Multimodal Models · Long Context
MemDreamer: Hierarchical Graph Memory for Long Video Understanding
MemDreamer turns hours-long video QA into agentic retrieval over a 3-tier graph memory, lifting LVBench from 78.2 to 90.7 (+12.5) while the reasoning model reads ~6K tokens instead of 240K-784K.
Quick answer
MemDreamer is a training-free framework that stops a VLM from reading a whole long video at once. A perception model streams the video into a three-tier graph memory (Video Root, Super Events, Macro Events with entity/micro-event subgraphs), and a separate reasoning model answers questions by calling seven retrieval tools over that text memory in an Observation-Reason-Action loop. On LVBench it scores 90.7 against 78.2 for the same Gemini-3.1-Pro run end-to-end, a 12.5-point gain, and lands 3.7 points behind human experts. The reasoning model sees only ~5.9K-6.3K tokens per run instead of the 240K-784K an end-to-end VLM ingests, roughly a 40x cut. The win is owned by the memory and retrieval scaffolding, not by a bigger or newly trained model.
Why long video breaks coupled VLMs
Sampling a two-hour video at 1 FPS produces over 1.6M tokens, past every current context limit, so coupled VLMs subsample frames hard and then drown the answer in noise. The paper points at two failure modes once those tokens are in context: attention dilution and the “lost in the middle” effect, both of which gut long-range reasoning. The fix is to never put the raw video in front of the reasoning model. Perception runs once, offline, and writes a compact text memory; reasoning runs online over that memory.
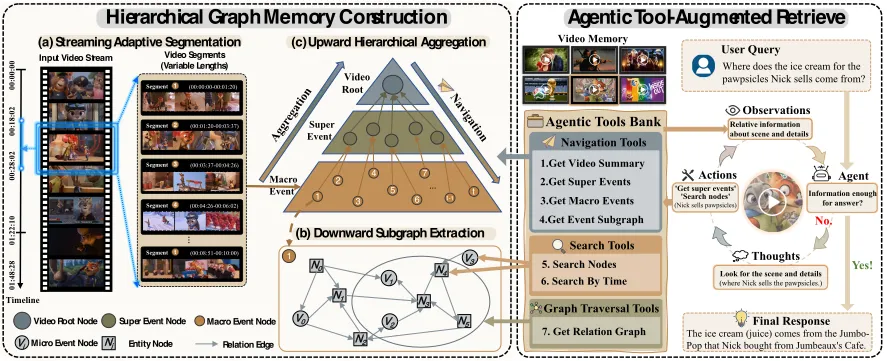
The three-tier graph memory
The memory is built coarse-to-fine and stays purely textual, so retrieval never revisits raw frames. A streaming adaptive segmenter cuts the video on semantic boundaries (a 10-minute sliding window) rather than fixed 30-second chunks, yielding self-contained Macro Events. Each Macro Event is expanded downward into a local subgraph of entities and micro-events wired by three edge types: spatial-attribute, subject-object, and temporal-causal. The system then aggregates upward: Macro Events cluster into Super Events, which converge on a single Video Root summary. The graph topology is the part that matters. The ablation strips it back to a flat chunk store and the score drops to 77.4; adding only the causal/temporal edges recovers 84.8, and adding only the hierarchy recovers 86.3. The full hierarchical graph reaches 90.7, so the hierarchy and the edges fix different failures and compound.
This builds on the broader move toward graph-structured agent memory rather than flat logs, an idea explored for text agents in Memory is Reconstructed, Not Retrieved. MemDreamer’s contribution is making it carry spatiotemporal and causal video structure.
Agentic retrieval, not embedding lookup
The reasoning model gets seven tools in three groups: hierarchical navigation (summary, super/macro events, subgraph), precise search (semantic node search, search-by-time), and graph traversal (follow relation edges). It runs an iterative loop capped at 12 rounds and stops when it has enough evidence. The design earns its complexity against the cheaper baseline: a static embedding lookup scores 70.5 while the full toolkit scores 90.7, a 20.2-point gap. Dumping the entire graph into context instead (“Full Memory”) helps summarization (81.3) but collapses on reasoning questions (72.7) because the unfiltered structure adds topological noise. Graph traversal is the single biggest tool jump (+6.6), since multi-hop chains along entity and causal edges answer the reason-over-events queries flat semantic recall cannot. This is the same lesson as rethinking retrieval beyond semantic similarity: for agentic search, a similar clip is not a relevant clip.
Key results
- LVBench: 90.7 with Gemini-3.1-Pro as both perception and reasoning, vs 78.2 for the same model end-to-end (+12.5), 3.7 points behind the human-expert score.
