Small Language Models · Language Models · Open Models
SmolLM2: A Fully Open 1.7B Model Built on a Public Data Recipe
SmolLM2 is a 1.7B model overtrained on ~11T tokens through four data stages. It scores 68.7 on HellaSwag and 19.4 on MMLU-Pro, beating Llama3.2-1B — and ships every dataset, not just the weights.
Quick answer
SmolLM2 is a 1.7-billion-parameter language model from Hugging Face, overtrained on roughly 11 trillion tokens, that scores 68.7 on HellaSwag, 60.5 on ARC, and 19.4 on MMLU-Pro — beating Meta’s Llama3.2-1B across general reasoning while staying in the same small-model tier. Its real contribution is not the model but the recipe: the team released all four training datasets — FineWeb-Edu, FineMath, Stack-Edu, and SmolTalk — so anyone can reproduce the data mixture, not just download the weights. That is the rare part. Most “open” small models publish weights and keep the data pipeline secret.
What the four training stages actually do
SmolLM2 is “overtrained” — it sees ~11T tokens, far past the compute-optimal point for 1.7B parameters, on the bet that a small model deployed at scale should soak up as much signal as it can. The training runs in four stages with a deliberately shifting mixture:
- Stage 1 (0–6T tokens): mostly English web text — the broad-knowledge foundation.
- Stage 2 (6–8T): math is introduced and the code share is raised.
- Stage 3 (8–10T): higher-quality specialized datasets fold in.
- Stage 4 (10–11T): a learning-rate decay phase that upsamples the best math and code data.
The judgment baked in here is that when a model sees data matters as much as what it sees. Saving the cleanest math and code for the final decay phase — when the model is most sensitive to high-signal tokens — is the kind of empirical detail that usually stays inside a lab. SmolLM2 documents it.
The datasets are the paper
Each dataset solves a specific weakness of small-model training:
- FineWeb-Edu — ~1.3T tokens filtered from Common Crawl by an “educational value” classifier trained on Llama3-70B-Instruct annotations. The thesis, shared with Microsoft’s Phi line, is that filtered educational text beats raw web scale for a capacity-limited model.
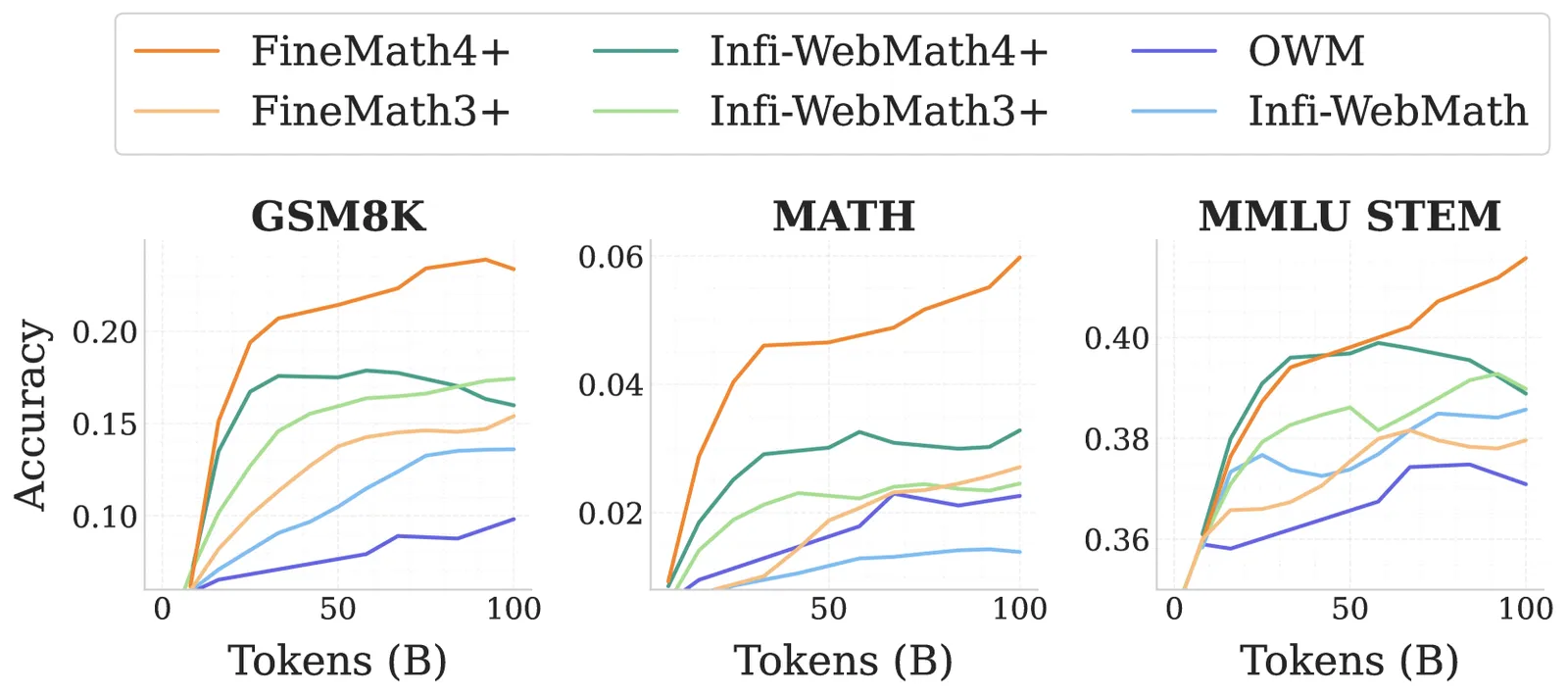
- FineMath — up to 54B tokens of math, split into FineMath4+ (10B, highest quality) and FineMath3+ (34B), filtered for actual mathematical reasoning rather than pages that merely contain numbers.
