AI Agents · Reinforcement Learning · Retrieval-Augmented Generation
SAAS: Teaching Search Agents When to Stop Searching
SAAS uses self-aware RL to cut a Qwen2.5-7B search agent's average queries from 2.19 to 0.97 per question, while keeping accuracy near the best baseline (48.7% vs 49.8%).
Quick answer
SAAS (Self-Aware Agentic Search) is a reinforcement learning recipe from Xiamen University and Jilin University that stops search agents from searching when they do not need to. On Qwen2.5-7B-Instruct it drops the average number of retrieval calls from 2.19 (the HiPRAG baseline) to 0.97 per question, while average answer accuracy stays at 48.7% versus the baseline’s 49.8%. The headline is efficiency: roughly half the search budget for almost the same accuracy.
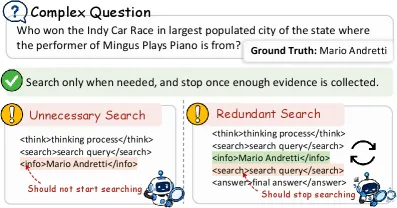
The problem it targets is “over-search”: agents that fire off a retrieval even when their parametric knowledge already covers the question, or keep querying after they have collected enough evidence. SAAS teaches the model where its own knowledge boundary sits, then penalizes only the searches that cross it needlessly.
The two kinds of over-search
The paper splits wasteful retrieval into two failure modes, and that split drives the whole design:
- Unnecessary search: the model triggers a search even though its internal (parametric) knowledge would have answered correctly. This is the “I already knew that” failure.
- Redundant search: the model keeps issuing queries after it has already gathered sufficient external evidence. This is the “stop digging” failure.
Both inflate latency and API cost without improving answers, and existing efficiency-focused agents like HiPRAG still over-search on essentially every question in the authors’ measurement (a question-level over-search ratio of 100%). The interesting move is that SAAS does not just slap a flat penalty on search count. That tends to make models cowardly and hurt hard multi-hop questions. Instead it tries to locate the minimum sufficient amount of search per question.
How SAAS works
Three components stack together:
-
Search boundary modeling. For each training question, SAAS runs two contrasting rollouts (one with search disabled, one with search enabled) to infer whether that question actually needs external evidence under the current policy. Because the policy keeps changing during RL, the boundary is re-estimated as training evolves rather than fixed up front.
-
Boundary-aware reward. This converts the boundary signal into trajectory-level shaping. It applies zero tolerance to unnecessary searches (any search on a question the model could already answer is penalized) but only penalizes redundant searches beyond the minimum-sufficient threshold for questions that genuinely need retrieval. So the reward distinguishes “should not have searched at all” from “searched one too many times.”
-
Stage-wise optimization. A two-stage curriculum first lets the model acquire reasoning and search capability, and only then turns on the efficiency regularization. The ordering matters: if you optimize for fewer searches too early, the model games the reward by refusing to search and tanks accuracy on hard questions. Capability first, frugality second.
Key results
- Search count roughly halved. On Qwen2.5-7B-Instruct, average search count falls to 0.97 per question versus 2.19 for HiPRAG; on Qwen2.5-3B-Instruct it is 1.13. The authors report baselines needing 1.69 to 2.19 searches.
- Accuracy held, not sacrificed. Average accuracy on the 7B model is 48.7%, within about one point of HiPRAG’s 49.8% — so the search budget is cut nearly in half for a negligible accuracy change.
- Over-search ratios collapse. The question-level over-search ratio drops to 45.9% (from 100% for HiPRAG), and the step-level redundant-search ratio falls to 6.3% (from 19.5%).
- Holds across model families. Results are reported on Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct, and Qwen3-4B-Instruct, across seven QA benchmarks: TriviaQA, PopQA, NQ, HotpotQA, 2WikiMultiHopQA, MuSiQue, and Bamboogle.
My read: the accuracy story is “comparable, not better,” and that is the right framing. SAAS is not pitching a smarter answerer. It is pitching an equally good answerer that costs half as much to run. For anyone paying per retrieval call or per token of context, that is the number that matters.
Limits and open questions
- Text-only evidence. The evaluation is confined to unimodal textual retrieval. The authors argue the framework is modality-agnostic in principle, but images, tables, and structured databases are left as future work — so the efficiency claims are unverified outside text QA.
- Accuracy is not improved. SAAS trades search budget for cost, not for better answers. If your bottleneck is answer quality on hard multi-hop questions, this is the wrong tool.
- Boundary estimation cost. Inferring the search boundary via contrasting search-on/search-off rollouts adds training-time overhead, and the paper’s gains are about inference efficiency, not training efficiency.
- Baseline scope. The strongest comparison is against HiPRAG; how SAAS stacks up against the newest frontier agentic-search systems on the same fixed retrieval corpus is worth scrutinizing before assuming the lead generalizes.
FAQ
What does SAAS actually reduce compared to normal search agents?
It reduces the number of retrieval calls, not the answer accuracy. On Qwen2.5-7B-Instruct it cuts average searches from 2.19 to 0.97 per question and pushes the question-level over-search ratio from 100% down to 45.9%, while accuracy stays around 48.7%.
How is SAAS different from just penalizing search count?
A flat penalty makes the agent search-shy and hurts hard multi-hop questions. SAAS instead models a per-question knowledge boundary, penalizes unnecessary searches with zero tolerance but only charges for redundant searches past a minimum-sufficient threshold, and stages training so reasoning capability is learned before efficiency is enforced. That ordering avoids the reward hacking where the model just stops searching.
Should I use SAAS if I want higher QA accuracy?
No. SAAS is an efficiency method. It keeps accuracy roughly level (48.7% vs 49.8% baseline on 7B) while halving search cost. If your goal is better answers rather than cheaper ones, look elsewhere; if you pay per retrieval call, SAAS is directly relevant.