LLM Reasoning · Efficient AI · Fine-Tuning & Adaptation
ThoughtFold: Cutting 56% of Reasoning Tokens Without Losing Accuracy
ThoughtFold trims the redundant reasoning of DeepSeek-R1-Distill-Qwen-7B by about 56% of tokens while keeping accuracy on AIME, MATH-500, and GPQA-Diamond intact, using a masked preference objective.
Quick answer
ThoughtFold is a fine-tuning recipe that makes reasoning models stop padding their chains-of-thought with redundant steps. On DeepSeek-R1-Distill-Qwen-7B it cuts average token consumption by roughly 56% while holding accuracy on AIME 2024, MATH-500, and GPQA-Diamond at the same level as the original verbose model. The trick is not a length penalty bolted onto reinforcement learning; it is a preference objective trained on the model’s own correct traces, where the “preferred” answer is the same solution with the dead weight folded out.
The honest framing: this is a token-efficiency paper, not a capability paper. ThoughtFold does not make a 7B model smarter. It makes a model that already gets the answer get there in half the words. If your bottleneck is inference cost or latency on long reasoning traces, that is exactly the lever you want. If you are chasing accuracy on the hardest problems, this is not the paper.
The overthinking problem, concretely
Large reasoning models trained with verifiable rewards (RLVR) learn to think out loud, and they overdo it. A correct AIME solution from DeepSeek-R1-Distill routinely re-derives the same intermediate fact three times, second-guesses a step it already nailed, and explores branches it never needed. Every one of those tokens costs money and wall-clock time at serving. The accuracy is fine; the verbosity is the tax.
Prior fixes mostly attack this from the outside. Length-penalty RL methods add a term that punishes long outputs, which is blunt: it can clip genuinely necessary reasoning to chase a shorter total. Plain DPO on hand-curated short-vs-long pairs needs an external notion of what “short enough” means. ThoughtFold’s bet is that the redundancy is internal and identifiable. You can look inside a correct trace and tell which sentences carried the logic and which were filler.
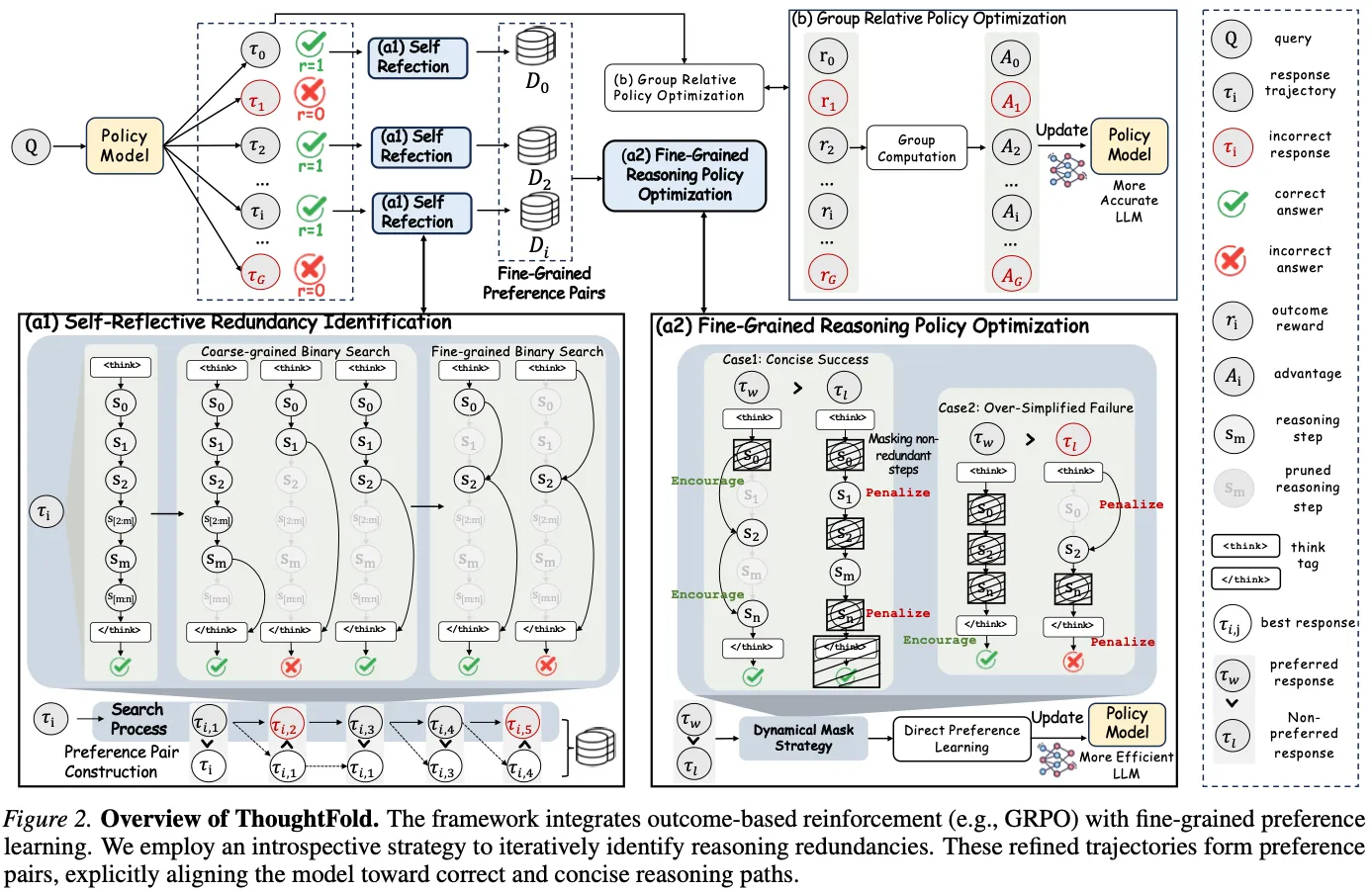
How ThoughtFold folds a chain
The method runs a two-phase introspective pruning pass over the model’s correct trajectories, then turns the result into preference pairs.
