Interpretability · Language Models
Sparse Autoencoders Find Interpretable Features in LLMs
Training a sparse autoencoder on a language model's activations pulls apart 'superposition' into single-meaning features more interpretable than neurons — and lets you edit one concept and watch behavior change.
Quick answer
A neuron inside a language model usually fires for many unrelated concepts at once — a problem called superposition that makes neurons nearly impossible to read. This paper trains a sparse autoencoder (SAE) on the model’s internal activations and recovers a much larger set of features, most of which fire for a single, human-nameable concept. Across blind human and automated scoring, SAE features score as more monosemantic and interpretable than the model’s own neurons, PCA directions, or other baselines, and the authors causally localize the indirect-object-identification (IOI) behavior to a finer set of features than any prior decomposition.
The polysemanticity problem this attacks
The honest reason mechanistic interpretability stalled for years: individual neurons rarely mean one thing. A single neuron lights up for French text, DNA sequences, and HTTP requests — there is no clean concept to attach to it. The leading explanation is superposition: a model with d neurons wants to represent far more than d features, so it packs them into overlapping, non-orthogonal directions and tolerates a little interference. If that’s true, the unit of computation isn’t the neuron at all, and reading neurons one by one is the wrong move.
The bet here is that the real features are sparse — only a handful are active for any given token — and live in an overcomplete basis with more directions than there are neurons. That reframing is what makes a sparse autoencoder the natural tool.
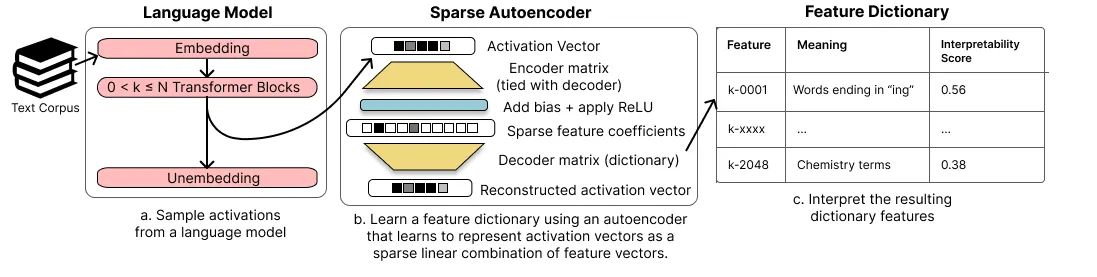
How the sparse autoencoder works
The SAE is deliberately simple: a single hidden layer, wider than the model dimension, trained only to reconstruct the activation vector while an L1 penalty forces the hidden code to be sparse. The encoder maps an activation into a high-dimensional, mostly-zero code; the decoder’s columns become a learned dictionary of feature directions. Because almost all entries are zero on any input, each surviving entry is forced to carry a specific, reusable meaning instead of a smear of many.
Two design points matter. The dictionary is overcomplete — more features than neurons — which is exactly what you need if superposition is real. And the only supervision is reconstruction plus sparsity; nobody labels features in advance. The interpretable structure is discovered, not imposed. This is classic dictionary learning, applied to transformer activations rather than image patches.
Key results
- Interpretability beats the baselines. Under both blind human raters and an automated GPT-based scoring protocol (autointerpretation), SAE features are rated more interpretable than individual neurons, PCA/ICA components, and the raw residual-stream basis.
- Causal, not just correlational. On the indirect object identification task, the authors pinpoint the specific features causally responsible for the counterfactual behavior — and to a finer granularity than previous decompositions of that circuit. Editing those features changes the model’s output in the predicted direction.
- Concrete single-meaning features. Recovered features include things as crisp as an apostrophe-context feature and a closing-parenthesis feature — concepts you can name in a few words, which is the whole point.
- A real knob: the sparsity/fidelity trade-off. Push sparsity harder and features get cleaner but reconstruction degrades; relax it and you recover more of the activation but features blur back together. There is no single “correct” dictionary size — it’s a tuning axis.
Why this paper matters now
This is one of the works that turned SAEs from a niche idea into the default first tool for opening up a language model. Within roughly a year, frontier labs scaled the exact recipe to production models — Anthropic’s “Scaling Monosemanticity” on Claude 3 Sonnet and OpenAI’s SAE work both trace their lineage here. If you’ve seen the demos where someone amplifies a “Golden Gate Bridge” feature and the model won’t stop talking about it, the mechanism is the dictionary learned by a sparse autoencoder. This paper is the compact, reproducible early demonstration that the approach works on real LMs.
Limits and open questions
The result is encouraging, not solved. Interpretability is measured, not guaranteed: scores improve over baselines, but plenty of features remain murky, and “more interpretable than a neuron” is a low bar. The sparsity penalty leaves dead and duplicated features, and choosing the dictionary width and L1 weight is still partly art — later work spent significant effort on exactly these failure modes (dead latents, shrinkage from L1). Reconstruction is imperfect, so an SAE is a lossy lens on the model, not a faithful rewrite of it; whatever it drops is invisible to your analysis. And the experiments here are on small models — the paper demonstrates the principle, while the question of whether every important computation decomposes this cleanly at frontier scale was left to the labs that followed.
FAQ
What does “Sparse Autoencoders Find Highly Interpretable Features” actually claim?
That training a sparse, overcomplete autoencoder to reconstruct a language model’s activations yields features that fire for single human-nameable concepts — and that these features are measurably more interpretable than the model’s neurons or PCA directions, with at least one circuit (IOI) localized causally.
Why use a sparse autoencoder instead of just reading neurons?
Because neurons are polysemantic: one neuron fires for many unrelated concepts due to superposition. The SAE’s overcomplete dictionary unpacks those overlapping directions into separate, mostly single-meaning features, so each unit you inspect carries one concept.
What is superposition in neural networks?
Superposition is when a model represents more features than it has neurons by storing them as overlapping, non-orthogonal directions and tolerating small interference. It’s the main reason individual neurons are hard to interpret, and the assumption that makes an overcomplete SAE the right tool.
How is this different from Anthropic’s “Scaling Monosemanticity”?
Same core method — a sparse autoencoder learning a feature dictionary from activations. This 2023 paper is the earlier, smaller-scale demonstration with causal IOI evidence; Anthropic’s 2024 work scaled the identical recipe to a production model (Claude 3 Sonnet) and found millions of features.
One line: train a sparse autoencoder on the activations and the model’s tangled neurons resolve into single-meaning, editable features. Read the original paper on arXiv.