AI Agents · Code Generation · LLM Reasoning
Code as Agent Harness: Reframing Code as the Runtime of AI Agents
This survey reframes code not as a thing agents generate but as the executable substrate they run on, mapping 40-plus systems across three layers (interface, mechanisms, multi-agent scaling) plus seven open problems.
Quick answer
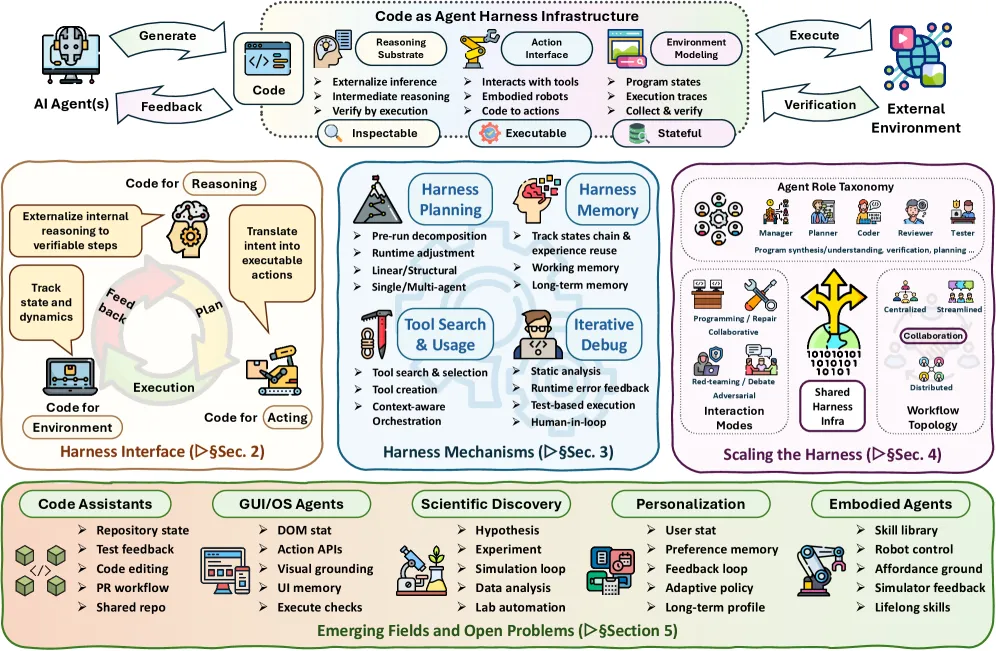
This survey argues that in modern AI agent systems, code is not the output. It is the runtime medium agents act through. The authors organize the field into three layers: the harness interface (code for reasoning, acting, and environment modeling), harness mechanisms (planning, memory, tool use, control loops), and scaling to multi-agent coordination over shared code. They tabulate roughly 20 representative code-reasoning systems and 20 code-acting systems, map five application domains, and end on seven open problems. It is a position-and-taxonomy paper from a large University of Illinois Urbana-Champaign-led group, not a new model.
The one idea worth taking away
The reframing is the contribution: stop treating LLM-written code as a generated artifact and start treating it as the operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. The authors lean on three properties that make code uniquely suited to this role. Code is executable, so an agent’s intent becomes an outcome you can actually verify by running it. Code is inspectable, so intermediate state is visible rather than hidden inside model weights. Code is stateful, so it persists across steps and gives a long-running task a place to keep its working memory. Most agent surveys catalog prompts and tools; this one’s bet is that the durable abstraction is the code-as-substrate view, and the rest is implementation.
The three-layer taxonomy
Layer 1, harness interface (Section 2). Code is the connective tissue between the agent and the world, split three ways. Code for reasoning externalizes thinking into runnable programs: program-delegated computation (the PoT/PAL lineage), formal verification (theorem-prover-style checking), and iterative code-grounded reasoning. Code for acting turns intent into action via skill selection, policy generation, and lifelong agents that accumulate skills (the Voyager line). Code for environment covers structured state representations, execution traces, evaluation environments, and verifiable construction.
