ThoughtFold:推理链砍掉 56% token 而不掉点
ThoughtFold 用掩码偏好学习,把 DeepSeek-R1-Distill-Qwen-7B 的冗余推理平均压掉约 56% 的 token,准确率基本不变。
快速答案
ThoughtFold 是一套微调方法,专门治推理模型「话痨」的毛病:把思维链里的冗余步骤折叠掉。在 DeepSeek-R1-Distill-Qwen-7B 上,它把平均 token 消耗砍掉约 56%,而在 AIME 2024、MATH-500、GPQA-Diamond 上的准确率与原始的啰嗦版本基本持平。它的关键不是在强化学习上外挂一个长度惩罚,而是用模型自己的正确推理轨迹构造偏好数据:把同一条正确解里的「废话」折叠掉之后的版本,作为「更优」答案。
说句实在话:这是一篇省 token 的论文,不是一篇提能力的论文。ThoughtFold 不会让一个 7B 模型变聪明,它只是让一个本来就能答对的模型用一半的字数答对。如果你的瓶颈是长推理轨迹的推理成本和延迟,这正是你要的杠杆;如果你想的是在最难的题上提准确率,这篇可以略过。
「过度思考」到底是什么问题
用可验证奖励(RLVR)训出来的大推理模型学会了把思考过程念出来,而且念过头了。DeepSeek-R1-Distill 解一道 AIME 题,经常把同一个中间结论推导三遍,对一个早就做对的步骤反复自我怀疑,还会去探索根本用不上的分支。这些 token 在部署时全是真金白银和墙上时钟时间。准确率没问题,啰嗦才是真正的税。
之前的方案大多从外部下手。长度惩罚类的强化学习方法,加一项惩罚长输出,这很粗暴:为了把总长度压下来,它可能把真正必要的推理也一起剪掉。普通的 DPO 在人工挑的「长短对」上训,又需要一个外部标准来定义「多短才算够短」。ThoughtFold 押的是另一个判断:冗余是内生且可识别的。你可以钻进一条正确轨迹里,分辨出哪些句子承担了逻辑、哪些只是填充。
ThoughtFold 怎么折叠一条推理链
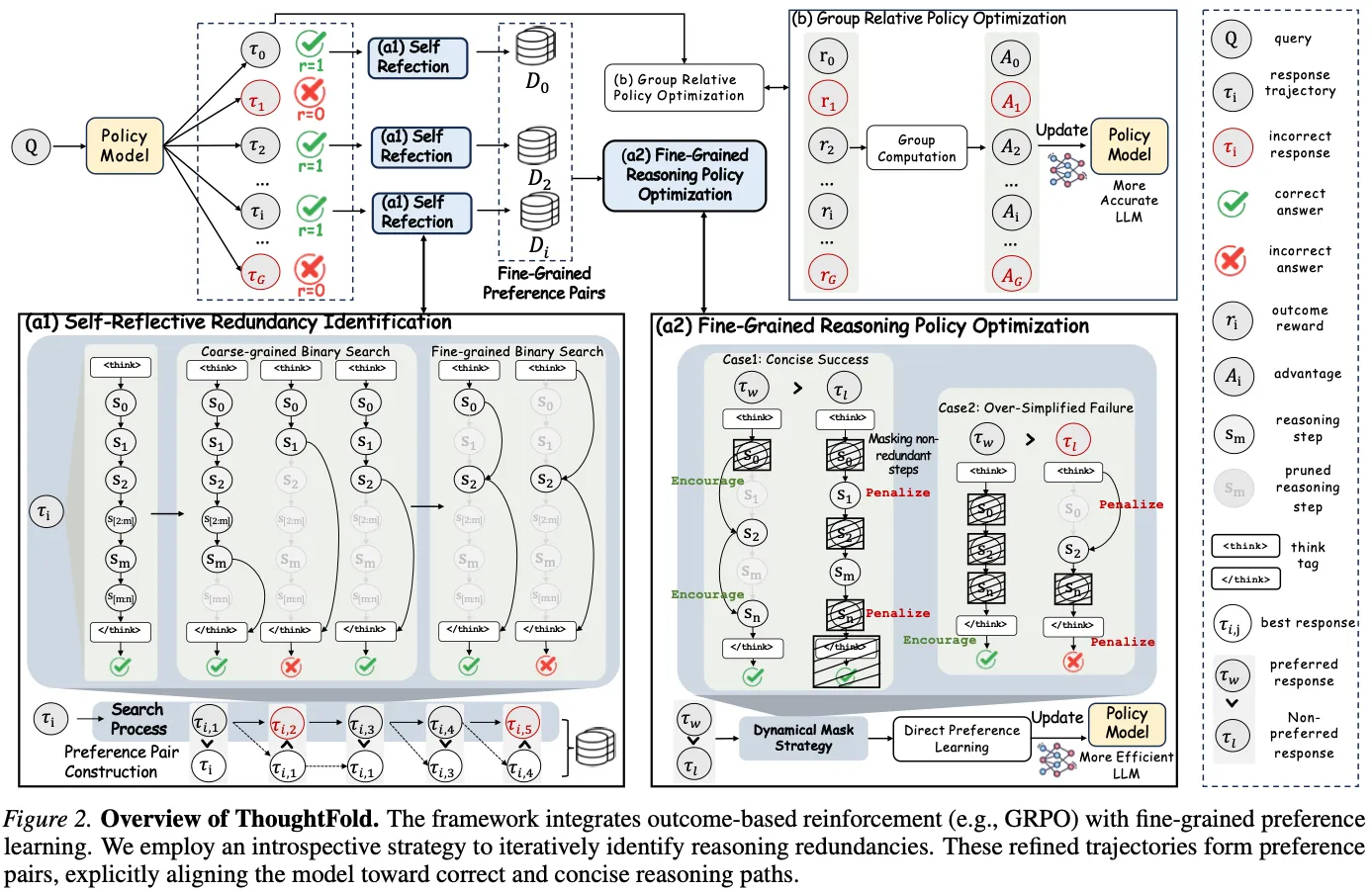
方法对模型的正确轨迹做两阶段的内省式剪枝,再把结果转成偏好对。
尾部截断(Tail truncation)。 给定一条正确的思维链,在链长上做二分查找,找出仍能得到正确答案的最短前缀。很多推理模型在答案其实已经确定之后还在继续「推理」;尾部截断负责找出思考实际结束的那个点。
内部折叠(Internal folding)。 在保留下来的前缀里,用注意力信号给每个句子的重要性打分,剪掉低重要性的句子,再把核心片段直接拼接起来。这就是「折叠」——把一条绕来绕去的路径,压成真正承重的几步。
关键在于,剪枝是被允许失败的。当你剪得太狠、把逻辑剪断了,就得到一条过度简化、现在反而答错的轨迹。ThoughtFold 把两种结果都留下,构造掩码 DPO 对:「精简成功」(去掉冗余、答案仍对)作为被偏好的回复,「过度简化失败」(核心逻辑被剪断)作为被拒绝的回复。掩码把偏好信号限制在被编辑的片段上,于是这个目标明确地惩罚冗余探索,而不会惩罚真正起作用的推理。正是「精简且正确 优于 简短却错误」这个对照,阻止了模型坍缩成那种短到没用的答案。
