Robust-U1:先修复图像再理解
Robust-U1 让多模态模型先自恢复受损图像再推理,R-Bench 总分 0.7398,高于 BAGEL 的 0.5770 和 Robust-R1 的 0.5017。
快速答案
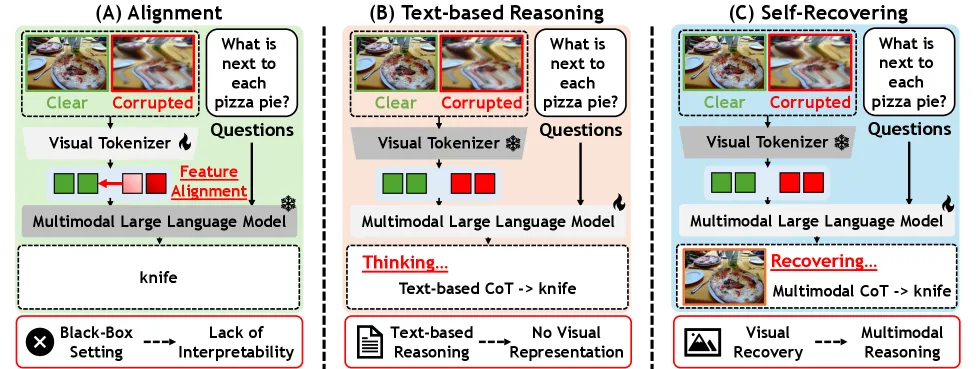
Robust-U1 的核心判断很直接:多模态模型遇到受损图片时,不能只用文字链解释“哪里坏了”,而应该尝试恢复视觉内容,再同时看原受损图和恢复图作答。R-Bench 总分上,Robust-U1 达到 0.7398,BAGEL 是 0.5770,Robust-R1 是 0.5017。在 100% 合成腐蚀的 MMMB 上,它有 83.18 分,高于 BAGEL 的 78.48 和 Robust-R1 的 75.35。论文真正有价值的地方,是把恢复质量纳入推理链,而不是把图像修复当成独立演示。
机制:把恢复图变成推理输入
方法分三步。第一步用监督微调让模型获得初始恢复能力,把受损图映射到更清晰的视觉内容。第二步用强化学习继续对齐恢复质量,奖励包括像素层 SSIM 和语义层 CLIP 相似度。第三步训练模型同时使用受损图和恢复图回答问题。
这个设计对应了已有方法的短板。黑盒特征对齐能改善受损图特征,但过程难解释;文本式腐蚀推理比较透明,但它无法补回像素细节。Robust-U1 的赌注是:如果模型能生成足够可信的恢复图,很多视觉判断会比只靠文字描述更稳。
案例研究很能说明问题。在一张退化的驾驶图中,Qwen2.5-VL 和 Robust-R1 都判断错了前车方向;BAGEL 尝试恢复,但恢复图误导了答案;Robust-U1 恢复出的图支持正确的 left 答案。这不是自动驾驶可靠性证明,但说明了纯文字腐蚀链为什么会不够。
关键结果
- R-Bench 总分 Robust-U1 为 0.7398,BAGEL 为 0.5770,Robust-R1 为 0.5017。
- 高退化 CAP 子项差距明显:Robust-U1 是 0.7640,BAGEL 0.4288,Robust-R1 0.3484。
- MMMB 在 100% 腐蚀下,Robust-U1 为 83.18,BAGEL 为 78.48,Robust-R1 为 75.35。
- MMMB 从 clean 到 100% 腐蚀的下降,Robust-U1 只有 1.57 点,BAGEL 为 3.44 点,Robust-R1 为 6.06 点。
- R-Bench 消融显示完整模型 0.7398;去掉 multimodal reasoning 降到 0.6623,去掉任一奖励约降到 0.726。
对研究者和构建者的判断
实际价值不在于照搬标题数字。Robust-U1 适合在你的任务分布和论文设置相近时参考,尤其要看清楚比较对象、评测协议和收益来源。如果你的系统瓶颈不是论文测到的那个环节,同一个方法可能只会增加复杂度。更稳妥的做法是先复现一个小规模本地评测,确认收益来自方法本身,而不是数据、工具链或裁判口径。
局限与存疑
Robust-U1 最适合那些腐蚀还能被合理逆转的场景。如果原图证据已经彻底丢失,恢复就可能变成幻觉。更麻烦的是,恢复图看起来更清晰,语言模型反而可能更相信一个错误证据。实际使用时,它适合提升常见退化下的感知稳定性,但安全关键细节仍需要不确定性检查和外部验证。
真正会改变判断的证据,是更独立的外部复现、更完整的发布产物,以及由非作者团队设计的压力测试。在那之前,这篇更适合作为有清晰证据面的方向性结果,而不是无条件通用结论。
常见问题
Robust-U1 是什么方法?
它让多模态模型先恢复受损视觉内容,再同时依据受损图和恢复图回答问题,目标是提升真实退化和合成腐蚀下的视觉理解鲁棒性。
Robust-U1 在 R-Bench 上提升多少?
R-Bench 总分是 0.7398,高于 BAGEL 的 0.5770 和 Robust-R1 的 0.5017,覆盖 MCQ、VQA、CAP 以及低中高三档退化。
Robust-U1 的双重奖励有什么用?
SSIM 奖励约束结构保真,CLIP 相似度奖励约束语义一致。完整模型综合两者,总体分数高于去掉任一奖励的变体。
一句话:Robust-U1 的价值在于把图像自恢复纳入多模态推理,但它也提醒我们,更清晰的恢复图不等于一定更真实。 阅读 arXiv 原文。