AI Agents · Agent Memory · LLM Reasoning · Reinforcement Learning
RHO: Retrospective Harness Optimization via Self-Preference
RHO tunes an LLM agent harness from past unlabeled trajectories using self-consistency and pairwise self-preference, lifting SWE-Bench Pro from 59% to 78% in one round with no external grading.
Quick answer
RHO improves an agent’s harness using only past trajectories, with no ground-truth labels. The harness is the layer of skills, tools, and instructions around a fixed model, here Codex. One optimization round lifts the SWE-Bench Pro held-out pass rate from 0.59 to 0.78, a 19-point absolute gain, without any external grading. The model never changes, so the gain is the harness the model now runs inside, not a stronger base model. It works by re-solving a hard subset of past tasks, diagnosing failures with self-validation and self-consistency, proposing several candidate harnesses, and keeping the one the agent prefers in pairwise comparison.
The problem: tuning a harness when you have no labels
Most harness optimizers steer their search with a labeled validation set. They propose an edit, grade candidates on held-out labels, and keep the highest-scoring one. In a real deployment you rarely have that set, and the labels you do collect may not match the distribution of future tasks. What you always have is a stream of past trajectories from tasks the agent already ran.
RHO turns those unlabeled trajectories into the optimization signal. The central bet: an agent’s own judgment over its rollouts is a usable proxy for quality when no grader exists. That is the part to separate from the base model. RHO does not make Codex smarter; it changes the skills and tools Codex has on hand and the order in which it uses them.
How RHO works without ground truth
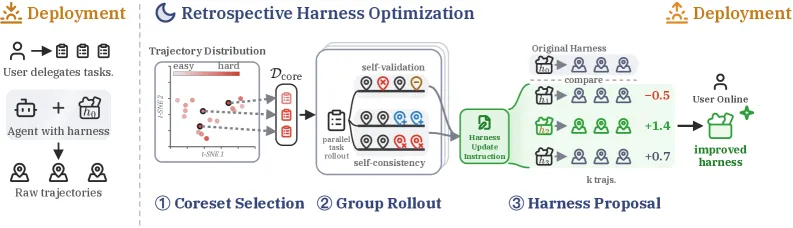
The pipeline has three stages.
Coreset selection picks a small, difficulty-diverse subset of past tasks with a determinantal point process (DPP). The DPP balances two pulls: pick hard tasks, but also spread them across the task space. Picking by difficulty alone makes the model cluster on one task type it judges hard; picking by coverage alone wastes budget on easy tasks. Only the combined DPP reaches the top gain, and in the paper’s analysis both difficulty-only and diversity-only selection trail even random sampling.
Group rollout re-solves each coreset task several times in parallel, then extracts two diagnostic signals. Self-validation looks within a single trajectory for the agent’s own checks that failed. Self-consistency looks across the parallel trajectories for disagreement on the same task. Neither needs a label; both are signals the agent can compute on itself.
Best-of-N harness proposal samples several candidate harnesses from those diagnoses, re-runs them on the coreset, and ranks each candidate’s new trajectory against the old one by pairwise self-preference. The most preferred harness ships. Sampling several and filtering matters because a single proposal is stochastic and can fail to improve anything.
What the optimized harness actually contains
The harness is a directory of markdown instructions, skills, and executable tool scripts. RHO adds new entries that target failure modes the original trajectories kept hitting. On SWE-Bench Pro the agent learns the Go toolchain sits outside the default path, and that Python cache directories must be stripped before producing a diff or patches fail to apply. It writes a check_build_and_lint tool that locates the off-path toolchain and flags artifacts to keep out of the patch. These are concrete, debuggable fixes, not abstract prompt tweaks.
Key results
- SWE-Bench Pro, one round: Vanilla Codex 0.59 to RHO 0.78 (+19 points), with no external grading.
- Versus feedback-free baselines (Table 1): RHO 0.78 vs Dynamic Cheatsheet 0.62, ReasoningBank 0.61, Sleep-time Compute 0.64 on SWE-Bench Pro, at a matched agent-call budget. RHO also wins on Terminal-Bench 2 (0.76 vs 0.71 vanilla) and GAIA-2 (0.37 vs 0.29 vanilla). Baselines edit only memory or text skills; RHO edits skills and tools.
