Interpretability · Language Models
Gemma Scope: DeepMind's Open SAE Suite for Interpreting Gemma 2
Gemma Scope is a free, open suite of JumpReLU sparse autoencoders covering every layer of Gemma 2 2B and 9B (plus parts of 27B) — over 400 SAEs and 30M+ features, costing more than 20% of GPT-3's compute to train.
Quick answer
Gemma Scope is an open suite of more than 400 JumpReLU sparse autoencoders (SAEs) trained on every layer and sub-layer of Gemma 2 2B and 9B, plus select layers of 27B — yielding over 30 million learned features and more than 2,000 downloadable weight checkpoints. DeepMind spent over 20% of GPT-3’s training compute and saved roughly 20 PiB of activations to disk to produce it, then released everything free so that interpretability and safety research no longer requires training your own SAEs from scratch.
Why a free SAE suite is the actual contribution
The research result here is not a new method — it is removing a cost wall. A sparse autoencoder decomposes a model’s internal activations into a large, sparse set of features that are often human-interpretable, which is the leading current approach to reverse-engineering what a language model is “thinking.” The catch is that training a comprehensive set of them is brutally expensive: you need to capture activations at every layer, store petabytes of them, and run a large training job per site. That price tag had effectively confined mechanistic interpretability on real frontier-scale models to a handful of industry labs.
Gemma Scope pays that bill once and gives the artifacts away. Anyone can now load an SAE for layer 20 of Gemma 2 9B and start inspecting features without owning a GPU cluster — which is the whole point.
What “everywhere all at once” actually covers
The suite is comprehensive in three dimensions that prior open releases were not.
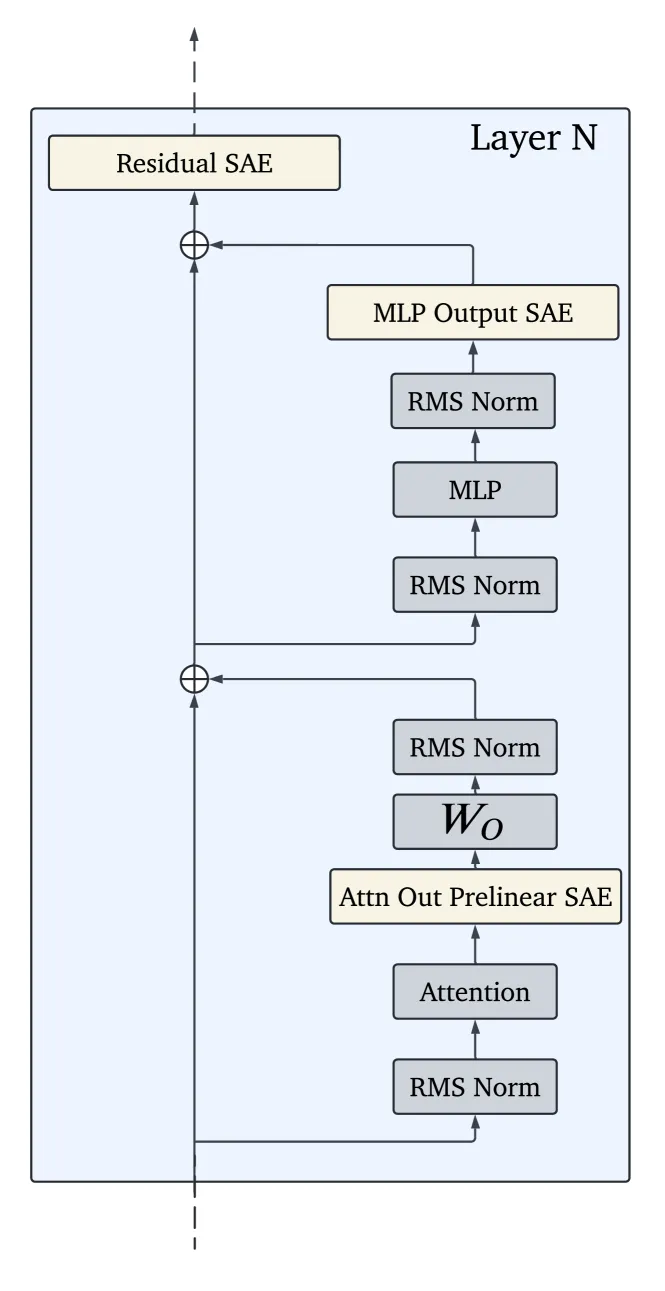
- Every site, every layer. For each transformer block, SAEs are trained on three locations: attention head outputs (pre-final-projection), MLP outputs, and the post-MLP residual stream. This spans all 26 layers of 2B and all 42 layers of 9B.
