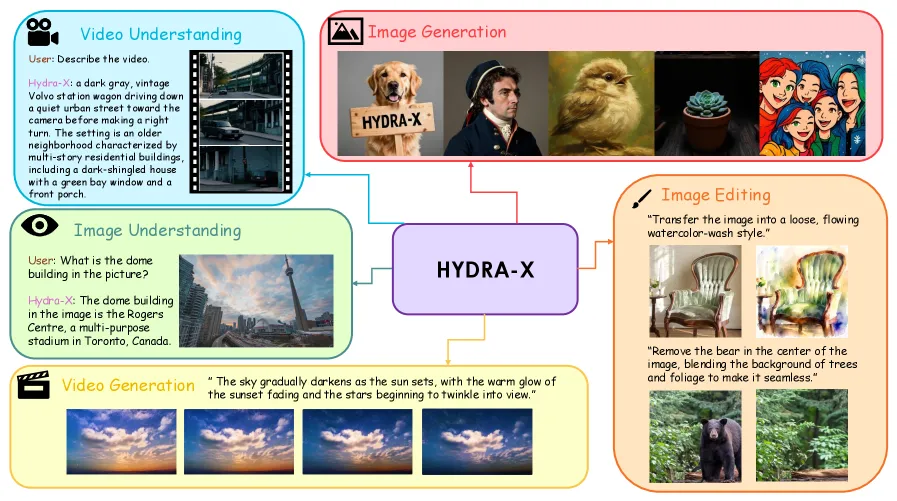
HYDRA-X:图像视频共用视觉 tokenizer
HYDRA-X 用单个 ViT 统一图像和视频 tokenization,tubelet attention 与层级时间压缩把 DAVIS rFVD 做到 11.19,编辑总分 4.34。
快速答案
HYDRA-X 是一个围绕统一视觉 tokenizer 构建的多模态模型。它的主张不是再堆一个生成头,而是图像理解、视频理解、图像生成、视频生成和图像编辑应该共享一个原生 ViT tokenizer,不要把多个视觉编码器硬拼起来。最有说服力的是消融:tubelet attention 加层级时间 patchify 在 DAVIS 上 rFVD 为 11.19,优于 full attention 的 16.20 和 causal attention 的 14.05。编辑消融中,tokenizer 内部做 source-target interaction,把重建 PSNR 从 20.74 提到 27.65,ImgEdit 从 2.80 提到 3.20。
tokenizer 本身就是核心贡献
HYDRA-X 的出发点是:视觉 tokenizer 不是普通适配器。如果图像和视频走不同模块,LLM 要处理表示不匹配。如果视频 tokenizer 只压缩时间而缺少语义监督,它可能丢掉理解所需细节。HYDRA-X 把图像和视频放进同一个 ViT tokenizer,同时训练重建和语义对齐。
反直觉结果是,更少的时间注意力更好。full spatiotemporal attention 听起来最完整,但消融显示它会伤害重建。2-frame causal tubelet 保留局部运动,又不会过度混合跨帧结构。层级 2x2 时间压缩也比一步 4x 压缩更好。
Decompressor 只在 tokenizer 训练时使用。它把压缩后的视频特征上采样回原帧率,让视频教师模型提供监督;推理时 LLM 仍拿紧凑 token。图像编辑里,HYDRA-X 把源图和目标图当作长度为 2 的 clip,让 tokenizer 先对齐细节,再交给 LLM。
关键结果
- 重建消融中,最终设计 ImageNet PSNR 31.73,DAVIS PSNR 27.97,DAVIS rFVD 11.19。
- 语义蒸馏不可少:去掉后 MVBench 29.8、VideoMME 27.4;带视频教师 Decompressor 后为 45.4 和 45.0。
- source-target interaction 把 ImgEdit 从 2.80 提到 3.20,源图重建 PSNR 从 20.74 提到 27.65。
- 视频理解上,7B HYDRA-X 报告 MVBench 59.1、Video-MME 60.0、LongVideoBench 59.5、LVBench 30.0。
- 编辑上,HYDRA-X 的 ImgEdit overall 为 4.34,GEdit overall 为 7.17,高于表中统一多模态基线和 BAGEL。
对研究者和构建者的判断
实际价值不在于照搬标题数字。HYDRA-X 适合在你的任务分布和论文设置相近时参考,尤其要看清楚比较对象、评测协议和收益来源。如果你的系统瓶颈不是论文测到的那个环节,同一个方法可能只会增加复杂度。更稳妥的做法是先复现一个小规模本地评测,确认收益来自方法本身,而不是数据、工具链或裁判口径。
对构建者来说,关键问题是统一 tokenizer 能否降低系统复杂度,同时不抹掉任务特有信号。HYDRA-X 在编辑和短视频上给出了较可信的正面证据,因为消融把结构选择直接连到了 PSNR、rFVD、ImgEdit 和视频理解指标。它并不意味着所有视觉任务都只需要一个编码器,也不取消专用 decoder 和任务 loss 的作用。
局限与存疑
HYDRA-X 是 7B 统一系统,不能解读成全面超过所有专用生成模型或视频模型。专用和闭源视频模型在若干理解指标上仍更强。论文最扎实的部分是 tokenizer 设计与消融逻辑。想用单架构覆盖理解、生成和编辑的团队值得关注;但在代码和权重细节清楚前,不要假设能直接复现。
真正会改变判断的证据,是更独立的外部复现、更完整的发布产物,以及由非作者团队设计的压力测试。在那之前,这篇更适合作为有清晰证据面的方向性结果,而不是无条件通用结论。
常见问题
HYDRA-X 是什么?
它是一个统一多模态模型,用单个 ViT-based tokenizer 处理图像和视频,覆盖理解、生成和编辑任务。
HYDRA-X 为什么用 tubelet attention?
消融显示 full spatiotemporal attention 反而伤害重建。2-frame tubelet 提供局部时间上下文,同时保留单帧结构。
HYDRA-X 如何提升图像编辑?
它让源图和目标图在 tokenizer 内部按长度为 2 的 clip 交互。消融中重建 PSNR 从 20.74 到 27.65,ImgEdit 从 2.80 到 3.20。
一句话:HYDRA-X 的价值在于让视觉 tokenizer 先携带图像-视频结构,再把 token 交给 LLM。 阅读 arXiv 原文。