Layer 2, harness mechanisms (Section 3). What keeps a code-centric agent alive over a long horizon. Planning spans linear decomposition, structure-grounded, search-based, and orchestration-based approaches. Memory is split into six types: working, semantic, experiential, long-term, multi-agent, and context compaction. Tool use is grouped into function-oriented, environment-interaction, verification-driven, and workflow-orchestration. Control sits on top as Plan-Execute-Verify loops plus adaptive harness engineering.
Layer 3, scaling the harness (Section 4). Multi-agent collaboration over shared code: functional specialization into roles, execution-feedback integration, shared-state synchronization, and convergence mechanisms. The shared codebase becomes the coordination substrate, the place where multiple agents read, write, and reconcile.
Key results
This is a survey, so the “results” are coverage and structure, not benchmark scores:
- Three layers, mapped end to end: interface, mechanisms, and multi-agent scaling, presented as one connected stack rather than separate topics.
- ~20 + ~20 systems tabulated: Table 1 lists about 20 representative code-reasoning systems (PoT, PAL, ReProver and similar); Table 2 lists about 20 code-acting systems (SayCan, Code-as-Policies, Voyager and similar).
- Five application domains: coding assistance, GUI/OS automation, scientific discovery, personalization, and embodied control.
- Three defining properties of code: executable, inspectable, and stateful, the paper’s framing device.
- Seven open problems in Section 5.2, spanning evaluation, verification, safety, and coordination at scale.
- Literature coverage up to 2026, with 43 listed authors across UIUC, Meta, and Stanford.
Why read this now
Agent research in 2026 is fragmenting into per-framework jargon, and a clean conceptual map has real value. The genuinely useful move here is the distinction between agent-initiated code artifacts (what the agent writes) and system-provided infrastructure (the harness the agent runs inside). Most practitioner discussions blur that line, and drawing it clarifies why “give the agent a code interpreter” and “build an agent harness” are different engineering problems. If you are designing an agent system and arguing about planning vs memory vs tool abstractions, the Layer-2 breakdown is a ready-made checklist.
Limits and open questions
The honest caveat is that this is a survey, so it inherits surveys’ weaknesses: no new method, no benchmark, no empirical claim you can reproduce, and a taxonomy is only as good as how cleanly the field actually splits along its seams. The three-property framing (executable/inspectable/stateful) is clean but not falsifiable, since plenty of agent behavior is none of those things. The “code as substrate” thesis is also partly a relabeling. Much of what is filed under “code for reasoning” or “code for acting” was already studied as tool use or program synthesis, and the survey’s value is the organization, not a new mechanism. The seven open problems are named rather than solved. Treat it as a map and a reading list, not as evidence that the code-centric view wins.
FAQ
What is the main argument of Code as Agent Harness?
Code should be understood as the executable runtime substrate that agents reason, act, and coordinate through, not merely as text the model generates. The paper backs this with three properties: code is executable, inspectable, and stateful.
What is the taxonomy in Code as Agent Harness?
Three layers: the harness interface (code for reasoning, acting, and environment), harness mechanisms (planning, memory, tool use, control loops), and the scaling layer where multi-agent systems coordinate over shared code.
Does Code as Agent Harness introduce a new model or benchmark?
No. It is a survey and position paper. It tabulates roughly 40 representative systems, maps five application domains, and lists seven open problems, but proposes no new model, training method, or benchmark.
Who wrote Code as Agent Harness?
A 43-author group led from the University of Illinois Urbana-Champaign, with contributors affiliated with Meta and Stanford, covering code-centric agent literature up to 2026.
Who should read Code as Agent Harness?
Anyone designing agent systems who wants a shared vocabulary for planning, memory, and tool abstractions, or a structured reading list of code-reasoning and code-acting systems. Skip it if you need a concrete method or empirical results.
One line: code is the agent’s runtime, not its output, and this survey is the map of that view. Read the original paper on arXiv.