Tail truncation. Given a correct chain-of-thought, it binary-searches over the chain length to find the shortest prefix that still produces the right answer. A lot of reasoning models keep “reasoning” well past the point where the answer is already determined; tail truncation finds where the thinking actually finished.
Internal folding. Within the surviving prefix, it uses attention signals to score each sentence’s importance and prunes the low-importance ones, splicing the essential segments together directly. This is the “folding”: a meandering path collapsed into the load-bearing steps.
Note that the pruning is allowed to fail. When you cut too aggressively and break the logic, you get an over-simplified trajectory that now gets the answer wrong. ThoughtFold keeps both outcomes and builds masked DPO pairs: the “concise success” (redundancy removed, answer still correct) is the preferred response, and the “over-simplified failure” (essential logic broken) is the rejected one. The masking confines the preference signal to the edited spans so the objective explicitly penalizes redundant exploration without punishing the reasoning that mattered. That contrast, where concise-but-right beats short-but-wrong, is what stops the model from collapsing into uselessly terse answers.
Key results
- ~56% fewer tokens on DeepSeek-R1-Distill-Qwen-7B, averaged across the evaluation suite, with accuracy preserved at state-of-the-art levels versus recent efficient-reasoning methods. This is the headline and the most defensible claim.
- Evaluated on AIME 2024, MATH-500, and GPQA-Diamond, a math-heavy plus graduate-science mix, so the efficiency gain is shown on genuinely hard reasoning, not just easy prompts where short answers are trivial.
- Baselines include length-penalty RL, RLVR, and DPO-style approaches; ThoughtFold’s pitch is matching their accuracy at a better token budget rather than trading accuracy for brevity.
- Self-supervised pair construction: the preference data comes from the model’s own correct rollouts plus the prune-and-check loop, so there is no human labeling of “good” short answers.
Treat the per-benchmark accuracy and exact token counts as something to confirm in the paper’s tables. The abstract and repo headline the aggregate 56% figure, and that is the number to trust without the rendered tables in hand.
Limits and open questions
The reported gains center on DeepSeek-R1-Distill-Qwen-7B; the paper mentions larger 14B/32B variants, but the cleanest evidence is at 7B, so how the 56% holds as models scale is the open question. The attention-guided importance score is a heuristic. It identifies sentences that look low-attention, which is correlated with but not identical to logically redundant. There is real risk of folding out a step that is rarely attended to yet occasionally load-bearing on out-of-distribution problems; the over-simplified-failure negatives are meant to guard against this, but they only cover failures the prune loop happened to surface. Finally, “preserves accuracy” is an aggregate claim; on a specific hard benchmark a small drop could hide inside the average. Anyone deploying this should re-measure accuracy per task, not trust the headline.
FAQ
What does ThoughtFold actually change versus a length penalty?
A length penalty pushes the whole output shorter and can amputate necessary reasoning to hit a token target. ThoughtFold instead identifies which specific spans are redundant via tail truncation and attention-guided folding, then trains a masked preference objective where the win condition is “shorter AND still correct.” It optimizes for the right reason rather than for raw brevity.
Does ThoughtFold make DeepSeek-R1-Distill-Qwen-7B more accurate?
No, and it does not claim to. It keeps accuracy roughly flat on AIME 2024, MATH-500, and GPQA-Diamond while removing about 56% of the tokens. The product is cheaper, faster inference at matched quality, not a smarter model.
Do I need human-labeled data to use ThoughtFold?
No. The preference pairs are built automatically from the model’s own correct trajectories: tail truncation and internal folding generate the concise “preferred” trace, and over-aggressive pruning that breaks the answer becomes the “rejected” trace. No external short-answer annotation is required.