- Versus Meta-Harness, a label-using optimizer (Table 2): at a matched single-round budget Meta-Harness reaches only 0.62 on SWE-Bench Pro versus RHO’s 0.78. Pushed to 10 rounds and roughly 3x the compute, Meta-Harness reaches 0.80, still depending on held-out labels RHO never touches.
- Diagnosis ablation (Table 4): dropping self-consistency collapses SWE-Bench Pro to 0.56, below the 0.59 vanilla baseline; dropping self-validation gives 0.70; feeding raw trajectories with no diagnosis gives 0.60. Both diagnostic signals are load-bearing, and self-consistency is the bigger one on SWE-Bench Pro.
- Best-of-N consistency (Table 3): across three candidate harnesses on SWE-Bench Pro the mean held-out score is 0.79 and the lowest is 0.73, so even the worst candidate beats vanilla. The chosen candidate (0.78) is not always the single highest scorer, but selection reliably avoids the worst.
Why the self-preference signal holds up
The honest read of the ablation: self-consistency is doing most of the work, and removing it drops performance below the untouched baseline. That tells you the signal is real, not a free lunch. When the agent re-solves a hard task several times and the rollouts disagree, that disagreement localizes where the harness is weak, even with no answer key. Self-preference then filters proposals so a bad harness edit does not ship. The behavior analysis backs this: after RHO the agent verifies its work more often on SWE-Bench Pro and sustains higher accuracy on long-horizon sessions, which is where most of the gain concentrates.
Limits and open questions
The 0.59-to-0.78 headline is one round on one benchmark with a fixed Codex agent; gains on Terminal-Bench 2 (+5 points) and GAIA-2 (+8 points) are real but much smaller, so SWE-Bench Pro is the favorable case, not the typical one. Self-preference is the agent grading itself, which risks rewarding harness edits the model likes rather than edits that generalize; the chosen candidate already does not always match the true top scorer in Table 3. The compute is not free: one RHO run costs 103 agent calls versus 41 for single-round Meta-Harness, so RHO buys label-free operation by spending more inference. And the whole method assumes the base model is competent enough that its self-consistency carries signal; on a weaker model where rollouts disagree for the wrong reasons, the diagnosis could mislead. The paper does not test that boundary.
FAQ
What is RHO (Retrospective Harness Optimization)?
RHO is a self-supervised method that improves an LLM agent’s harness, meaning its skills, tools, and instructions, using only past unlabeled trajectories. It selects a hard, diverse coreset of past tasks, diagnoses failures with self-validation and self-consistency, proposes candidate harnesses, and ships the one the agent prefers in pairwise comparison. One round raised SWE-Bench Pro pass rate from 0.59 to 0.78.
Does RHO need ground-truth labels to improve a harness?
No. That is its whole point. RHO replaces the labeled validation set with the agent’s own diagnostic signals over its rollouts and pairwise self-preference. The SWE-Bench Pro jump to 0.78 happens without any external grading, while the label-using comparator Meta-Harness needs held-out labels to reach a comparable ceiling.
Does RHO make the base model smarter?
No. The model is a fixed Codex agent throughout. RHO only edits the surrounding harness: it adds tools like check_build_and_lint and skills targeting past failure modes. The 0.59-to-0.78 gain is attributable to the new harness, not new pretraining or a larger model.
How does RHO compare to Meta-Harness on validation-feedback agent calls?
At a matched single-round budget, Meta-Harness reaches 0.62 on SWE-Bench Pro versus RHO’s 0.78, and it consumes about 41 agent calls versus RHO’s 103. At 10 rounds and roughly 3x the compute Meta-Harness reaches 0.80, but it still requires held-out labels that RHO does not use.
What happens if RHO drops self-consistency?
SWE-Bench Pro falls to 0.56, below the 0.59 vanilla baseline, so removing self-consistency makes the optimization actively harmful there. Dropping self-validation gives 0.70 and feeding raw trajectories with no diagnosis gives 0.60. Both diagnostic signals are essential, not incidental.
One line: RHO tunes an agent harness from unlabeled past trajectories using self-consistency and self-preference, buying label-free operation with extra inference. Read the original paper on arXiv.