- LongVideoBench / Video-MME (long) / EgoSchema: 92.9 (+14.3), 91.0 (+14.0), and 92.1 (+11.8), reported as new SOTA across all four benchmarks.
- Open-source backbone: Qwen3-VL-235B-A22B-Thinking jumps from 63.6 end-to-end to 84.8 inside MemDreamer (+21.2), so the harness helps weaker reasoners more.
- Context cost: the reasoning window holds 5.9K-6.3K tokens vs 240K-784K for full-video ingestion, about a 40x cut; the perception pass itself uses 40.3K.
- Reasoning correlation: across eight models, AIME2025 score correlates with LVBench at Pearson 0.702 (p=0.052, not significant) end-to-end, rising to 0.897 (p < 0.01) under MemDreamer.
- Perception swap is cheap: changing perception between Gemini-2.5-Pro and Gemini-3.1-Pro moves the final LVBench score only 0.4-1.4 points, because perception only handles sub-10-minute clips.
How to read the headline
“Plug-and-play” is accurate but easy to over-read. The 90.7 result runs Gemini-3.1-Pro as both the perception and the reasoning engine, so this is not a small model beating a frontier model; it is a frontier model that does better when you stop forcing it to read the whole video at once. The fair comparison is same-model end-to-end versus same-model-in-MemDreamer, and on that axis the +12.5 is clean. The correlation result is the more interesting claim: under the coupled paradigm a model’s reasoning skill barely predicts its long-video score, and MemDreamer is what makes the two line up, reframing long-video progress as a retrieval-and-memory problem more than a perception one. The same decoupling instinct, applied to whole-video comprehension, shows up in Watch, Remember, Reason.
Limits and open questions
The paper has no dedicated limitations section, which is itself a tell for an agent system with this many moving parts. The biggest gap is cost accounting on the perception side: building the memory requires a full streaming pass of a strong VLM (40.3K tokens of perception context per video on LVBench), and the paper reports the thin reasoning window without the upfront construction bill, so “2% of the context” describes inference, not total work. There is no wall-clock or dollar figure for either phase, and no measurement of how memory-construction errors propagate, an entire wrong subgraph would silently cap accuracy and the agent cannot recover what perception never wrote. The human-expert baseline that anchors the 3.7-point gap is not characterized. Tool budget (12 rounds), search top-k, and the embedding model are all tuned knobs that shape the scores. And every benchmark here is curated video QA; the framework is untested on open-ended summarization at scale or on streaming/online settings where the memory must update live.
FAQ
Does MemDreamer retrain the base VLM?
No. MemDreamer is a plug-and-play, training-free framework. It wraps an existing VLM in a perception phase that builds the graph memory and a reasoning phase that retrieves over it. The LVBench gain from 78.2 to 90.7 comes entirely from the memory structure and agentic retrieval loop, using the same Gemini-3.1-Pro weights for both roles.
How does MemDreamer hit 90.7 on LVBench with only 2% of the context?
The reasoning model never ingests the raw video. It reads a compact text memory through retrieval tools, holding about 5.9K-6.3K tokens per run versus 240K-784K for end-to-end full-video ingestion, roughly a 40x cut. The “2%” refers to that reasoning-phase context, not the perception pass that builds the memory.
Why does agentic retrieval beat embedding search in MemDreamer?
In the ablation, a static embedding lookup scores 70.5 while the full agentic toolkit scores 90.7, a 20.2-point gap. Single-turn semantic recall finds visually similar clips that may have no causal link to the question, and it cannot self-correct. The iterative tool loop, especially graph traversal along causal edges (the largest single tool gain at +6.6), follows logical chains that flat similarity search misses.
What is the correlation MemDreamer reports between reasoning and long-video performance?
Across eight models, AIME2025 reasoning scores correlate with LVBench at Pearson 0.702 (p=0.052) under end-to-end ingestion, but 0.897 (p < 0.01) under MemDreamer. The interpretation: raw long-video tokens block a model from using its reasoning ability, and decoupling restores the link, so stronger reasoners gain more from the framework.
Which benchmarks and base models did MemDreamer use?
Four long-video benchmarks: LVBench (103 videos, 30 min to 2 hours), LongVideoBench, the long split of Video-MME, and EgoSchema. Perception uses Gemini-3.1-Pro; the reasoning engine is evaluated as Gemini-2.5-Pro, Gemini-3.1-Pro, or open-source Qwen3-VL-235B-A22B-Thinking. Embeddings use Qwen3-Embedding, with a 12-round tool budget.
One line: MemDreamer shows long-video understanding is bottlenecked by how you store and retrieve the video, not by raw context length, turning a 78.2 LVBench backbone into 90.7 without retraining. Read the original paper on arXiv.