Diffusion Models · Text-to-Image · Transformers
Rethinking Cross-Layer Information Routing in Diffusion Transformers
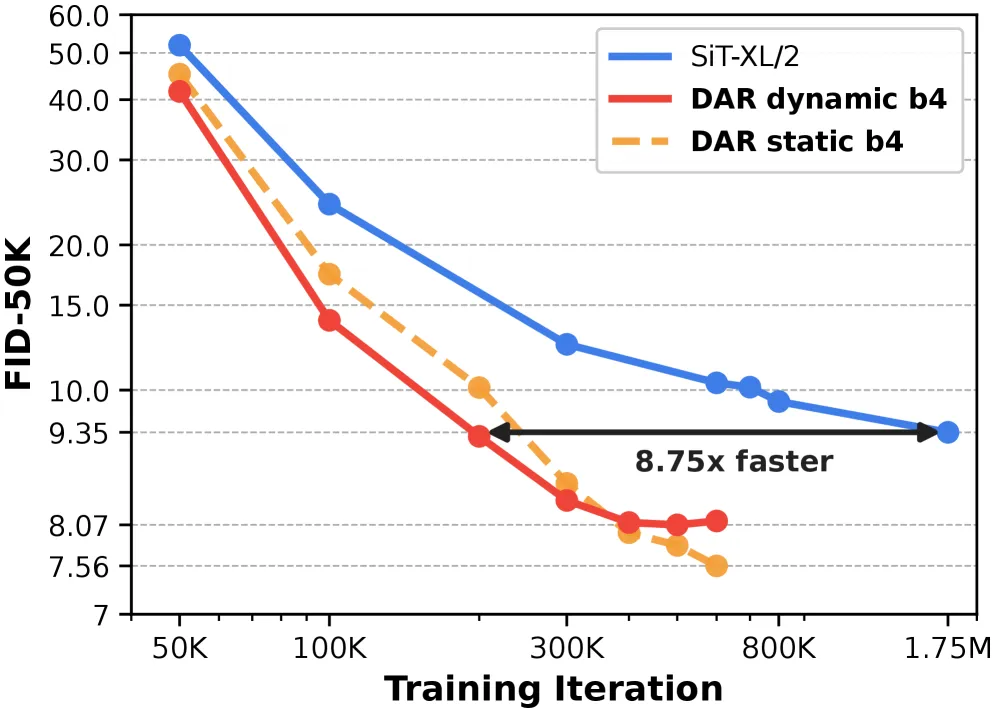
DAR replaces the residual add in diffusion transformers with timestep-adaptive aggregation of past sublayer outputs, cutting SiT-XL/2's ImageNet FID from 9.67 to 7.56 with 8.75x fewer iterations.
Quick answer
Diffusion-Adaptive Routing (DAR) swaps the plain residual addition inside a diffusion transformer for a learnable, timestep-aware weighted aggregation over the history of previous sublayer outputs. On ImageNet 256x256 it lowers SiT-XL/2’s FID from 9.67 to 7.56 (a 2.11-point gain) and reaches the baseline’s final quality using 8.75x fewer training iterations. Stacked on top of REPA it delivers about 2x training acceleration in the early stage.
The three things residual addition gets wrong
The paper’s contribution is diagnostic before it is architectural. Standard residual connections — x = x + sublayer(x) — were inherited from language transformers and never re-examined for diffusion. The authors measure three concrete pathologies as depth grows across the 28 blocks of SiT-XL/2:
- Monotonic forward magnitude inflation. Because every block only ever adds to the running stream, the residual norm climbs steadily with depth. PreNorm then has to divide out an ever-larger magnitude, diluting each new block’s contribution — the deeper the block, the less it can actually change.
- Sharp backward gradient decay. The same additive accumulation that inflates the forward pass starves the backward one: gradients reaching early layers shrink fast, so the bottom of the network trains weakly.
- Pronounced block-wise redundancy. Adjacent blocks end up computing near-duplicate updates, wasting capacity that a 28-block model should be spending on distinct features.
