Diffusion Models · World Models · Efficient AI
Stream-T1: Test-Time Scaling for Streaming Video Generation
Stream-T1 adds test-time search to streaming video generation without retraining, lifting VideoAlign motion quality from 0.350 to 0.629 at 5s and cutting the drift that wrecks 30-second clips.
Quick answer
Stream-T1 makes autoregressive streaming video models generate longer, more stable clips by searching at inference time instead of retraining. On 5-second clips it raises VideoAlign motion quality from 0.350 to 0.629 and video quality from 0.285 to 0.426 over the LongLive baseline, while VBench aesthetic quality climbs from 65.28 to 65.98. The payoff is largest on 30-second clips, where the baseline’s motion quality is roughly zero (-0.002) and Stream-T1 lifts it to 0.226 — the regime where streaming models normally fall apart.
The problem with streaming video models
Streaming video generators produce a clip chunk by chunk, each chunk conditioned on the ones before it through a KV cache. This is what lets them run in real time and in principle generate arbitrarily long video. It is also their weakness: errors compound. A small artifact in chunk three biases chunk four, the subject slowly morphs, the background drifts, and by 30 seconds the clip has visibly degraded. The usual fix is more training — better data, longer context, RL on the generator. Stream-T1 refuses that and asks a different question: given a frozen streaming model, how much can you buy back at test time by spending extra compute on search?
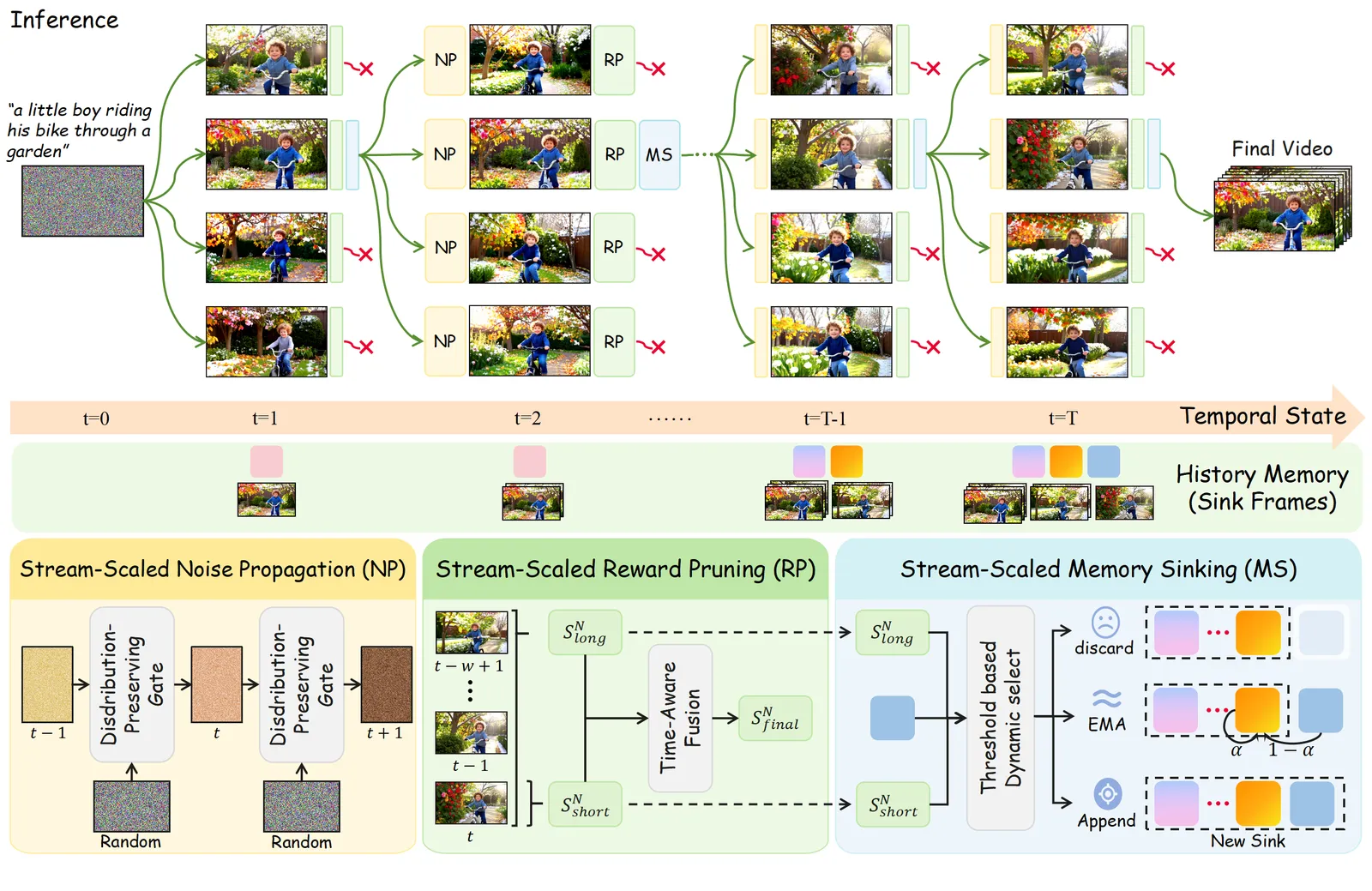
How Stream-T1 searches at inference
The method runs three coordinated tricks at the chunk level, all training-free.
