RHO:用自偏好做回溯式 harness 优化
RHO 只用过去的无标注轨迹优化 LLM 智能体的 harness,靠自验证、自一致和成对自偏好,一轮就把 SWE-Bench Pro 通过率从 59% 提到 78%,不用任何外部评分。
快速答案
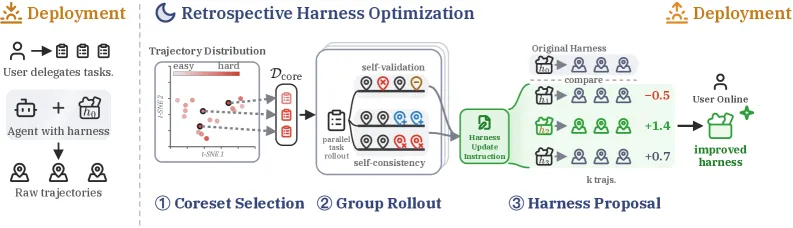
RHO 只用过去的轨迹优化智能体的 harness,不需要任何真值标签。harness 指围绕固定模型(这里是 Codex)的那层技能、工具和指令。一轮优化就把 SWE-Bench Pro 的留出集通过率从 0.59 提到 0.78,绝对涨 19 个点,全程没有外部评分。模型本身没动,所以涨幅来自模型现在所处的那套 harness,不是更强的底座。做法是:把过去的难任务挑出一小撮重做,用自验证和自一致诊断失败,生成几个候选 harness,再留下智能体在成对比较中更偏好的那个。
问题:没标签怎么调 harness
多数 harness 优化器靠一个有标注的验证集来引导搜索。它提一个改动,在留出标签上给候选打分,留下分最高的。可在真实部署里你往往拿不到这种验证集,就算收集到标签,也未必匹配未来任务的分布。你手里一直有的,是智能体跑过的任务留下的一堆轨迹。
RHO 把这些无标注轨迹变成优化信号。它赌的是:没有评分器时,智能体对自己 rollout 的判断可以当作质量的代理。这一点要和底座分开看。RHO 没让 Codex 变聪明,它换的是 Codex 手头有哪些技能和工具、以及用它们的顺序。
RHO 在没有真值时怎么跑
整条管线分三步。
coreset 选择用行列式点过程(DPP)挑出一小撮难度多样的过去任务。DPP 平衡两股力:挑难任务,同时让它们在任务空间里铺开。只按难度挑,模型会扎堆在它认为难的某一类任务上;只按覆盖挑,预算又浪费在简单任务上。论文里只有 DPP 的组合拿到最高涨幅,单看难度或单看多样性,效果连随机采样都不如。
分组 rollout 把每个 coreset 任务并行重做几遍,再抽出两路诊断信号。自验证看单条轨迹里智能体自己哪些检查没过。自一致看并行的几条轨迹在同一任务上哪里互相矛盾。两者都不需要标签,都是智能体能在自己身上算出来的信号。
best-of-N 提案从这些诊断里采样出几个候选 harness,在 coreset 上重跑,用成对自偏好把每个候选的新轨迹和旧轨迹排序。最受偏好的那个上线。采样多个再过滤很要紧:单个提案是随机的,可能什么都没改好。
优化后的 harness 里到底有什么
harness 是一个目录,装着 markdown 写的指令、技能,和可执行的工具脚本。RHO 加进去的条目专门针对原轨迹反复踩的失败模式。在 SWE-Bench Pro 上,智能体发现 Go 工具链不在默认路径里,还发现 Python 缓存目录必须在生成 diff 前清掉,否则补丁打不干净。它就写了个 check_build_and_lint 工具,定位非标准路径的工具链,标出该排除在补丁外的产物。这些是具体、能调试的修复,不是抽象的提示词微调。
关键结果
- SWE-Bench Pro,单轮: Vanilla Codex 0.59 到 RHO 0.78(涨 19 个点),无外部评分。
- 对比无反馈基线(表 1): 在匹配的智能体调用预算下,SWE-Bench Pro 上 RHO 0.78,Dynamic Cheatsheet 0.62、ReasoningBank 0.61、Sleep-time Compute 0.64。RHO 在 Terminal-Bench 2(0.76 对 vanilla 0.71)和 GAIA-2(0.37 对 vanilla 0.29)上也赢。基线只改记忆或文本技能,RHO 改技能和工具。
- 对比用标签的 Meta-Harness(表 2): 单轮匹配预算下 Meta-Harness 在 SWE-Bench Pro 只到 0.62,RHO 是 0.78。跑到 10 轮、约 3 倍算力时 Meta-Harness 到 0.80,但仍依赖 RHO 从不碰的留出标签。