The honest framing here is that none of these are new transformer observations in isolation — what is new is showing they are specifically harmful in the diffusion setting and that a single mechanism addresses all three.
How DAR works
Instead of adding each sublayer’s output straight into the stream, DAR keeps the history of sublayer outputs and forms the next input as a learned weighted combination of them. Two properties matter. First, the aggregation is non-incremental: a block can down-weight or skip earlier contributions rather than being forced to carry their accumulated magnitude forward, which directly attacks the inflation problem. Second, the routing weights are timestep-adaptive — diffusion runs the same network across many noise levels, and DAR lets the routing differ between a high-noise early step and a near-clean late step, which a static residual cannot do.
The paper reports both a static variant (fixed learned coefficients, e.g. the “static c4” / “static b4” configurations) and a dynamic, timestep-conditioned variant. The static version is notable because it adds essentially no inference cost yet still delivers the headline FID gain, which is the more deployable result.
Key results
- ImageNet 256x256 FID: DAR brings SiT-XL/2 from 9.67 to 7.56, a 2.11-point improvement, with the static configuration.
- Training efficiency: DAR matches the SiT-XL/2 baseline’s converged quality using 8.75x fewer training iterations — the central efficiency claim and the figure shown on the FID-versus-iteration curve.
- Composability with REPA: stacking DAR on the REPA recipe yields roughly 2x training acceleration in the early stage, indicating the gain is orthogonal to representation-alignment tricks rather than overlapping with them.
- Generality: the authors apply DAR to pre-training, text-to-image fine-tuning, and Distribution Matching Distillation, arguing the routing fix is not tied to one training regime.
Why this is worth attention
The 8.75x iteration reduction is the number that earns the paper its slot. Diffusion-transformer pre-training is dominated by compute, so a drop-in change to the residual path — not a new loss, dataset, or sampler — that reaches the same FID far sooner is the kind of efficiency win labs can adopt without restructuring a pipeline. The static variant matters more than the dynamic one for practitioners precisely because it is nearly free at inference. Treat the result as evidence that the residual connection in DiT-style models was never tuned for diffusion, not as a claim of a new state of the art image model.
Limits and open questions
The strongest results are on SiT-XL/2 at ImageNet 256x256 with FID as the metric; FID rewards distribution match and can move without an obvious change in perceptual quality, so the gain needs confirmation at higher resolutions and on human preference for the text-to-image case. Storing and routing over the history of sublayer outputs adds memory and bookkeeping versus a single additive stream, and the paper’s framing emphasizes the static variant’s low cost — the dynamic, timestep-conditioned version’s overhead is the detail to scrutinize. The “8.75x fewer iterations” is an early-to-mid-training comparison; whether the advantage holds all the way to a fully converged, much longer run, and whether it transfers to architectures other than SiT, is not settled by the headline curve.
FAQ
What is Diffusion-Adaptive Routing (DAR)?
DAR is a replacement for the residual addition in a diffusion transformer. Rather than adding each sublayer’s output into a single running stream, it forms each block’s input as a learnable, timestep-adaptive weighted combination of all previous sublayer outputs, so blocks can selectively reuse or discard earlier features.
How much does DAR improve diffusion transformer quality?
On ImageNet 256x256, DAR lowers SiT-XL/2’s FID from 9.67 to 7.56 — a 2.11-point gain — and reaches the baseline’s converged quality using 8.75x fewer training iterations.
Why do standard residual connections hurt diffusion transformers?
The paper measures three problems that worsen with depth: forward magnitude inflation that dilutes deeper blocks under PreNorm, sharp backward gradient decay that under-trains early layers, and block-wise redundancy where adjacent blocks compute near-duplicate updates.
Does DAR work with REPA and other training setups?
Yes. Stacked on REPA it gives roughly 2x early-stage training acceleration, and the authors also apply it to text-to-image fine-tuning and Distribution Matching Distillation, suggesting the routing fix is largely orthogonal to those methods.
One line: the residual add in diffusion transformers was a language-model holdover, and replacing it with timestep-adaptive routing buys most of the same image quality far cheaper. Read the original paper on arXiv.