Flow-DPPO:面向流匹配模型的散度近端策略优化
Flow-DPPO 把 PPO 的比值裁剪换成逐步精确的高斯 KL,SD3.5 上 GenEval2 从 39.9(Flow-GRPO)拉到 48.1,策略漂移约降为四分之一。
快速答案
Flow-DPPO 是给流匹配图像生成器用的在线 RL 目标,扔掉了 PPO 那套比值裁剪,改成在每个去噪步上算精确的 KL 散度。在 Stable Diffusion 3.5 Medium 上,多奖励训练拿到 48.1 GenEval2,而 Flow-GRPO 那种比值裁剪只有 39.9,Flow-CPS 是 44.6。换到 FLUX2-klein-base-9B,它是 57.7,Flow-GRPO 46.8。卖点不只是奖励更高:它离预训练模型漂移得小很多,FLUX2 单奖励下策略 KL 是 0.17(×10⁻³),Flow-GRPO 在 0.77。
为什么比值裁剪不适合流模型
PPO 靠裁剪新旧策略的概率比值来控制每次更新走多远。这个比值是两个策略之间散度的单样本蒙特卡洛估计。在 LLM 里,每个 token 给你一个这样的比值,噪声在长序列上能平均掉。但在流模型里,每个去噪步的”动作”是一个连续的高斯采样,每步只有一个样本,于是比值就成了一个高方差的代理,而它估的那个量本来可以闭式算出来。
作者的观察是:根本不用去估这个散度。流模型里每个逐步策略都是已知均值和方差的高斯,所以新旧策略之间的 KL 就是 ||μ_old − μ_θ||² / (2σ²)。这是精确、确定的,而且用的是优化器本来就要跑的那两次前向。比值裁剪把方差预算花在去逼近一个模型直接递给你的量。
散度近端项怎么工作
Flow-DPPO 用闭式的逐步 KL 当近端约束,而不是裁剪。不显眼的关键是那个非对称掩码。朴素的 KL 惩罚一旦散度越过阈值就拦下所有更新,包括那些把策略往旧策略拉回去的更新。Flow-DPPO 只在两个条件同时成立时才拦住梯度:这次更新在远离旧策略,而且散度已经超阈值。往旧策略拉回的修正性更新从不被拦。
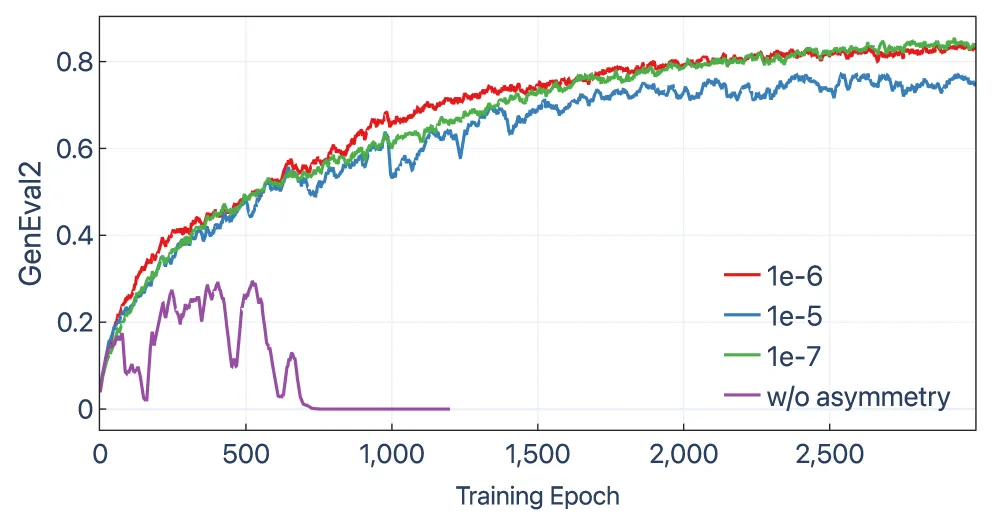
这个非对称是承重件,不是调参点缀。SD3.5 上的消融显示,去掉它,GenEval2 早期爬到约 0.3 然后塌到零;带上它,在 1e-7 到 1e-5 的学习率上都平滑收敛。对称的 KL 约束会把策略困在阈值的错误一侧,有方向的掩码让它能走回来。
关键结果
- GenEval2,SD3.5-Medium,多奖励: Flow-DPPO 48.1,Flow-GRPO 39.9,Flow-CPS 44.6,GRPO-Guard 47.8。组合的 Flow-DPPO+CPS 到 51.6,是表里最高的单项。
- GenEval2,FLUX2-klein-base-9B,多奖励: Flow-DPPO 57.7,Flow-GRPO 46.8,Flow-CPS 47.1,GRPO-Guard 49.0。这里纯 Flow-DPPO 反而胜过 +CPS 组合(55.2)。
- 策略漂移(KL ×10⁻³): FLUX2 单奖励 Flow-DPPO 0.17,Flow-GRPO 0.77;SD3.5 多奖励 2.49 对 3.81。漂移更小是精确 KL 约束比裁剪更稳的直接证据。
- 灾难性遗忘: 域外指标掉得更少。FLUX2 多奖励下 Flow-DPPO 是 PickScore 25.76 / CLIP 0.282 / HPSv2 0.368,优于 Flow-GRPO 的 25.61 / 0.277 / 0.357,说明域内奖励的提升没有牺牲通用图像质量。
