Text-to-Image · Diffusion Models · Fine-Tuning & Adaptation
Flow-OPD: On-Policy Distillation Fixes Reward Conflict in Text-to-Image RL
Flow-OPD trains one specialist teacher per reward, then distills them on-policy into one SD 3.5 student — lifting GenEval 0.63 to 0.92 and OCR 0.59 to 0.94 without the aesthetic collapse of multi-reward GRPO.
Quick answer
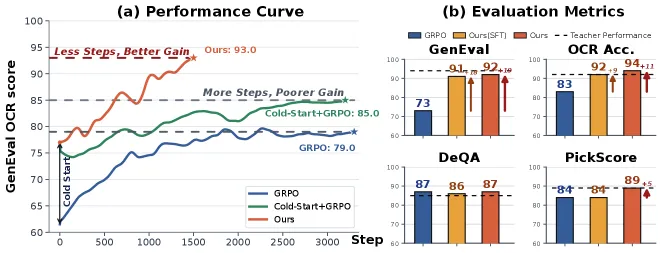
Flow-OPD raises GenEval from 0.63 to 0.92 and OCR accuracy from 0.59 to 0.94 on Stable Diffusion 3.5 Medium, while keeping aesthetic and human-preference scores intact. It does this by refusing to train one model on many rewards at once. Instead it trains a separate GRPO specialist teacher for each reward (prompt alignment, text rendering, aesthetics), then distills all of them on-policy into one student. On the combined GenEval+OCR reward curve in the paper, the student climbs to roughly 93 while vanilla GRPO stalls around 79.
The reward-conflict problem it actually solves
The honest framing the abstract underplays: this is a paper about reward interference, not about a new sampler. When you run GRPO on a flow-matching text-to-image model with several rewards summed together, the rewards fight. Pushing OCR (legible text in images) drags down prompt alignment; pushing aesthetics lets the model reward-hack into over-saturated, samey images. Vanilla multi-reward GRPO converges early to a mediocre compromise — the paper shows it plateauing near 79 on the combined reward while the proposed method reaches ~93.
Flow-OPD’s bet is that you should not ask one policy to optimize conflicting objectives simultaneously. Decompose first, recombine later.
How the two-stage method works
Stage one is specialist teachers. Each reward gets its own GRPO fine-tune of the base flow model, so a teacher can chase OCR hard without worrying about wrecking aesthetics. This is the cheap, well-understood part — single-reward GRPO is stable precisely because there is no conflict.
Stage two is multi-teacher on-policy distillation, and it is the real contribution. The student generates its own denoising trajectories (on-policy), and at each timestep the relevant teacher supplies a dense supervisory signal on the predicted vector field — not a sparse final-image reward. Because flow matching predicts a velocity field along an ODE path, the teacher and student can be compared step by step along the trajectory the student actually visits. That dense, on-policy signal is far more sample-efficient than scalar RL reward, which only arrives at the end of generation.
Why Manifold Anchor Regularization matters
Manifold Anchor Regularization (MAR) is the part that stops the student from drifting off the natural-image manifold. The authors freeze a teacher tuned for visual quality and penalize the student’s vector field with a time-weighted L2 distance to that frozen teacher. The effect: the student can absorb alignment and OCR skills from the other teachers while an anchor keeps its trajectories close to high-fidelity image space. This is their answer to RL’s classic failure mode — reward hacking that boosts a metric while quietly degrading how images look.
Key results
- GenEval: 0.63 → 0.92 on Stable Diffusion 3.5 Medium (the merged Flow-OPD student).
- OCR accuracy: 0.59 → 0.94, the largest single jump, reflecting the dedicated text-rendering teacher.
- DeQA 4.35 and PickScore 23.08 for the merged student, versus 4.07 and 21.64 for the SD-3.5-M baseline — quality and human preference go up, not down, which is the whole point of MAR.
- Combined-reward training curve: Flow-OPD reaches ~93 while vanilla GRPO converges prematurely near 79.
- Generalization (T2I-CompBench): reported state-of-the-art on compositional axes — Color 0.8298, Shape 0.6292, 3D-Spatial 0.4565, Numeracy 0.6837.
Limits and open questions
The cost moves rather than disappears. You now train N specialist teachers plus a distillation stage, so the total compute is higher than a single GRPO run even if each teacher is stable. The paper validates on one base model (SD-3.5 Medium); whether the gains hold on larger flow models or on video flow matching is untested here. The reward set is also hand-picked — GenEval, OCR, aesthetics — and adding a new objective means training and distilling yet another teacher, which does not obviously scale to dozens of rewards. Finally, the OCR jump is so large partly because the SD-3.5-M baseline is weak at text; readers should not read 0.94 as a universal text-rendering claim.
FAQ
What does Flow-OPD do differently from GRPO?
Flow-OPD avoids optimizing several conflicting rewards in one policy. It trains one GRPO specialist per reward, then distills them on-policy into a single student with dense per-timestep supervision, whereas GRPO applies all rewards at once and gets a worse compromise.
How much does Flow-OPD improve text-to-image quality?
On Stable Diffusion 3.5 Medium it lifts GenEval from 0.63 to 0.92 and OCR accuracy from 0.59 to 0.94, while DeQA and PickScore also rise, indicating aesthetics were preserved rather than sacrificed.
What is Manifold Anchor Regularization in Flow-OPD?
It is a time-weighted L2 penalty that keeps the student’s vector field close to a frozen quality-tuned teacher, anchoring generated trajectories to the natural-image manifold so reinforcement signals cannot reward-hack at the expense of visual fidelity.
Is Flow-OPD only for flow matching models?
The method is built around flow matching’s velocity-field trajectories, which is what makes dense on-policy distillation possible; the paper demonstrates it on a flow-matching diffusion model (SD-3.5 Medium) and does not claim coverage of other generator families.
One line: split conflicting rewards into specialist teachers, then distill them on-policy along the flow trajectory — and anchor the student so it does not cheat. Read the original paper on arXiv.