WALL-WM:按事件边界切分的世界动作模型
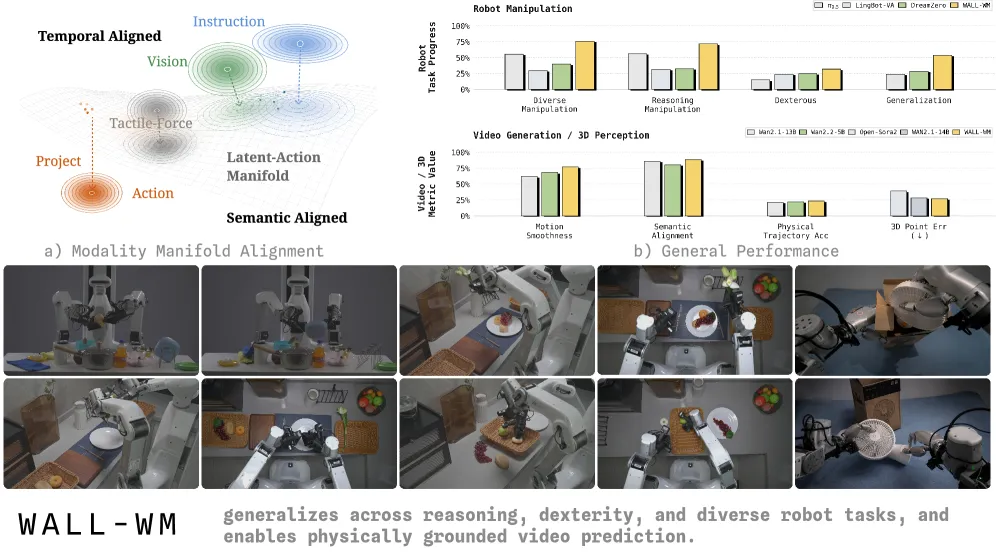
WALL-WM 把 VLA 预训练围绕语义动作事件组织,而非定长动作块。事件模式在真机多样化操作上拿到 75.86 任务进度分,pi0.5 是 55.64。
快速答案
WALL-WM 是 X-Square-Robot 的世界动作模型,把视觉-语言-动作策略训练在语义动作事件上,而不是定长动作块。真机多样化操作上,它的事件模式平均拿到 75.86 任务进度分,pi0.5 是 55.64,DreamZero 39.97,LingBot-VA 29.71。差距最大的是泛化:事件模式 53.75,同一模型当作定长统一策略从零训练只有 18.50。提升来自监督信号怎么切,而非更大的底座。两种模式共用一个事件预训练的去噪器。
WALL-WM 要解决的粒度错配
多数世界动作模型从视频或多模态底座起步,再用当前帧和指令预测定长动作块。论文认为”块”这个单位选错了。语言描述目标和事件,视觉沿连续场景动态演变,动作跑在控制级时间尺度上。把三者塞进同一个定长窗口,VLA 训练就退化成短时程的相关性拟合,还会用块级的动作捷径覆盖掉预训练的视觉语义先验。WALL-WM 改成在同一个语义事件边界上切视频、动作和字幕,让”字幕到视频/动作”的目标定义清楚。
事件锚定怎么做
原子单位是一个语义连贯的动作事件。数据用四级层次字幕(任务、子任务、动作、片段)构建,再用聚类均衡采样,避免长尾行为被淹没。模型是一个层耦合的视频-动作去噪器:给定多视角观测和下一事件指令,它联合去噪未来视频隐变量和末端执行器动作 token。跨视角注意力用了一个视锥掩码:两个视角 token 只有在各自反投影的视锥在两台相机前方共享 3D 区域时才能互相注意,这个几何先验给了模型多视角一致性。
一个底座,两种推理模式
同一个事件预训练模型有两种跑法。事件模式读下一事件描述,输出变长执行块,块长按事件而非时钟决定。统一模式保留传统的定长块接口,办法是接一个 Qwen3.5-9B 的 VLM 配 Staircase 解码,用一小段连续隐式推理状态来条件化动作路径,同时保持梯度连续。下面的数字把两者分开:WALL-WM-E 是事件模式,WALL-WM-U-Scratch 是不带事件配方、从零训练的统一接口。
关键结果
- 多样化操作(真机任务进度分): 事件模式 75.86,U-Scratch 63.00,pi0.5 55.64,DreamZero 39.97,LingBot-VA 29.71。
- 推理操作: 事件模式 71.60,pi0.5 56.40,U-Scratch 59.50。“按顺序按按钮”从 18(基线)涨到 64(事件)。
- 灵巧操作: 事件模式 32.00,U-Scratch 31.25,LingBot-VA 24.00,pi0.5 15.00。接触密集的插入任务上差距收窄。
- 泛化(指令随机排序、新场景): 事件模式 53.75,DreamZero 28.50,pi0.5 24.00,U-Scratch 18.50。这是最大的领先,也是主打卖点。
