StreamMA:多智能体推理里,边写边传比等完再传更聪明
StreamMA 让智能体生成一步推理就立刻流式传给下游,而不是等整条链写完。8 个基准平均涨 7.3 个百分点(HMMT 2026 最高 +22.4),并行场景最快提速 26.9 倍。
快速答案
StreamMA 只改了多个大模型智能体之间「怎么交流」这一件事:传统做法是 A 把整条思维链写完,再把完整结果整体交给 B(即「先生成、后传递」);StreamMA 让 A 每生成一步推理,就立刻把这一步流式发给下游。于是 B 在 A 还没想完时就开始基于 A 的早期步骤干活。这种流水线带来的提速是意料之中的:端到端延迟大幅下降,在最并行的配置(64 个智能体、每个 64 步)下最快提速 26.9 倍,约为理论加速上界的 83%。
真正出人意料的是准确率。在 8 个推理基准上,StreamMA 相比串行多智能体基线和单智能体基线平均高出 7.3 个百分点,在 HMMT 2026 上用 Claude Opus 4.6-high 时峰值高出 22.4 个百分点。作者认为这不是偶然,而是推理链「哪里容易出错」的直接结果。
为什么只传部分思维链反而更准
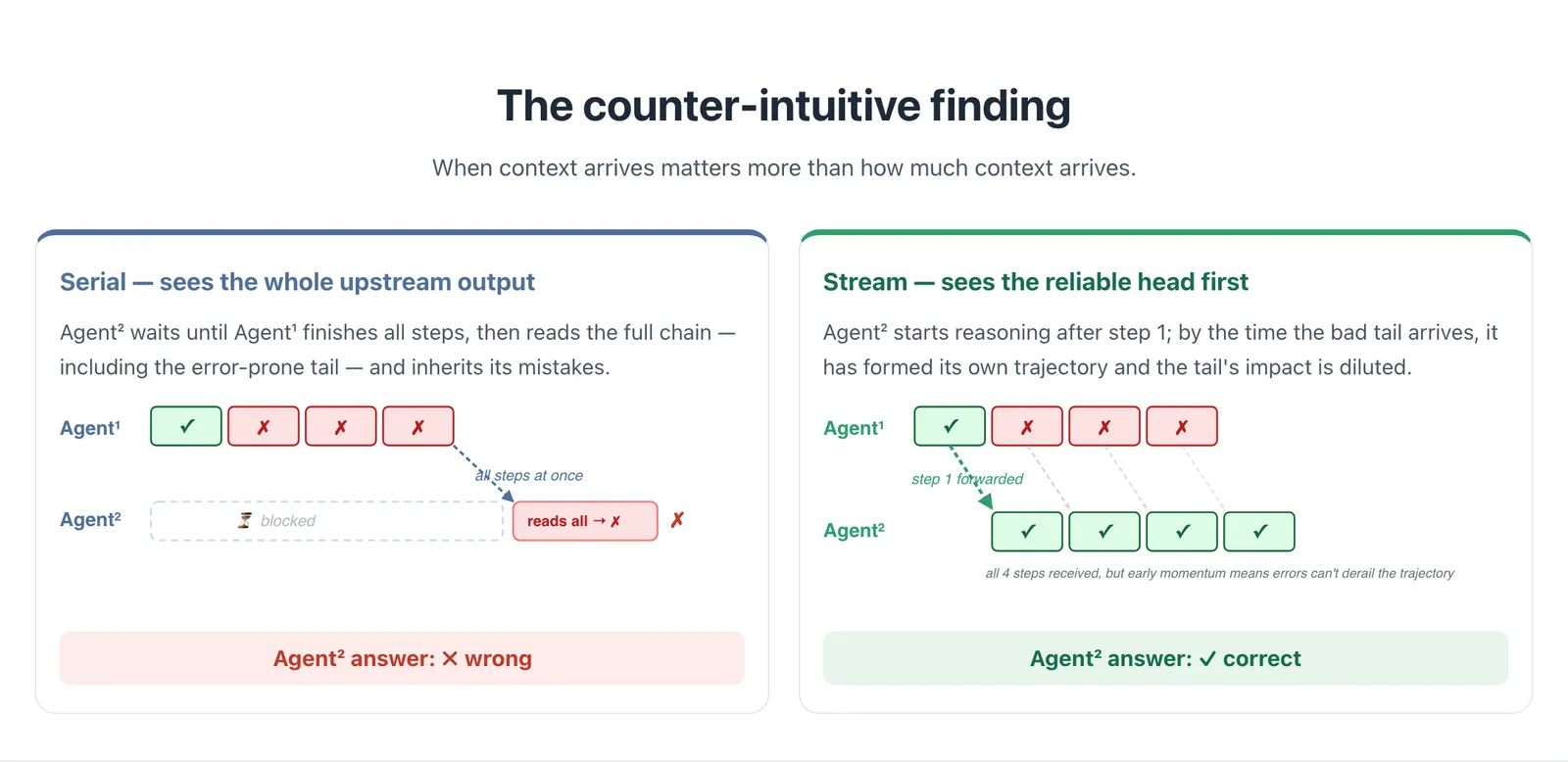
这个反直觉的结论才是论文的真正卖点。按常理,给下游智能体看到的上游内容更少(只有早期步骤、没有最终答案),应该会更差。StreamMA 发现恰恰相反,原因很锋利:多步推理的质量是不均匀的。思维链里早期的步骤更可靠,后期步骤会累积错误、跑偏、过度思考。一个串行智能体等到上游整条链写完,就把那条容易出错的「尾巴」一起继承了,被它带歪。
而流式智能体先看到可靠的「头部」,并据此形成自己的推理轨迹。等那条糟糕的尾巴传过来时,下游智能体已经有了自己的方向,于是后期步骤的错误被稀释,而不是被照抄。速度和质量来自同一个机制,你不是在二者之间做取舍。读这篇论文最清晰的角度是:它把「智能体之间该传多少上下文」这个问题,重新定义成「上下文什么时候到达」,并证明时机比体量更重要。
理论:流式、串行、单体的闭式分析
让这篇工作超越「经验小技巧」的,是作者给出了流式(stream)、串行(serial)、单体(single)三种通信协议的首个闭式联合分析。由此推出三样东西:有效性排序(哪种协议预期更准、为什么)、加速上界(给定流水线深度和步数,流式最多能快多少)、以及成本比(相对基线的 token 开销)。
成本这一块给得很具体。在他们的账本里,Stream x4 配置约 2.75 美元,而 Serial x16 约 5.46 美元,大约一半的价钱却换来更高准确率。也就是说,流式是在更低成本区间拿到更好结果,而不是靠堆 token 买准确率。前面那个 26.9 倍 / 83% 上界的数字,正是相对这个加速上界来衡量的:流式无法超过理论流水线极限,但实测能贴得很近。
步级缩放律