关键结果
- DeepSeek-R1-Distill-Qwen-7B 上 token 平均减少约 56%,在整个评测集上平均,准确率保持在与近期高效推理方法相当的最优水平。这是头条数字,也是最站得住的结论。
- 在 AIME 2024、MATH-500、GPQA-Diamond 上评测:数学为主、外加研究生级科学题的组合,说明效率提升是在真正困难的推理上验证的,而不是那种短答案天然就行的简单题。
- 对比基线包括长度惩罚强化学习、RLVR、以及 DPO 类方法;ThoughtFold 的卖点是在更省的 token 预算下追平它们的准确率,而不是用准确率换简短。
- 自监督构造偏好对:偏好数据来自模型自己的正确采样加上「剪枝-验证」循环,不需要人工标注「好的短答案」。
每个 benchmark 的逐项准确率与精确 token 数,建议以论文表格为准核对。摘要和仓库突出的是 56% 这个聚合数字,在拿不到渲染表格的情况下,这是最可信的一个数。
局限与存疑
报告的增益集中在 DeepSeek-R1-Distill-Qwen-7B;论文提到 14B/32B 的更大变体,但最干净的证据在 7B,所以 56% 随规模放大后是否还成立,是个未决问题。注意力引导的重要性打分本质是启发式:它识别的是「看起来」低注意力的句子,这与「逻辑上冗余」相关但并不等同。确实存在风险:折叠掉一个平时很少被注意、但在分布外问题上偶尔承重的步骤;那些「过度简化失败」的负样本本意是防这个,但它们只覆盖剪枝循环恰好暴露出来的失败。最后,「保持准确率」是个聚合说法;在某个特定难 benchmark 上,小幅下降可能藏在平均值里。要部署的人应该逐任务重新测准确率,别只信头条数字。
常见问题
ThoughtFold 和长度惩罚到底差在哪?
长度惩罚把整个输出往短里压,为了凑 token 目标可能把必要推理也砍掉。ThoughtFold 则是先通过尾部截断和注意力折叠定位出具体哪些片段是冗余的,再训一个掩码偏好目标,获胜条件是「更短并且仍然正确」。它为正确的理由优化,而不是为单纯的简短。
ThoughtFold 会让 DeepSeek-R1-Distill-Qwen-7B 更准吗?
不会,它也没这么宣称。它在 AIME 2024、MATH-500、GPQA-Diamond 上让准确率大致持平,同时砍掉约 56% 的 token。产物是同等质量下更便宜、更快的推理,而不是更聪明的模型。
用 ThoughtFold 需要人工标注数据吗?
不需要。偏好对是从模型自己的正确轨迹自动构造的:尾部截断和内部折叠生成精简的「被偏好」轨迹,剪得过狠、把答案剪错的版本则成为「被拒绝」轨迹。全程不需要外部的短答案标注。