AI Agents · Multimodal Models · Reinforcement Learning
Orchestra-o1: Omnimodal Agent Orchestration
Orchestra-o1 orchestrates text, image, audio, and video sub-agents and hits 72.8% on OmniGAIA with a GPT-5 brain (+10.3 over Gemini-3-Pro). Its trained 8B orchestrator reaches 30.0%, best among open omnimodal agents.
Quick answer
Orchestra-o1 is an agent-orchestration framework that splits an omnimodal task across specialized sub-agents for text, image, audio, video, and tools, then runs the independent ones in parallel. With GPT-5 as the orchestrating brain it scores 72.8% on the OmniGAIA benchmark, 10.3 points above Gemini-3-Pro (62.5%) and 32.8 above the prior orchestration framework AOrchestra running on the same GPT-5 (40.0%). Two numbers matter for reading this honestly. The 72.8% comes from a proprietary GPT-5 backend, not from anything the paper trained. Separately, the authors train an 8B orchestrator with their DA-GRPO method that reaches 30.0%, which is the actual model contribution and the best among open-source omnimodal agents (vs 20.8% for OmniAtlas-Qwen3-30B).
What the framework actually does
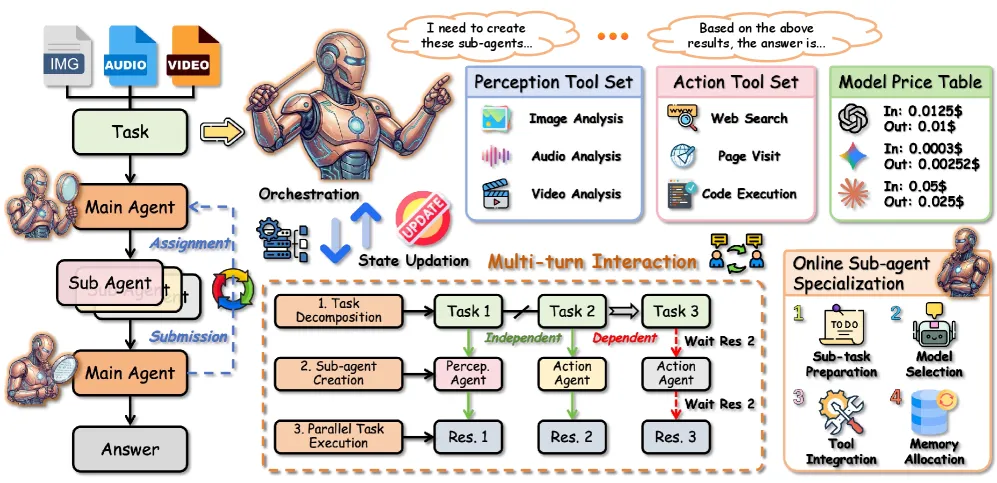
An omnimodal task, say watch a clip, read a chart, and answer a question that needs both, overwhelms a single agent’s context and tool repertoire. Orchestra-o1’s main agent induces a dependency graph over sub-goals, where each sub-goal carries a modality mask (text/image/audio/video) and a tool mask. That mask is the interesting part: instead of every sub-agent seeing every tool and every input stream, each one is scoped to the evidence it needs. A sub-goal that only needs audio analysis never touches the video pipeline.
Three mechanisms sit on top. Modality-aware decomposition builds the graph. Online sub-agent specialization picks a backend per sub-task using a cost-aware matching score that trades off capability, latency, and price, then assigns a sparse tool subset. Parallel execution runs all independent sub-tasks in a delegation round at once; the paper’s Proposition 1 bounds the round-level speedup between 1x and the number of tasks K, with synchronization as the cap. The main agent itself holds no tools; it only orchestrates, which keeps its context window small (24,576 tokens) while the sub-agents do the heavy lifting (up to 30 steps each).
The tool set is six functions: image, audio, and video analysis, web search, page visit, and code execution. MemDreamer attacks a neighbouring problem, agentic retrieval over long multimodal context, and the two read well together: Orchestra-o1 distributes the context across sub-agents instead of compressing it into one memory.
How DA-GRPO trains the 8B orchestrator
Standard GRPO rewards the final answer. The problem for an orchestrator is that a good answer can come from sloppy delegation and a bad answer from sound delegation, so final-answer reward is a noisy teacher for orchestration decisions. Decision-aligned GRPO (DA-GRPO) replaces it with a multi-dimensional rubric reward scored by an external model (Claude Haiku 4.5): format correctness (weight 0.1), action validity (0.1), tool reasonableness (0.2), and decision quality (0.6). The heavy 0.6 weight on decision quality is the design bet: the gradient mostly chases whether the decomposition and delegation were right, not whether the final string matched.
On the 8B backbone (Qwen3-8B) the recipe is incremental. The framework alone lifts a ReAct baseline from 12.5% to 26.3%. SFT on curated trajectories adds to 28.6%. Vanilla GRPO actually lands lower at 27.7%, and only DA-GRPO reaches 30.0%. So DA-GRPO beats plain GRPO by 2.3 points and beats SFT by 1.4. Real, but the larger share of the 8B’s score comes from the orchestration harness, not the RL objective. The pattern of training an agent with a step-level reward rather than an outcome-only one also shows up in code agents like DenovoSWE, where intermediate signal matters for long action chains.
