event rather than a clock. Unified mode keeps the conventional fixed-length chunk interface by adding a Qwen3.5-9B VLM with Staircase Decoding, a compact sequence of continuous latent reasoning states that conditions the action path while keeping gradients continuous. The reported numbers below separate these: WALL-WM-E is event mode, WALL-WM-U-Scratch is the unified interface trained from scratch without the event recipe.
Key results
- Diverse manipulation (Task Progress, real robot): event mode 75.86, U-Scratch 63.00, pi0.5 55.64, DreamZero 39.97, LingBot-VA 29.71.
- Reasoning manipulation: event mode 71.60 vs pi0.5 56.40 vs U-Scratch 59.50. The “Press Button in Order” task goes from 18 (base) to 64 (event).
- Dexterous manipulation: event mode 32.00 vs U-Scratch 31.25 vs LingBot-VA 24.00 vs pi0.5 15.00. The gap narrows here on contact-heavy insertion.
- Generalization (randomized instruction order, novel scene): event mode 53.75 vs DreamZero 28.50 vs pi0.5 24.00 vs U-Scratch 18.50. This is the widest margin and the headline.
- 3D awareness (CO3Dv2 probe): WALL-WM Point Err 0.271, Depth Err 0.132, AUC@5 0.210, all best in the table, ahead of the Wan2.1-14B backbone it inherits from (0.284 / 0.151 / 0.200).
Read these as recipe-level gains under a shared evaluation rubric, with Task Progress scored on a 10-point partial-credit scale normalized to 0-100. The event ablation is the cleanest signal: holding architecture fixed, event-mode supervision lifts reasoning manipulation from 32.6 to 71.6 and generalization from 22.0 to 53.75 against a fixed-length base.
What the numbers do not settle
The big margins concentrate where semantic structure helps: reasoning and generalization. On dexterous insertion the event mode barely clears the from-scratch unified baseline, 32.00 versus 31.25, so the recipe buys less when the bottleneck is contact precision rather than task decomposition. The comparison also leans on internal real-robot suites and the team’s own scoring rubrics, not a shared public leaderboard, so cross-paper comparison with pi0.5 or DreamZero is indicative rather than apples-to-apples. The paper reports no per-task compute or inference-latency budget for the dual-tower denoiser plus the VLM reasoning path.
Builder takeaway
If you run a chunk-centric VLA stack and your weak spot is long-horizon or compositional tasks, the event-boundary idea is the part worth porting: segment supervision at semantic events and let chunk length vary. The harder lift is the data ecosystem behind it, the four-level captions, cluster-balanced sampling, and the XRZero-G0 no-embodiment collection rig that supplies most of the volume. The unified mode plus Staircase Decoding lets you keep a fixed-length interface, but it adds a 9B VLM to the loop, so it is a heavier deployment than a plain action head.
Limits and open questions
No public training code beyond the GitHub repo is required to reproduce the numbers, and the paper gives no compute, wall-clock, or token budget for pretraining or inference. The evaluation uses internal manipulation suites with author-defined rubrics, so external validity rests on whether the rubric and scenes are released in enough detail to rebuild. Dexterous results are close to the unified baseline, leaving open whether event grounding helps contact-rich control at all. The data pipeline depends on a proprietary collection rig, which limits how easily another team can match the data scale even with the method in hand.
FAQ
What is WALL-WM?
WALL-WM is a World Action Model that pretrains a vision-language-action policy on semantic action events instead of fixed-length action chunks. It comes from X-Square-Robot and reaches 75.86 Task Progress on diverse real-robot manipulation versus 55.64 for pi0.5, with its widest margin on generalization (53.75 vs 18.50 for a from-scratch unified baseline).
How is WALL-WM different from chunk-centric VLA models?
Standard world action models predict fixed-length action chunks from the current observation, which forces language, vision, and control onto one window and reduces training to short-horizon correlation fitting. WALL-WM cuts video, action, and caption at the same semantic event boundary, so chunk length varies with the event and the pretrained visual-semantic prior is preserved rather than overwritten.
What are WALL-WM’s two inference modes?
Event mode reads a next-event description and produces variable-length execution chunks sized to the event. Unified mode keeps a conventional fixed-length chunk interface by adding a Qwen3.5-9B VLM with Staircase Decoding. Both run from the same event-pretrained backbone, so the difference is the interface, not a separate model.
Does WALL-WM beat the baseline because of pretraining or the inference mode?
The event ablation isolates the recipe. With architecture held fixed, event-mode supervision lifts reasoning manipulation from 32.6 to 71.6 and generalization from 22.0 to 53.75 against a fixed-length base, so the gain is attributed to event-grounded supervision rather than a larger backbone.
One line: WALL-WM slices VLA pretraining at semantic event boundaries instead of fixed chunks, which mostly helps reasoning and generalization while barely moving dexterous control. Read the original paper on arXiv.