- 3D 感知(CO3Dv2 探针): WALL-WM 点误差 0.271、深度误差 0.132、AUC@5 0.210,都是表内最好,领先它继承的 Wan2.1-14B 底座(0.284 / 0.151 / 0.200)。
这些数字应读作:同一评分准则下的配方级收益,任务进度按 10 分部分给分制打分再归一到 0-100。事件消融是最干净的信号:架构不变,事件模式监督把推理操作从 32.6 抬到 71.6,泛化从 22.0 抬到 53.75。
这些数字没说清什么
大幅领先集中在语义结构帮得上忙的地方:推理和泛化。灵巧插入是例外。事件模式 32.00,从零统一基线 31.25,差距几乎没有,瓶颈在接触精度而非任务分解时配方就帮不上。还有一点:对比用的是内部真机测试集和团队自定的评分准则,没有公开榜单,跟 pi0.5 或 DreamZero 的跨论文比较只能算参考。论文也没给双塔去噪器加 VLM 推理路径的逐任务算力或推理延迟预算。
对开发者的判断
如果你跑的是块中心 VLA 栈,弱点在长时程或组合任务,值得搬的就是事件边界这一招:在语义事件上切监督,让块长可变。更难的是背后的数据生态:四级字幕、聚类均衡采样,以及供给大部分数据量的 XRZero-G0 无本体采集设备。统一模式加 Staircase 解码能让你保留定长接口,但循环里多了一个 9B VLM,部署比纯动作头重。
局限与存疑
复现这些数字所需的训练代码只有 GitHub 仓库,论文没给预训练或推理的算力、墙钟或 token 预算。评测用的是内部操作测试集加作者自定准则,外部有效性取决于准则和场景是否公开到能重建。灵巧结果贴近统一基线,事件锚定到底帮不帮接触密集控制仍未定论。数据管线依赖一套专有采集设备,即便拿到方法,别的团队也难复制同等数据规模。
常见问题
WALL-WM 是什么?
WALL-WM 是一个世界动作模型,把视觉-语言-动作策略预训练在语义动作事件上,而不是定长动作块。它来自 X-Square-Robot,真机多样化操作上拿到 75.86 任务进度分,pi0.5 是 55.64;泛化上领先最大,53.75 对从零统一基线的 18.50。
WALL-WM 和块中心 VLA 模型有什么区别?
标准世界动作模型从当前观测预测定长动作块,把语言、视觉、控制压进一个窗口,训练退化成短时程相关性拟合。WALL-WM 在同一个语义事件边界切视频、动作和字幕,块长随事件变化,预训练的视觉语义先验得以保留而非被覆盖。
WALL-WM 的两种推理模式是什么?
事件模式读下一事件描述,产出按事件定长的变长执行块。统一模式接一个 Qwen3.5-9B 的 VLM 配 Staircase 解码,保留传统定长块接口。两者跑在同一个事件预训练底座上,区别在接口而非两个模型。
WALL-WM 赢在预训练还是推理模式?
事件消融把配方的作用单独拎出来。架构不变,事件模式监督把推理操作从 32.6 抬到 71.6,泛化从 22.0 抬到 53.75,所以收益归功于事件锚定的监督,而非更大的底座。
一句话:WALL-WM 按语义事件边界而非定长块切 VLA 预训练,主要帮到推理和泛化,对灵巧控制几乎没动。阅读 arXiv 原文。