Key results
- OmniGAIA, proprietary setting: Orchestra-o1-GPT-5 scores 72.8% vs Gemini-3-Pro 62.5% (+10.3), Gemini-3-Flash 51.7%, AOrchestra-GPT-5 40.0% (+32.8), and Gemini-2.5-Pro 30.8%. The big gap over AOrchestra is the orchestration design, since both ran on GPT-5.
- Cost, not just accuracy: Orchestra-o1-GPT-5 reports a cost of 341.6 against AOrchestra-GPT-5’s 565.7, higher accuracy at roughly 60% of the cost, which is the more defensible claim than accuracy alone.
- Open-source setting: the DA-GRPO-trained Orchestra-o1-8B reaches 30.0% vs OmniAtlas-Qwen3-30B 20.8% (+9.2), beating a model nearly 4x its size.
- Difficulty breakdown (GPT-5): 80.3% easy, 75.0% medium, 56.4% hard. The hard tier at 56.4% is where omnimodal orchestration still struggles and where the headline 72.8% hides the variance.
- Ablation (Qwen3-8B): ReAct 12.5 -> framework 26.3 -> SFT 28.6 -> vanilla GRPO 27.7 -> DA-GRPO 30.0. The framework contributes +13.8; DA-GRPO contributes +1.4 over SFT.
- Backend matters: the 72.8% is a GPT-5 result. The framework is the reusable artifact; the score travels with whatever brain you plug in.
How to read the 72.8
The 72.8% is an orchestration-plus-GPT-5 number, so it does not say Orchestra-o1 is a strong model. It says a good orchestration layer extracts 10.3 more points from GPT-5 than Gemini-3-Pro manages on its own, and 32.8 more than the prior orchestration framework manages on the same GPT-5. The model the authors actually built and trained is the 8B, and it scores 30.0%. Conflating those two, quoting 72.8% as if it were a trained system’s capability, is the easy misread. The fair comparison for the framework is AOrchestra on identical backends; the fair comparison for the trained model is other open omnimodal agents.
Limits and open questions
OmniGAIA is reused from prior work, not built here, so leakage and per-category sample sizes are inherited rather than audited in this paper; the finance category at 83.8% versus history at 64.0% suggests uneven coverage worth checking before trusting any single category number. The cost figure of 341.6 is in the paper’s own units without a token or wall-clock breakdown, so cross-system cost claims rest on that accounting. DA-GRPO depends on an external rubric grader (Claude Haiku 4.5), which means the 30.0% reflects that grader’s judgment of decision quality; a different grader could shift the reward signal and the result. Parallel execution’s speedup is proven as a bound, not measured end-to-end with real synchronization overhead. And the gap between 72.8% (GPT-5) and 30.0% (trained 8B) is large enough that the framework’s value today is mostly as a wrapper for frontier proprietary models, with the open 8B still far behind.
FAQ
What is Orchestra-o1 and who built it?
Orchestra-o1 is an omnimodal agent-orchestration framework from LUMIA Lab, with authors from CUHK, Peking University, Tsinghua, Tongji University, and CASIA, among others. A main agent decomposes a task into modality-scoped sub-goals (text, image, audio, video), assigns specialized sub-agents with cost-aware backend selection, and runs independent sub-tasks in parallel. It scores 72.8% on OmniGAIA with GPT-5.
Why does Orchestra-o1 hit 72.8% with GPT-5 but only 30.0% as the trained 8B?
The 72.8% comes from running the orchestration framework on a GPT-5 backend, so it measures the harness plus a frontier model. The 30.0% is Orchestra-o1-8B, the model the authors actually trained with DA-GRPO on a Qwen3-8B backbone. The 8B figure is the real model contribution and leads open-source omnimodal agents (20.8% for OmniAtlas-Qwen3-30B); the 72.8% is the framework’s ceiling with a strong brain.
How does DA-GRPO differ from standard GRPO in Orchestra-o1?
Standard GRPO rewards only final-answer correctness, which is a noisy signal for orchestration since good delegation can still miss the answer. DA-GRPO uses a rubric reward scored by Claude Haiku 4.5 across format (0.1), action validity (0.1), tool reasonableness (0.2), and decision quality (0.6). On Qwen3-8B it reaches 30.0% vs 27.7% for vanilla GRPO and 28.6% for SFT.
How much cheaper is Orchestra-o1 than AOrchestra?
On OmniGAIA with GPT-5, Orchestra-o1 reports a cost of 341.6 against AOrchestra’s 565.7 while scoring 72.8% vs 40.0%. So it is both higher accuracy and roughly 40% cheaper in the paper’s cost units, which makes the efficiency claim stronger than the accuracy claim alone.
Is OmniGAIA a new benchmark introduced by Orchestra-o1?
No. OmniGAIA is a prior benchmark for omnimodal agents covering text, image, audio, and video inputs across difficulty tiers (easy/medium/hard) and topical categories. Orchestra-o1 evaluates on it rather than introducing it, so its construction, leakage controls, and sample sizes come from the original benchmark paper.
One line: Orchestra-o1 shows omnimodal orchestration can pull 10.3 extra points out of GPT-5 on OmniGAIA and that a DA-GRPO-trained 8B leads open omnimodal agents at 30.0% — keep the 72.8% framework result and the 30.0% model result separate. Read the original paper on arXiv.