最后一项贡献是一个新的缩放旋钮。多智能体研究通常靠「加智能体」来扩展。StreamMA 报告说,在智能体数量固定的前提下,提升「每个智能体的推理步数」(S)能持续改善有效性和效率,这就是「步级缩放律」。它被描述为与智能体数量缩放正交、且可叠加:两个旋钮可以一起拧。如果这个规律站得住,它就是一个相当实用的设计杠杆,因为加步数比加整个智能体便宜,而且天然喂给流式流水线。
关键结果
- 平均 +7.3 个百分点:在全部 8 个基准上相对串行多智能体和单智能体基线的准确率提升。
- 峰值 +22.4 个百分点:在 HMMT 2026 上用 Claude Opus 4.6-high,单基准最大涨幅。
- 最快提速 26.9 倍:在 A=64、S=64 配置下,约为理论加速上界的 83%。
- Stream x4 约 2.75 美元 vs Serial x16 约 5.46 美元:约一半成本拿到更高准确率。
- 覆盖 8 个基准(AIME25、AIME26、HMMT 2026、GPQA-D、HLE,以及 LiveCodeBench 的 LCB-G/E/T 三个子集),横跨数学、科学、代码;两个前沿模型(Claude Opus 4.6、GPT-5.4);三种拓扑(链、树、图)。
- 一条步级缩放律:每个智能体步数越多,准确率与效率同时提升,且与智能体数量缩放正交。
局限与存疑
最大的保留是准确率结论的普适性。「早期步骤可靠、后期步骤跑偏」对这些基准衡量的长链数学 / 科学 / 代码推理大概率成立。但这恰恰是「过度思考」作为已知失败模式的领域。如果任务的结论恰好在最后一步(多跳综合、回报在末尾的长程规划),那么只把早期头部喂给下游智能体,可能会丢掉最关键的部分。论文似乎没有覆盖这种情况。
其次,头条涨幅依赖 Claude Opus 4.6-high;在更弱、更便宜、早期步骤本身就更不靠谱的模型上,那 +22.4 个百分点还能剩多少,是最自然的追问。第三,闭式分析必然对步骤可靠性和独立性作了假设,推导很优雅,但它证出的排序只在这些假设成立时才成立。如果你的工作负载是短链或单次推理,这篇可以跳过:流式的优势在结构上就绑定在「多个协作智能体的长多步链」上。
常见问题
StreamMA 是什么,和普通的多智能体推理有何不同?
StreamMA 是一个多智能体推理系统,它在每生成一步推理时就立刻把这一步流式传给下游智能体,而不是标准的「先生成完整思维链、再整体传递」。这样让相邻智能体形成流水线,降低延迟;并且出人意料地提升了准确率,因为下游智能体是基于可靠的早期步骤工作,而非容易出错的完整链。
StreamMA 究竟快多少、准多少?
在论文的基准里,StreamMA 相对串行和单智能体基线平均高 7.3 个百分点,在 HMMT 2026 上用 Claude Opus 4.6-high 峰值高 22.4 个百分点;在 64 智能体 x 64 步配置下最快提速 26.9 倍(约理论上界的 83%),且 token 成本约为同等串行配置的一半。
StreamMA 的步级缩放律是什么意思?
它是指:在智能体数量固定的前提下,增加每个智能体的推理步数,能持续同时改善有效性和效率。作者把它作为一个新的缩放维度提出:与「加更多智能体」这一常规做法正交,并且可以叠加使用。