Stream-scaled noise propagation initializes each new chunk’s latent by spherically interpolating the noise from the preceding chunk rather than sampling fresh noise. An interpolation factor (in the range -1 to 1) controls how strongly the previous chunk’s trajectory carries forward, which keeps motion continuous instead of restarting every chunk.
Stream-scaled reward pruning is the core of the test-time scaling. Stream-T1 expands several candidate continuations per chunk and prunes them with a combined score: a short-score from image rewards for per-frame quality and a long-score from video rewards computed over a sliding window of 10 chunks for temporal coherence. A dynamic threshold shifts weight between the two as the clip grows, so early chunks favor frame quality and later chunks favor staying consistent with history.
Stream-scaled memory sinking decides what to do with KV-cache entries evicted from the window (size 9, with an attention-sink size of 3). Instead of always discarding them, it detects semantic boundaries and routes evicted context down one of three paths — discard, an EMA-smoothed sink, or a direct append — so the model keeps relevant long-term memory without letting stale context poison new frames.
The honest framing: this is beam search over video chunks with video-specific scoring and memory handling, not a new generator. That is exactly why it is interesting — it is a wrapper any streaming model can wear.
Key results
All numbers are from the paper’s two benchmarks: 946 VBench prompts at 5 seconds and 128 MovieGen prompts at 30 seconds, 16 FPS, 832x480, baseline LongLive.
- 5s motion quality: VideoAlign MQ rises from 0.350 to 0.629; video quality (VQ) from 0.285 to 0.426; text alignment (TA) from 1.193 to 1.305.
- 30s motion quality: VideoAlign MQ goes from -0.002 to 0.226 and VQ from -0.169 to -0.073 — the long-clip drift the method is built to fight.
- VBench at 30s: subject consistency 97.90 to 98.43, motion smoothness 98.78 to 99.03, aesthetic quality 61.56 to 62.11.
- VBench at 5s: the surface metrics barely move (motion smoothness 99.12 to 99.15, subject consistency 97.00 to 97.25), which is the more revealing result — see below.
How to read these numbers honestly
The VideoAlign gains are large and the VBench gains are tiny, and that gap is the real story. VBench’s consistency and smoothness metrics already sit at 97-99 on the baseline, so there is almost no headroom — a +0.03 on motion smoothness is noise, not progress. The reward-model metrics (VideoAlign), which actually track perceived quality and alignment, are where Stream-T1 moves the needle: roughly +0.28 absolute on 5s motion quality. Read the VBench table as “doesn’t break what already works” and the VideoAlign table as the genuine win. The largest relative jumps appear at 30s precisely because that is where the frozen baseline is failing.
Limits and open questions
Test-time search is not free. Expanding and scoring multiple candidates per chunk multiplies inference compute, and the paper’s framing is real-time streaming — there is tension between “search more candidates” and “stay real-time” that the gains alone do not resolve. The improvements are also reported against a single baseline (LongLive) on two benchmarks; whether the noise/reward/memory recipe transfers to other streaming backbones, or holds past 30 seconds and beyond 832x480, is unproven here. And because the win rides on reward models, it inherits their blind spots: optimizing VideoAlign hard can drift toward what the reward model likes rather than what looks right, a failure mode reward pruning does not fully escape. Several knobs (interpolation factor, EMA decay, the dynamic threshold) are hyperparameters that likely need tuning per model.
FAQ
What is Stream-T1 in one sentence?
Stream-T1 is a training-free, test-time scaling framework that wraps a frozen streaming video generator and uses chunk-level search — noise propagation, reward pruning, and memory sinking — to produce longer, more stable clips.
How much does Stream-T1 actually improve quality?
On 5-second clips it raises VideoAlign motion quality from 0.350 to 0.629 and video quality from 0.285 to 0.426 over LongLive. Standard VBench consistency metrics move only slightly because they were already near-saturated at 97-99.
Does Stream-T1 require retraining the video model?
No. Stream-T1 spends extra compute at inference instead of training. It treats the generator as frozen and searches over candidate chunks, which is why it can in principle sit on top of different streaming models.
Why does Stream-T1 help more on 30-second videos?
Streaming models accumulate error over time, so a 30-second clip drifts far more than a 5-second one. Stream-T1’s reward pruning and memory sinking directly fight that drift, so its relative gains — motion quality from roughly zero to 0.226 — are largest on long clips.
What is the catch with Stream-T1?
Searching multiple candidates per chunk raises inference cost, the gains are shown against one baseline on two benchmarks, and leaning on reward models risks optimizing for the scorer rather than true visual quality.
Bottom line: Stream-T1 shows streaming video models leave real headroom on the table that pure test-time search reclaims — biggest where long clips drift. Read the original paper on arXiv.