- Multiple widths. Dictionaries range from 2^14 (~16K) up to 2^20 (~1M) latents, so you can trade resolution against compute for your own analysis.
- Base and instruction-tuned. SAEs are primarily trained on pre-trained models, but DeepMind also released SAEs on instruction-tuned Gemma 2 9B for direct comparison.
The headline figures: 400+ primary SAEs, 2,000+ released checkpoints, 30M+ features, each SAE trained on 4-16B tokens.
Why JumpReLU, not TopK
Gemma Scope uses JumpReLU SAEs — a learnable per-feature threshold (a shifted Heaviside gate) combined with a ReLU, so a feature only activates when its pre-activation clears its own threshold. DeepMind chose it for two practical reasons. First, JumpReLU SAEs sit on a slight Pareto improvement over Gated and TopK SAEs on the reconstruction-vs-sparsity frontier. Second, unlike TopK — which forces exactly k active features per token — JumpReLU lets the number of active features vary by token, which is more faithful to how information is actually distributed. The honest footnote: on interpretability scored by human raters, JumpReLU, TopK, and Gated SAEs were nearly indistinguishable, so the win is on the fidelity metric, not interpretability.
Key results
- Residual stream is the hard site. Delta loss (the extra cross-entropy from splicing the SAE into the model) is consistently highest for residual-stream SAEs — small reconstruction errors there hurt downstream predictions the most.
- Width buys fidelity. Widening from 2^14 to 2^19 latents reliably lowers delta loss at fixed sparsity, but with diminishing returns and no guarantee the extra capacity learns genuinely new features.
- Base SAEs transfer to the chat model. SAEs trained only on base-model activations reconstruct instruction-tuned Gemma 2 9B activations almost as well as SAEs trained on the IT model directly — a useful, non-obvious result.
- bfloat16 is free. Switching inference from float32 to bfloat16 has negligible impact on SAE fidelity.
- Worst on multilingual text. Delta loss is lowest on math (DeepMind Mathematics) and highest on multilingual data (Europarl), reflecting the English-heavy pretraining mix.
Limits and open questions
The biggest caveat is in the foundation, not the engineering: there is still no consensus metric for whether an SAE is “good.” Delta loss and fraction-of-variance-unexplained measure reconstruction, not interpretability, and the paper is candid that the two can diverge. Feature splitting is unresolved — wider SAEs sometimes learn genuinely new features and sometimes just recombine existing ones, with no clean way to tell which. Transcoders, which worked on GPT-2 Small, underperformed plain MLP SAEs on Gemma 2, so prior findings did not transfer. And SAEs systematically miss features that only appear in wider dictionaries, meaning no single SAE gives a complete picture. Gemma Scope is a platform for interpretability research, not a finished interpretation of Gemma 2 — the hard scientific questions are exactly the ones it hands to the community.
FAQ
What is Gemma Scope?
Gemma Scope is DeepMind’s open suite of 400+ JumpReLU sparse autoencoders trained on Gemma 2 2B and 9B (and select 27B layers), released free so researchers can interpret Gemma 2’s internal features without training their own SAEs.
How much did Gemma Scope cost to train?
DeepMind used more than 20% of GPT-3’s training compute and saved roughly 20 PiB of activations to disk, producing hundreds of billions of SAE parameters — a cost wall the release removes for everyone else.
What is a JumpReLU sparse autoencoder?
A JumpReLU SAE applies a learnable per-feature threshold (a shifted Heaviside gate) plus a ReLU, so each feature fires only when its pre-activation exceeds its own threshold. It lets the active-feature count vary per token, unlike TopK SAEs which fix it at k.
Where can I download Gemma Scope SAEs?
The weights are on Hugging Face with an interactive feature browser on Neuronpedia. You can load an SAE for any layer and sub-layer (attention, MLP, or residual stream) at widths from ~16K to ~1M features.
Does Gemma Scope work on the instruction-tuned model?
Yes. SAEs trained on base Gemma 2 9B reconstruct instruction-tuned 9B activations almost as faithfully as SAEs trained directly on the IT model, so base-model SAEs transfer to the chat model.
One line: DeepMind paid the petabyte-scale SAE bill once and open-sourced the result, turning frontier-model interpretability into something a single researcher can do. Read the original paper on arXiv.