LLM Reasoning · Fine-Tuning & Adaptation · Open Models
SU-01: Gold-Medal Olympiad Reasoning from a 30B Open Model
SU-01, a 30B-A3B open model from Shanghai AI Lab, hits 35 points on IMO 2025 and clears gold lines at IPhO 2024/2025 using only ~338K short SFT trajectories plus a 200-step two-stage RL pipeline.
Quick answer
SU-01, a 30B-A3B open model from Shanghai AI Laboratory, reaches gold-medal-level scores on both math and physics olympiads with a deliberately simple recipe. It scores 35 points on IMO 2025 (the gold-medal line) and exceeds the USAMO 2026 gold line by 10 points. With test-time scaling it clears the gold bar at both IPhO 2024 (25.3 vs 20.8) and IPhO 2025 (21.7 vs 19.7). The training pipeline is small by frontier standards: about 338K supervised trajectories under 8K tokens each, then a two-stage reinforcement-learning run of just 200 steps.
Why “simple and unified” is the actual claim
The headline isn’t that a model won a gold medal; closed labs have done that already. It’s that you can get there without an elaborate, modality-specific stack. SU-01 uses one backbone (P1-30B-A3B), one SFT stage, and one RL pipeline to cover both mathematics and physics, two domains usually treated with separate pipelines. The honest read: the contribution is engineering discipline rather than a new algorithm. There is no novel RL objective here. The paper’s value is showing how far a clean, reproducible scaling recipe goes on an open 30B-class model.
What’s in the SFT data
The supervised stage uses roughly 338K trajectories, and the composition matters more than the count. By the paper’s own breakdown it splits into direct-generation data (54.3%, covering math, STEM, code, and instruction-following) and self-improvement data (45.7%) made of self-verify and self-refine traces. Every kept response is shorter than 8K tokens. That constraint is the interesting design choice: rather than imitating sprawling chains of thought, SFT teaches compact reasoning and self-correction, and the long thinking is left for RL to grow.
The two-stage RL pipeline
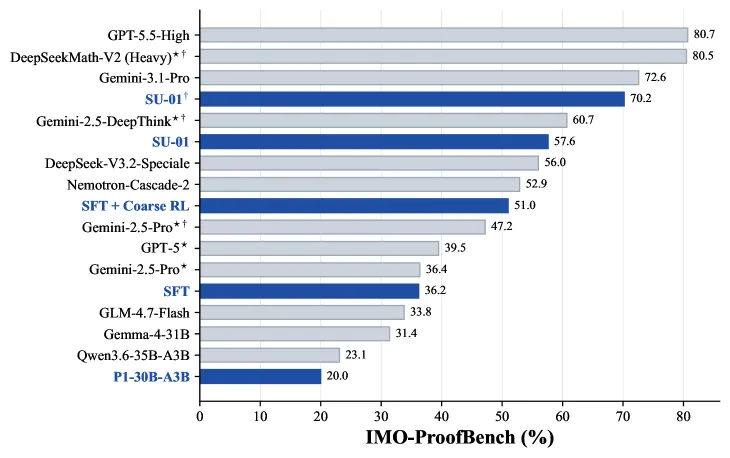
RL runs for 200 steps total, split into 96 coarse steps and 104 refined steps. The coarse stage scales reasoning on broad data; the refined stage tightens behavior on harder, curated problems. The payoff shows up in the ablation: plain SFT scores 36.2% on IMO-ProofBench, SFT plus coarse RL jumps to 51.0%, and the full SU-01 reaches 57.6% direct, or 70.2% with test-time scaling. The model is built to push trajectory length past 100K tokens at inference, which is where the test-time-scaling gains come from.
Key results
- IMO 2025: 35 points, exactly the gold-medal threshold.
- USAMO 2026: 35 points, 10 above the gold line.
- IPhO 2024: 25.3 points with test-time scaling, above the 20.8 gold line.
- IPhO 2025: 21.7 points with test-time scaling, above the 19.7 gold line.
- AIME 2025 / 2026: 94.6% / 93.3%.
- IMO-ProofBench: 57.6% direct, 70.2% with test-time scaling. On x3’s chart that 70.2 sits among Gemini-3.1-Pro (72.6) and ahead of several frontier systems.
- AMO-Bench: 59.8%; AnswerBench: 77.5%; FrontierScience-Olympiad: 62.5% overall.
Why this matters now
The result lands as the field debates whether olympiad-level reasoning requires frontier-scale closed models. SU-01 says no: a 30B-A3B backbone, ~338K short trajectories, and 200 RL steps get you to gold lines that until recently belonged to the largest proprietary systems. For anyone building reasoning models on a budget, the most useful takeaway is the data design. Short SFT traces plus self-verify/self-refine data, with length earned during RL rather than copied during SFT.
Limits and open questions
The gold-line claims rest on a small number of competition problems, so the variance is real. IPhO scores only clear the bar with test-time scaling, not in direct generation, and the IPhO 2025 margin (21.7 vs 19.7) is thin. “Gold-medal-level” describes a score threshold on these specific exams, not a guarantee against harder or differently styled problems. The paper also leans on a strong proof-grading benchmark (IMO-ProofBench), and automated proof scoring is itself contested. And “simple and unified” is relative: 100K-token trajectories and test-time scaling make inference expensive, so the cheap-to-train story does not automatically mean cheap-to-run.
FAQ
What is SU-01 and who built it?
SU-01 is a 30B-A3B reasoning model from Shanghai AI Laboratory (with collaborators at CUHK, Tsinghua, SJTU and Peking University) that reaches gold-medal-level scores on math and physics olympiads using a simple SFT-then-RL recipe on the P1-30B-A3B backbone.
How does SU-01 reach gold-medal-level olympiad reasoning?
SU-01 fine-tunes on ~338K supervised trajectories under 8K tokens, then runs a 200-step two-stage RL pipeline (96 coarse + 104 refined steps), and uses test-time scaling that extends trajectories past 100K tokens. That combination lifts IMO-ProofBench from 36.2% (SFT only) to 57.6% direct.
How does SU-01 score on IMO 2025 and IPhO?
SU-01 scores 35 points on IMO 2025 (the gold line) and, with test-time scaling, clears gold at IPhO 2024 (25.3 vs 20.8) and IPhO 2025 (21.7 vs 19.7). It also hits 94.6% on AIME 2025 and 93.3% on AIME 2026.
Is SU-01 cheaper to train than frontier reasoning models?
Yes on training: ~338K short trajectories and only 200 RL steps are modest versus frontier pipelines. But inference is not cheap. Its strongest results need test-time scaling with trajectories above 100K tokens, so serving cost stays high.
One line: a clean SFT-then-RL recipe on a 30B open model is enough for gold-medal olympiad scores, if you can afford 100K-token inference. Read the original paper on arXiv.