- Stack-Edu — ~125B tokens of code across 15 languages, filtered from StarCoder2Data with per-language quality classifiers.
- SmolTalk — the instruction-tuning mix, combining MagPie-Ultra conversations with targeted subsets for constraint-following, summarization, and rewriting.
The point of releasing these is auditability: you can see exactly what produced the scores, and you can re-mix them for your own model.
Key results
- General reasoning, base model: 68.7 HellaSwag, 60.5 ARC, 77.6 PIQA, 19.4 MMLU-Pro — versus 61.2 / 49.2 / 74.8 / 11.7 for Llama3.2-1B. SmolLM2 wins each.
- vs Qwen2.5-1.5B: SmolLM2 leads on broad reasoning (HellaSwag 68.7 vs 66.4, MMLU-Pro 19.4 vs 13.7) but loses badly on math and code: GSM8K 31.1 vs 61.7, MATH 11.6 vs 34.3, HumanEval 22.6 vs 37.2.
- Instruction-tuned: SmolLM2-Instruct hits 56.7 on IFEval (vs 47.4 for Qwen2.5-1.5B), so it follows instructions more reliably even where it trails on raw math.
- Smaller variants: SmolLM2-360M (4T tokens) and SmolLM2-135M (2T tokens) extend the recipe down for edge deployment, both using grouped-query attention.
The honest read: Qwen2.5 still wins on math
The single most important number in this paper is the GSM8K gap: 31.1 for SmolLM2 base versus 61.7 for Qwen2.5-1.5B — roughly half. SmolLM2 is the better general small model and clearly beats Llama3.2-1B, but if your workload is math or code generation, Qwen2.5-1.5B remains the stronger choice despite being open-weights-only. SmolLM2’s win is on reasoning breadth and reproducibility, not on every benchmark.
Limits and open questions
The headline trade is transparency for peak capability. Releasing the full data recipe is genuinely valuable for researchers, but it does not make SmolLM2 the most capable 1.7B model — Qwen2.5-1.5B’s math and code lead is large and real. The “overtraining” strategy also has an unstated cost: ~11T tokens for a 1.7B model is a lot of compute spent past the compute-optimal point, a choice that makes sense for a model meant to be deployed millions of times but is wasteful for one-off training. As with all data-filtered models, the benchmark scores depend on classifiers trained on Llama3-70B-Instruct labels, so the “educational quality” definition is itself a model artifact that could carry its own biases. And like any small model, factual recall is thin — these scores are about reasoning and instruction-following, not broad knowledge.
FAQ
How does SmolLM2 compare to Llama3.2-1B?
SmolLM2-1.7B beats Llama3.2-1B on every general-reasoning benchmark reported: 68.7 vs 61.2 on HellaSwag, 60.5 vs 49.2 on ARC, and 19.4 vs 11.7 on MMLU-Pro. It is the stronger small model on broad reasoning.
Is SmolLM2 better than Qwen2.5-1.5B?
It depends on the task. SmolLM2 leads on general reasoning and instruction-following (IFEval 56.7 vs 47.4), but Qwen2.5-1.5B is far stronger on math and code: GSM8K 61.7 vs 31.1 and HumanEval 37.2 vs 22.6 for the base models.
What datasets does SmolLM2 release?
Four: FineWeb-Edu (~1.3T tokens of filtered educational web text), FineMath (up to 54B tokens of math), Stack-Edu (~125B tokens of code across 15 languages), and SmolTalk (the instruction-tuning mix). Releasing all of them is what makes SmolLM2 fully reproducible.
Why was SmolLM2 trained on 11 trillion tokens?
That is far more than compute-optimal for a 1.7B model — it is “overtrained” on purpose. The bet is that a small model deployed at large scale should absorb as much high-quality signal as possible, even at extra training cost, since inference happens far more often than training.
What is the multi-stage training in SmolLM2?
Training runs in four stages over ~11T tokens: English web text first (0–6T), then math and more code (6–8T), then higher-quality specialized data (8–10T), and a final decay phase (10–11T) that upsamples the best math and code while the learning rate drops.
One line: SmolLM2 trades a bit of peak math ability for something rarer — a 1.7B model whose entire data recipe is open, so you can rebuild it, not just run it. Read the original paper on arXiv.