Video Generation · Diffusion Models · Speech Synthesis
Lip Forcing: Few-Step Autoregressive Diffusion for Real-time Lip Sync
First autoregressive-diffusion lip-sync method: distills a 14B bidirectional teacher into causal 1.3B/14B students that generate each chunk in 2 steps, hitting 31.58 FPS with sub-millisecond time-to-first-frame.
Quick answer
Lip Forcing makes diffusion-based lip sync run in real time by turning a slow bidirectional video-diffusion model into a causal, chunk-by-chunk generator. Its 1.3B student runs at 31.58 FPS with a 0.32ms time-to-first-frame on HDTF, using only two denoising steps per chunk and no classifier-free guidance at inference. That is 17.6x faster than the same-scale bidirectional model it distills from; the 14B student is 39.8x faster than its teacher and 4.7x faster than LatentSync. The catch is sync quality: at 1.3B it reaches Sync-C 6.88 against LatentSync’s 8.10 and ground truth’s 7.95, so it trades some lip-audio alignment for streaming speed.
What problem the speed solves
Most strong lip-sync diffusion models process a whole clip bidirectionally before emitting a frame. That gives good mouth-audio alignment but kills latency: OmniAvatar-LS (14B) in the paper’s own table runs at 0.38 FPS with a 213.72ms time-to-first-frame, and LatentSync sits at 3.23 FPS. Neither can drive a live avatar. Lip Forcing borrows the autoregressive-distillation recipe that few-step video models like Causal Forcing use for text-to-video, and applies it to the video-to-video lip-sync setting: the model conditions each new chunk on already-generated frames and the audio, so it can stream output instead of waiting for the full sequence.
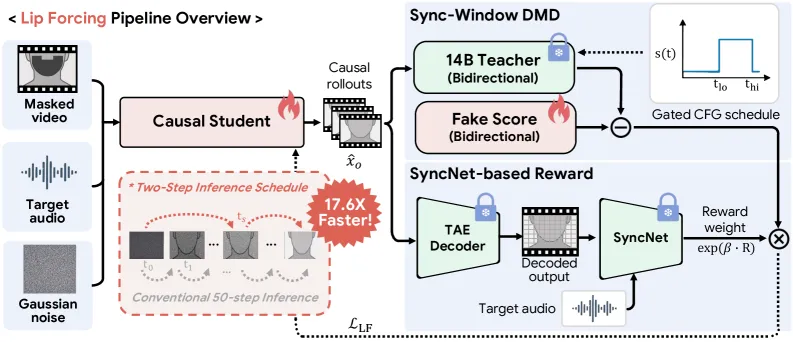
How the distillation works
The teacher is a 14B audio-conditioned bidirectional video-diffusion model. Lip Forcing distills it into causal students with Distribution Matching Distillation (DMD), the same family that powers few-step generators like AnyFlow, plus a fake-score critic. Three pieces make the 2-step version actually usable:
- Two-step inference schedule. Students denoise at exactly two ODE indices, (0, 30). The team derived the landing point at step 30 from an Euler-step analysis: it balances how much of the reference identity survives against how well the mouth tracks the audio. A naive one-step student visibly underperforms a 50-step run, which is why they keep a second step rather than going fully one-shot.
- Sync-Window DMD. Instead of a fixed CFG scale, the teacher applies guidance scale 4.5 only inside ODE steps 20-40 and scale 1.0 (no guidance) elsewhere. The band 20-40 is where the trajectory analysis found generation is most responsive to audio.
- SyncNet reward. A per-sample multiplicative weight
w = exp(beta * R)(beta=2) scales the DMD gradient by the SyncNet confidence between the generated mouth and the conditioning audio, so well-synced samples pull harder on training. Gradients flow only through the DMD loss, not back through the reward.
The CFG fidelity-sync tradeoff
The non-obvious finding is that classifier-free guidance does not have one good setting here. Turning CFG up (scale 4.5) raises Sync-C, the lip-audio match, but it degrades reference fidelity: the generated face drifts from the source identity and the mouth region gets noisier (higher LPIPS). Turning CFG off (scale 1.0) keeps the face faithful but loosens the audio sync. No single fixed scale the authors tested wins on both. Their fix is to stop treating CFG as a global dial and gate it by denoising step: keep guidance off early to protect identity, switch it on in the mid-trajectory band where it buys the most sync, then off again. That windowed view is the conceptual core, and it is also why the students can drop inference-time CFG entirely once the behavior is baked into the distilled weights.
