多域 RL 为何会遗忘,一次数学复习就能治好
按数学→代码→问答→写作顺序做 RL 后训练,数学从峰值 66.49 跌到 57.66,可梯度看上去却是正交的。末尾补一段短数学复习,数学回到 66.04,其余三域几乎不动。
快速答案
按顺序做多域 RL 后训练,会让先学的能力退化,而通常的解释(灾难性遗忘、全局梯度冲突)恰恰说错了”为什么”。本文在 Qwen3-4B-Thinking 上依次跑数学、代码、问答、创意写作,眼看数学从峰值 66.49 一路跌到 57.66,可此时各域之间的全模型梯度几乎是正交的。真正的元凶是一个二阶损伤项,它集中在网络活跃计算路径上一个很小的共享”冲突子空间”里。回报是:序列末尾补一段短数学复习,数学恢复到 66.04,另外三个域几乎不动,平均分从 64.25 升到 66.39。
如果你在做多域 RL、并已经把干扰当成无法避免的遗忘而放弃,这篇给了你机制和一个便宜的修法。如果你只训练单一领域,可以略过。
正交梯度的悖论
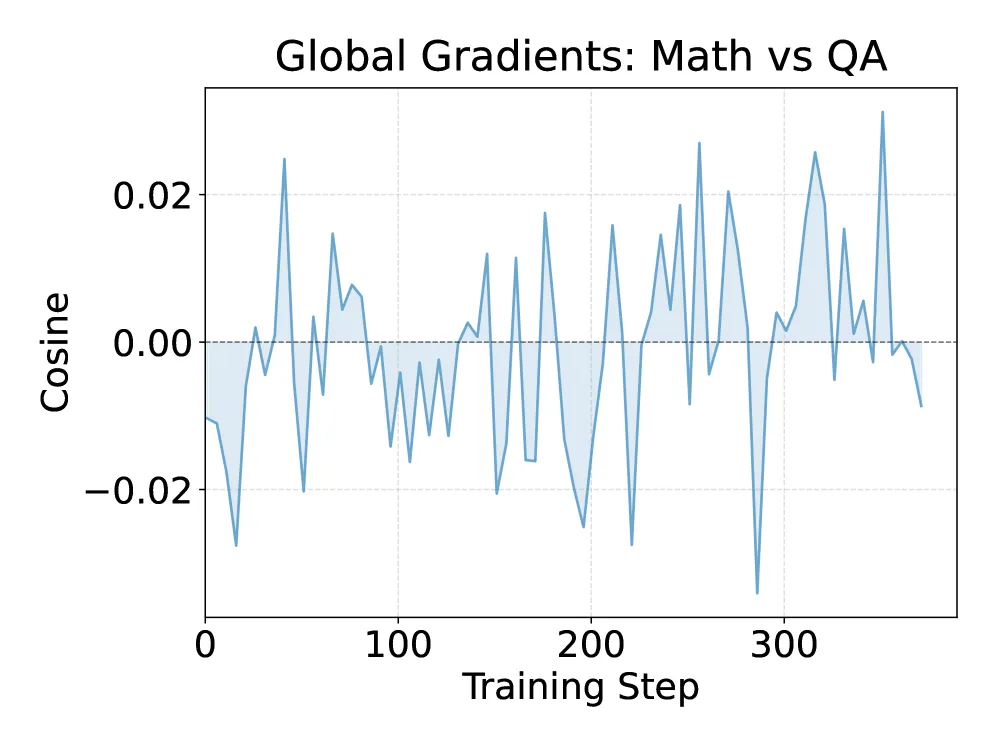
标准直觉是:两个任务梯度方向相反才会冲突,所以梯度正交就该互不伤害。作者测了数学与问答之间的全局梯度余弦,结果接近零,正是教科书里的”无冲突”条件。可干扰依然显著存在。
图 1 拆开来解了这个悖论:全局余弦约为 0,但在注意力和 MLP 层级,存在一个最冲突模块和一个最协同模块,两者效果在全局平均里几乎抵消。干扰并没有消失,而是被聚合掩盖了。两个域到底相助还是相害,是在具体计算路径上局部决定的,而不是由一个全模型点积说了算。
单域 RL 到底改了什么
在谈冲突之前,本文先刻画了一次 RL 更新究竟对权重做了什么。两个经验事实支撑起整篇文章:
- 改动是稀疏且极小的。 对每个单域专家,77% 到 89% 的参数绝对变化小于 10⁻⁷,相对变化也低于 10⁻³。RL 后训练是手术刀,不是大锤。
- 被改的神经元几乎不重叠,但被激活的却高度重叠。 任意域对之间”改动最大神经元”的 Jaccard 重叠低于 0.19,说明每个域改的是大体不同的稀疏集合;但活跃神经元(推理时真正发火的路径)在三个推理域(数学、代码、问答)之间高度重叠。
这道缝隙正是关键。各域写到不同的地方,却读经相同的路径。两次更新可以在”改哪里”上稀疏且几乎不相交,仍会在双方都依赖的某条路径上撞车。它们在这条共享路径上是协同还是破坏,取决于更新方向。
局部扰动模型
理论把后一个域的训练当作围绕前一个域参数的小扰动。把前一个域的损失做二阶展开:一阶项由(近乎正交的)梯度主导,很小;于是主要损伤来自一个由曲率与更新方向共同决定的二阶损伤项。在实测的稀疏路径结构下,这一项不会铺满整个参数空间,而是集中在由各域共激活路径张成的低维共享冲突子空间里。
