CiteVQA:专抓文档 AI「答对却引错证据」的基准
CiteVQA 要求文档问答模型在给答案时同时框出证据位置,答案与引用一起打分。最强的 Gemini-3.1-Pro-Preview 严格归因准确率仅 76.0,最佳开源模型只有 22.5。
快速答案
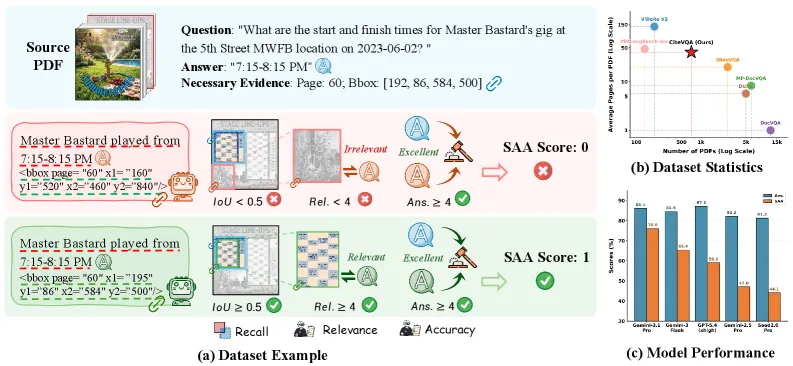
CiteVQA 是一个文档问答基准,它拒绝只看答案:模型还必须框出自己所依据证据的边界框,两者一起打分。在头号指标「严格归因准确率」(Strict Attributed Accuracy, SAA)上,被测最强系统 Gemini-3.1-Pro-Preview 仅得 76.0,而最强开源模型 Qwen3-VL-235B-A22B 只有 22.5。这道巨大的差距暴露了作者所说的「归因幻觉」:模型常常给出正确的文字答案,却指向了页面上错误的位置。
只看答案为什么掩盖了真实失败
多数文档问答基准的做法是:对一份 PDF 提问,核对最终文字答案是否匹配。这种设定会奖励「歪打正着」的模型。在合同、财报、病历这类高风险文档场景里,一个无法核验来源的正确答案并不可信,审核者不重读全文就无法确认它对不对。CiteVQA 的前提是:要做可信的文档智能,答案「从哪来」和答案本身同等重要。于是它要求每个答案都附带元素级的边界框引用,并把答案与引用联合评估,把「把推理过程亮出来」从锦上添花变成了硬性评分项。
基准里有什么
CiteVQA 含 1,897 道题、711 份 PDF,横跨七大领域(30 个子类)、两种语言:英文 451 份、中文 260 份。文档又长又真实:平均 40.6 页、中位数 30.0 页,远比早期 VQA 工作里常见的单页或短文档更接近真实文件。题目按取证难度划分:52.0% 为单文档,25.7% 为只有一个金标来源的多文档,22.3% 为需要从多个金标来源取证的多文档。最后这一档是硬骨头:模型必须在多页、多份文件里定位并组合散落的证据,而不是从一段话里照抄。
CiteVQA 如何给「定位」而非只给「答案」打分
基准定义了四个指标。Recall(召回) 衡量模型框出的证据框是否在 IoU 大于等于 0.5 的阈值下与金标证据区域重叠。Relevance(相关性) 是由大模型评判的 0-5 分,看引用的证据是否支撑答案。Answer Correctness(答案正确性) 是另一项 0-5 分的语义匹配,对照参考答案。头号指标 严格归因准确率(SAA) 是样本级二值:只有当模型既答对、又把答案落在正确证据上时,该样本才算数。SAA 故意不留情面:一旦模型是靠运气而非靠阅读答对,它就会崩塌。
关键结果
- Gemini-3.1-Pro-Preview 以 76.0 SAA 居首,是唯一越过四分之三线的模型,但离「解决」仍很远。
- 最佳开源模型 Qwen3-VL-235B-A22B 只有 22.5 SAA,尽管体量庞大,仍落后头号闭源模型约 53 分。
- 共审计了 20 个多模态大模型(7 个闭源、8 个开源大模型、5 个开源小模型),说明这道差距是全行业的普遍现象,而非个别选手太弱。
- 归因幻觉是核心发现:模型频繁给出正确答案,却引用了完全错误的视觉证据,这正是 SAA 要抓、而只看答案的基准会漏掉的失败。
- 文档平均 40.6 页,因此定位任务确实很难,证据只是长篇多页 PDF 里的一小块区域。
为什么现在重要
文档 AI 正以「带引用的有据可查答案」为卖点,被推销进法律、金融、医疗。CiteVQA 是我见到的第一个把引用当作头等、并联合打分的输出来对待的基准,而不是把它当成界面上的事后装饰,结果令人清醒。前沿模型 76.0 的天花板、最佳开源模型 22.5 的成绩,意味着这些产品给用户展示的引用框,即便答案对了也常常是错的。这比答错更糟。一个自信、格式工整却错误的引用,会主动误导那个信任它的审核者。
局限与存疑
CiteVQA 是基准论文而非方法论文:它诊断出归因幻觉,却没有给出修复它的模型,所以下一步(训练或提示模型可靠地定位证据)仍悬而未决。1,897 题、711 份 PDF 的规模是一个聚焦的诊断集,而非大型训练语料;两种语言、七个领域的覆盖在同类里算广,但并不穷尽。两个指标(相关性与答案正确性)依赖大模型评判,带有评判者偏置与不一致的常见风险。而 IoU 大于等于 0.5 的召回阈值是一种设计选择:更严的标准会拉低所有分数,所以这些绝对数值最好读作相对排名,而非固定刻度。
常见问题
CiteVQA 到底测什么?
CiteVQA 测的是文档问答模型能否既答对问题、又框出所依据证据的精确边界框,两者一起打分。它的头号指标严格归因准确率,只有在答案正确且落在正确区域时才计入。
CiteVQA 为什么比普通文档 VQA 更难?
因为只看答案的基准允许模型靠猜对蒙混过关,而 CiteVQA 还要在 IoU 大于等于 0.5 下核对引用的证据框。文档平均 40.6 页,在长 PDF 里找到正确区域本身就是难点之一。
CiteVQA 里的归因幻觉是什么?
归因幻觉是指模型给出了正确的文字答案,却引用了错误的视觉证据。CiteVQA 的结果显示这种现象很普遍,这也是严格归因准确率的最高分远低于只看答案准确率的原因。
当前模型在 CiteVQA 上表现如何?
在被评估的 20 个多模态大模型中,最强的 Gemini-3.1-Pro-Preview 达到 76.0 严格归因准确率,而最强开源模型 Qwen3-VL-235B-A22B 仅 22.5。没有任何模型接近解决有据可查的文档问答。
一句话:答对了却引错证据,仍是失败,而 CiteVQA 是第一个这样判分的基准。阅读 arXiv 原文。