- 诊断消融(表 4): 去掉自一致,SWE-Bench Pro 塌到 0.56,低于 0.59 的 vanilla 基线;去掉自验证是 0.70;不做诊断直接喂原始轨迹是 0.60。两路诊断信号都吃重,SWE-Bench Pro 上自一致更关键。
- best-of-N 一致性(表 3): SWE-Bench Pro 上三个候选 harness 的均分是 0.79,最低 0.73,连最差的候选也比 vanilla 强。被选中的候选(0.78)未必是单项最高分,但选择能稳定避开最差的那个。
自偏好信号为什么站得住
消融的老实读法是:自一致在挑大梁,去掉它性能掉到 vanilla 基线以下。这说明信号是真的,不是白捡的便宜。智能体把一个难任务重做几遍,rollout 互相矛盾时,这种矛盾在没有答案的情况下也能定位 harness 哪里弱。自偏好再把提案过一遍,让坏的 harness 改动上不了线。行为分析也对得上:用了 RHO 之后,智能体在 SWE-Bench Pro 上更频繁地验证自己的工作,在长流程会话里保持更高准确率,涨幅也主要集中在这里。
局限与存疑
0.59 到 0.78 这个头条是单轮、单基准、固定 Codex 智能体的结果;Terminal-Bench 2(涨 5 点)和 GAIA-2(涨 8 点)的提升真实但小得多,所以 SWE-Bench Pro 是有利样本,不是常态。自偏好是智能体给自己打分,有风险:它可能奖励模型喜欢、却未必能泛化的改动;表 3 里被选中的候选本就不总等于真正的最高分。算力也不白来:一次 RHO 跑 103 次智能体调用,单轮 Meta-Harness 只要 41 次,RHO 用更多推理换来不依赖标签。整套方法还假设底座够强、自一致才有信号;在更弱的模型上,rollout 因为别的原因互相矛盾,诊断可能把方向带偏。论文没测这条边界。
常见问题
RHO(回溯式 harness 优化)是什么?
RHO 是一种自监督方法,只用过去的无标注轨迹来改进 LLM 智能体的 harness,也就是它的技能、工具和指令。它挑出一小撮难度多样的过去任务,用自验证和自一致诊断失败,生成候选 harness,再上线智能体在成对比较中更偏好的那个。一轮就把 SWE-Bench Pro 通过率从 0.59 提到 0.78。
RHO 需要真值标签才能改进 harness 吗?
不需要,这正是它的核心。RHO 用智能体对自身 rollout 的诊断信号和成对自偏好,顶替了有标注的验证集。SWE-Bench Pro 涨到 0.78 全程无外部评分,而用标签的对照方法 Meta-Harness 要靠留出标签才能摸到相近的上限。
RHO 让底座模型变聪明了吗?
没有。全程是固定的 Codex 智能体。RHO 只改外围的 harness:加 check_build_and_lint 这类工具,加针对过去失败模式的技能。0.59 到 0.78 的涨幅归功于新 harness,不是新的预训练或更大的模型。
RHO 和 Meta-Harness 在带验证反馈的智能体调用上怎么比?
单轮匹配预算下,Meta-Harness 在 SWE-Bench Pro 是 0.62,RHO 是 0.78;Meta-Harness 用约 41 次智能体调用,RHO 用 103 次。跑 10 轮、约 3 倍算力时 Meta-Harness 到 0.80,但仍要 RHO 不用的留出标签。
RHO 去掉自一致会怎样?
SWE-Bench Pro 掉到 0.56,低于 0.59 的 vanilla 基线,所以在那里去掉自一致会让优化反而有害。去掉自验证是 0.70,不做诊断直接喂原始轨迹是 0.60。两路诊断信号都不可或缺,不是可有可无。
一句话:RHO 用自一致和自偏好,从无标注的过去轨迹里调 harness,以多花的推理换来不依赖标签的运行。阅读 arXiv 原文。