这个解释令人信服,因为它调和了矛盾:梯度可以正交(一阶项小),损伤却可以很大(落在低秩共享子空间上的二阶项)。它也让损伤变得可处理。如果伤害只活在几个维度里,那就应该能做手术把它撤销。
作者正是这样验证的:用冲突子空间回滚(rollback),仅按路径冲突准则回滚 2% 的 MLP 神经元,就恢复了 20.4% 的数学损失(59.90→61.25),而问答只动了 −0.06。把回滚扩展到 32% 的 MLP 与注意力联合分量,恢复 73.6% 的损失。损伤确实集中在理论所说的位置。
关键结果
- 顺序遗忘真实且幅度大。 数学→代码→问答→写作过程中,数学走出 59.63→66.49(自身 RL 后)→59.90→57.66;代码从 52.67 漂到 50.47;写作作为最后训练的域升到 86.52。
- 短数学复习几乎是免费的撤销。 末尾再跑一小段数学 RL,数学 57.66→66.04,代码 50.47→51.05,问答 62.34→62.49,写作 86.52→85.96。平均分 64.25→66.39。
- 定向回滚证实冲突子空间。 2% MLP 神经元回滚 → 恢复 20.4% 数学,问答 −0.06;32% 联合回滚 → 恢复 73.6%。损伤是低维且局部的。
- 证据规模。 全部在 Qwen3-4B-Thinking-2507 上测得,创意写作用 Qwen3-235B-A22B-Instruct-2507 做评判模型。
局限与存疑
整项研究压在单个 4B 模型、单一域顺序(数学→代码→问答→写作)上。冲突子空间在 70B 以上、更多领域或不同课程下是否仍保持低维,未经检验;当先学域换成创意写作而非数学时,“后学伤先学”也可能表现不同。复习这个修法本质是对数据的再次暴露,更接近排练(rehearsal)而非参数空间手术;回滚实验才是对理论更干净的检验,但恢复得更少。最后,二阶分析假设扰动很小,对这些稀疏微小改动是诚实的,但在策略大幅漂移的激进 RL 下可能失效。把这些数字当作机制存在性的干净证明,而不是上线配方。
常见问题
梯度正交了,多域 RL 为什么还会伤害先学的域?
因为正交的全局梯度只把一阶干扰项归零。本文的损伤是一个二阶项(曲率乘更新方向),它集中在各域共享的低维计算路径子空间里。模块级的冲突与协同在全局余弦里相互抵消,在真实损失里却没有。
本文的”数学复习”是不是从头重训?
不是。它是在完整的数学→代码→问答→写作序列之后,对数学补跑的一小段额外 RL。它把数学从 57.66 拉回 66.04,而代码、问答、写作的变动都不到一分,因此表现为选择性恢复,而非全量重训或粗暴排练。
能不能完全不加数据,直接用冲突子空间修复干扰?
部分可以。在冲突子空间上回滚 2% 的 MLP 神经元能恢复 20.4% 的数学损失,32% 的 MLP+注意力联合回滚达到 73.6%,无需数据,但恢复量少于复习。它是损伤局部化最有力的证据,却还不足以单独成为完整修法。