Diffusion Models · Efficient AI
AnyFlow: Any-Step Video Diffusion via Flow Map Distillation
AnyFlow distills a video diffusion model that keeps improving as you add sampling steps, fixing the quality drop consistency-distilled models suffer at higher step counts. Tested on Wan2.1 from 1.3B to 14B.
Quick answer
AnyFlow is the first video diffusion distillation framework whose quality keeps rising as you spend more sampling steps, instead of plateauing or degrading. Consistency-distilled video models look great at 4 steps but get worse when you give them 16 or 32. AnyFlow removes that ceiling by distilling the entire ODE trajectory, not a single few-step shortcut. NVIDIA validates it on Wan2.1 across 1.3B and 14B parameters, in both bidirectional and causal (autoregressive) setups.
The problem consistency distillation created
Few-step video generation today mostly runs on consistency distillation: train a fast model that jumps from noise to a clean video in a handful of steps. The catch the paper isolates is counterintuitive: these models do not benefit from more compute. Allocate more sampling steps and quality often drops. That breaks the one property practitioners expect from diffusion: test-time scaling, where more steps buy more fidelity.
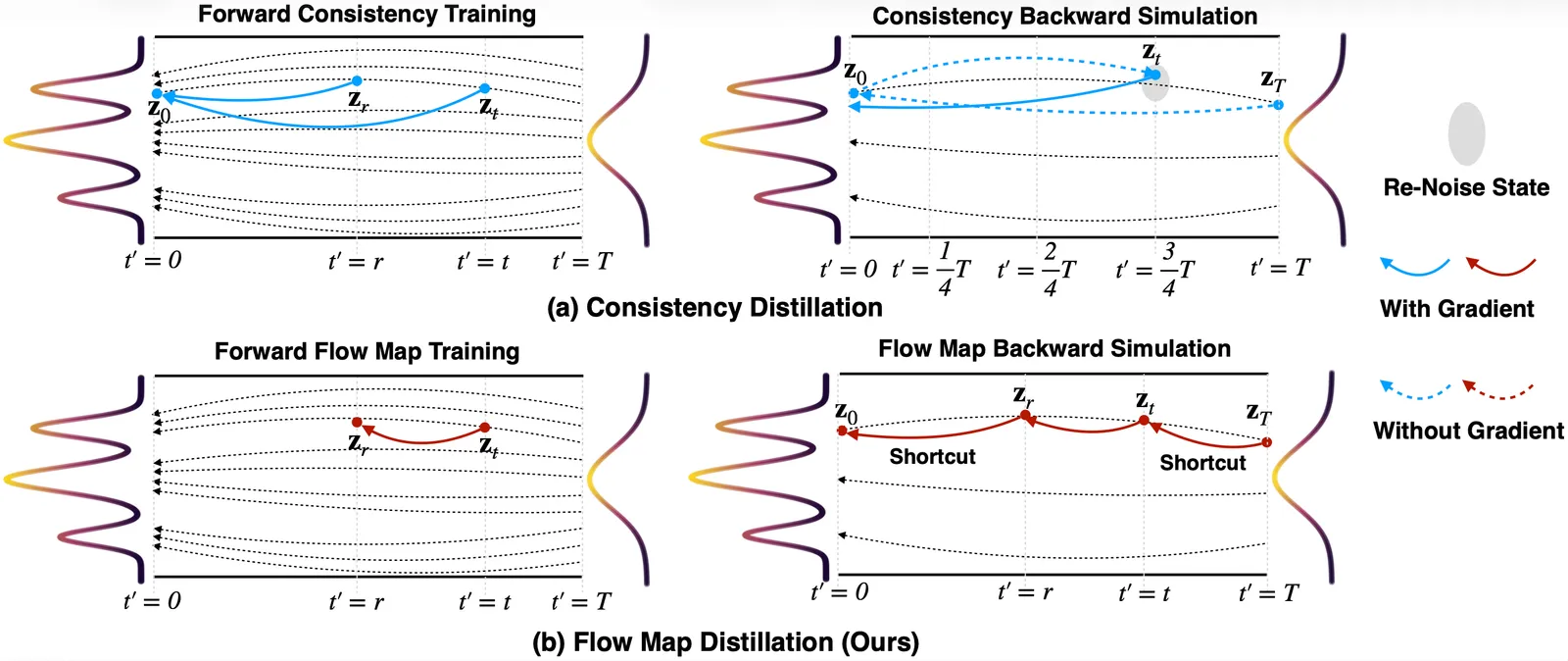
The root cause AnyFlow names is that consistency distillation replaces the original probability-flow ODE trajectory with a separate consistency-sampling trajectory. The model learns to land on the endpoint, not to follow the path. Once you ask it to take intermediate steps along a path it never learned, the extra steps add error instead of detail.