Key results
All numbers on the 33-clip HDTF test set. Ground truth reference: Sync-C 7.95, Sync-D 6.92.
- 1.3B student: 31.58 FPS, 0.32ms TTFF, Sync-C 6.88, Sync-D 7.93, FVD 118.86, FID 6.76. Real-time and the best FID-throughput Pareto point, but its Sync-C trails the bidirectional baselines.
- 14B student: 15.11 FPS, 0.54ms TTFF, Sync-C 7.59, Sync-D 7.23, FVD 107.88, FID 7.01. Closes most of the sync gap (Sync-C 7.59 vs ground truth 7.95) while still running ~40x its teacher.
- vs LatentSync: LatentSync gets Sync-C 8.10 but only 3.23 FPS and FID 6.90. Lip Forcing 14B is 4.7x faster at FID 7.01, giving up about 0.5 Sync-C for an order-of-magnitude latency win.
- vs MuseTalk: MuseTalk runs 23.07 FPS, Sync-C 7.94, but FID 9.68 — Lip Forcing’s 1.3B beats it on FID (6.76) and speed while sitting below it on Sync-C.
- vs Wav2Lip: Wav2Lip is fastest at 479.60 FPS and highest Sync-C 8.56, but its FID is 24.15 and FVD 384.82, i.e. visually poor. Lip Forcing’s pitch is photorealism at streaming speed, not raw sync.
- Speedups: 1.3B is 17.6x faster than its same-scale bidirectional model; 14B is 39.8x faster than the teacher and 4.7x faster than LatentSync.
Limits and open questions
The headline 31 FPS is the 1.3B model, and that is the model with the weakest Sync-C (6.88, below every bidirectional baseline and below ground truth). If you need top sync quality you take the 14B student at 15.11 FPS, so “real-time” and “best sync” are not the same checkpoint. Evaluation is a 33-clip HDTF set, which is clean, frontal, English-leaning data; the table has no in-the-wild, multilingual, or profile-view stress test, even though VoxCeleb2 is in the training mix. Wav2Lip still beats it on the raw sync metric, so SyncNet-based Sync-C is partly gamed by older GAN methods that look bad but score high, which complicates the comparison. The paper reports no user study on perceived naturalness in the excerpted tables, and the concrete limitations live in an appendix rather than the main results. Reproducing the two-step schedule and Sync-Window band depends on details (the step-30 landing, the 20-40 CFG window, beta=2) that are tied to this teacher and dataset and may not transfer unchanged.
FAQ
What is Lip Forcing and how is it different from LatentSync or MuseTalk?
Lip Forcing is the first autoregressive-diffusion method for video-to-video lip sync, from KAIST AI with AIPARK. Where LatentSync and MuseTalk process clips bidirectionally, Lip Forcing distills a 14B bidirectional teacher into causal students that generate each chunk in two denoising steps and stream output. The result is 31.58 FPS at 1.3B versus 3.23 FPS for LatentSync, trading some Sync-C (6.88 vs 8.10) for real-time latency.
How does Lip Forcing reach 31 FPS with only two denoising steps?
It distills a slow multi-step bidirectional teacher into a causal student using Distribution Matching Distillation, then runs inference at just two ODE steps, indices (0, 30), with no classifier-free guidance at runtime. The 1.3B student hits 31.58 FPS and a 0.32ms time-to-first-frame on HDTF, 17.6x faster than the same-scale bidirectional model it came from.
What is the CFG fidelity-sync tradeoff in Lip Forcing?
Higher classifier-free guidance (scale 4.5) improves lip-audio sync but hurts how faithfully the generated face matches the reference; lower guidance (scale 1.0) keeps the face faithful but loosens sync. No fixed scale wins on both. Lip Forcing’s Sync-Window DMD gates guidance by denoising step, applying it only in the responsive 20-40 band, so the distilled students need no inference-time CFG at all.
Does Lip Forcing match its teacher’s sync quality?
Close at the 14B scale, not at 1.3B. The 14B student reaches Sync-C 7.59 (ground truth is 7.95) while running 39.8x faster than the teacher. The 1.3B student trades more sync (Sync-C 6.88) for the full 31.58 FPS streaming speed, so the fastest configuration is not the highest-fidelity one.
Bottom line: Lip Forcing shows audio-conditioned lip sync can stream at 31 FPS by distilling a bidirectional teacher into a 2-step causal student, but the fastest 1.3B model gives up real sync quality (6.88 Sync-C vs 8.10 for LatentSync) to do it. Read the original paper on arXiv.