How AnyFlow works
The core move is changing what gets distilled. Consistency methods learn an endpoint map, from a noised latent z_t straight to the clean z_0. AnyFlow instead learns a flow map: the transition from z_t to z_r for arbitrary time intervals along the real ODE trajectory. Because the model now knows how to move between any two points on the path, you can chain any number of steps and each one is on-trajectory, so more steps genuinely help.
Training that flow map directly is expensive, so the paper introduces Flow Map Backward Simulation. It decomposes a full Euler rollout (the many-step ground-truth integration) into shortcut flow-map transitions, which makes the distillation on-policy: the student is supervised on the states it will actually visit at inference. That on-policy supervision is what targets the two failure modes the paper calls out by name: discretization error in few-step sampling, and exposure bias in causal generation, where small per-frame errors compound across an autoregressive rollout.
Why the bidirectional-and-causal coverage matters
Most distillation papers pick one architecture. AnyFlow reports results for both bidirectional diffusion (the standard full-clip generator) and causal/autoregressive generation (frame-by-frame, the setup that enables streaming and real-time video). Exposure bias is specifically a causal-generation disease, so showing the same flow-map recipe helps there is the more interesting half of the claim. It suggests the method is not just a few-step trick but a fix for compounding error in long rollouts.
Key results
- Tested scale: Wan2.1-based models from 1.3B to 14B parameters, the paper’s headline range, covering both bidirectional and causal architectures.
- Test-time scaling restored: AnyFlow’s quality rises across the sampling-step budget (the project page shows comparisons at 4, 16, and 32 NFEs), whereas consistency-distilled baselines degrade as steps increase past their tuned few-step regime.
- Few-step parity: in the few-step regime AnyFlow matches or surpasses consistency-based counterparts, so it does not trade away the cheap-fast operating point to gain the scaling behavior.
- Causal stability: the on-policy flow-map supervision is positioned to cut exposure bias in autoregressive video, the regime where per-frame errors otherwise accumulate.
A candid caveat on these numbers: the abstract and project page report the shape of the results (matches-or-surpasses, scales-with-steps, the 1.3B-14B range, the 4/16/32-NFE comparison) but do not publish a single headline VBench or FVD figure in the material available here. Treat the scaling claim as qualitatively verified and the exact magnitudes as pending the full paper.
Why it matters now
Real-time and streaming video generation is the current frontier, and it lives or dies on the step-count-versus-quality tradeoff. The field had quietly accepted that fast distilled video models cap out: you pick your step count at train time and that is it. AnyFlow argues that ceiling was an artifact of how we distilled, not a law, and restores the diffusion property of “spend more compute, get more quality” inside a fast model. Built on Wan2.1, an open and widely used video base, the recipe is directly relevant to anyone shipping few-step or real-time video.
Limits and open questions
The biggest gap is hard numbers: without published VBench/FVD scores in the available material, the “matches or surpasses” claim is directional rather than quantified, and reproduction will depend on the full paper and code release. The method is demonstrated only on the Wan2.1 family, so transfer to other video backbones (or to image diffusion) is assumed, not shown. Flow Map Backward Simulation adds training complexity over plain consistency distillation, since the on-policy rollout decomposition is more machinery to get right, and the paper does not, in the abstract, quantify that training cost. Finally, “any-step” is a strong word: the evidence covers a 4-to-32-step window, not an unbounded budget, so how far the scaling actually extends is open.
FAQ
What is AnyFlow in one sentence?
AnyFlow is NVIDIA’s video diffusion distillation framework that learns flow-map transitions over arbitrary time intervals, so the distilled model keeps improving as you add sampling steps instead of degrading like consistency-distilled models.
Why do consistency-distilled video models get worse with more steps, and how does AnyFlow fix it?
Consistency distillation trains the model to jump to the endpoint along a special consistency trajectory, not the real ODE path, so intermediate steps go off-trajectory and add error. AnyFlow distills the actual flow map between any two points on the ODE path, keeping every extra step on-trajectory.
What is Flow Map Backward Simulation in AnyFlow?
It decomposes a full many-step Euler rollout into shortcut flow-map transitions, enabling on-policy distillation that supervises the student on the states it will actually visit at inference, reducing few-step discretization error and causal-generation exposure bias.
What models and scales does AnyFlow test?
AnyFlow is validated on Wan2.1-based models from 1.3B to 14B parameters, in both bidirectional and causal (autoregressive) architectures.
Does AnyFlow publish benchmark scores?
The abstract and project page state it matches or surpasses consistency-based models in the few-step regime and scales with sampling steps (shown at 4, 16, and 32 NFEs), but no single VBench or FVD number is reported in the material available here.
One line: distill the whole path, not the endpoint, and a fast video model can spend more steps for more quality again. Read the original paper on arXiv.