- 非对称掩码消融: 去掉方向掩码,SD3.5 训练塌到 0 GenEval2;留着就稳定收敛。这是单看最清楚的一条证据,真正让方法跑起来的是这个掩码,不只是 KL 的形式。
- 多轮复用(G64-I2): Flow-DPPO 随样本复用还在涨,Flow-GRPO 和 Flow-CPS 则停滞或退化。这点要紧,因为在 9B 图像模型上靠样本复用才能压低在线 RL 的成本。
头条数字证明不了什么
论文里最高的 51.6 GenEval2 是 Flow-DPPO+CPS,是 Flow-DPPO 和一个已有技术的组合,不是 Flow-DPPO 本身。SD3.5 上组合胜出,FLUX2 上纯 Flow-DPPO 反而赢,所以”Flow-DPPO 拿 51.6”是误读。两列要分开看。
标题写着”图像/视频”,但报告的每个数字都是文生图(GenEval2、PickScore、CLIP、HPSv2),跑在 SD3.5、FLUX.1-dev、FLUX2 上,没有任何视频基准。高斯逐步那套论证应该能迁到视频流模型,但那是预期,不是这里测出来的结果。冲着视频 RL 数字来的话,这篇还没有。
这套方法和同组的 token 级信赖域工作同源,LLM RL 里的 token 级信赖域那篇提出了平行的论点:单一全局裁剪太钝。它是和本文配读的天然前作。Flow-DPPO 也和同一模型族的在线策略蒸馏相邻,见 Flow-OPD。
局限与存疑
精确 KL 依赖逐步策略是高斯,这对论文用的 SDE 采样器成立,但那是对采样器的假设,不是流模型的普遍性质。阈值和非对称掩码引入了超参;论文在三个学习率上展示了鲁棒,却没扫阈值本身。论文没给对 Flow-GRPO 的算力或墙钟对比,所以”精确且免费”形容的是散度项,不是端到端训练成本。而最强的组合结果靠 CPS,所以部分收益是从一个它本应取代的方法那里借来的。复现取决于 Tencent-Hunyuan/UniRL 已开源的代码。
常见问题
Flow-DPPO 和 Flow-GRPO 在 GenEval2 上差多少?
SD3.5-Medium 多奖励训练下,Flow-DPPO 是 48.1 GenEval2,Flow-GRPO 是 39.9,差 8.2 分;FLUX2-klein-base-9B 上是 57.7 对 46.8。Flow-DPPO 的策略 KL 还更低(FLUX2 单奖励 0.17 对 0.77,×10⁻³),奖励涨的同时离预训练模型漂移更小。
为什么比值裁剪不适合流匹配模型?
PPO 的概率比值是新旧策略散度的单样本蒙特卡洛估计。流模型每个去噪步只产一个连续高斯采样,比值就是个高方差代理。而每个逐步策略都是高斯,Flow-DPPO 改成闭式算 KL,即 ||μ_old − μ_θ||² / (2σ²),精确,且用的是优化器本就要跑的前向。
Flow-DPPO+CPS 和 Flow-DPPO 是一回事吗?
不是。Flow-DPPO+CPS 是 Flow-DPPO 加上已有的 CPS 技术。SD3.5 上 51.6 GenEval2 的头条是这个组合,不是纯 Flow-DPPO(48.1)。FLUX2 上组合(55.2)反而不如纯 Flow-DPPO(57.7),所以两者要当成不同配置读。
Flow-DPPO 训练视频还是只做文生图?
报告的实验只有文生图。每个基准(GenEval2、PickScore、CLIP、HPSv2)都跑在 SD3.5、FLUX.1-dev、FLUX2 图像生成器上。尽管标题有”图像/视频”的说法,论文里没有视频基准;高斯逐步那套论证预期能扩到视频,但没测。
非对称掩码消融说明了什么?
去掉方向掩码,SD3.5 训练在早期冲到约 0.3 后塌到 0 GenEval2;留着就在各学习率上平滑收敛。这个掩码只拦那些越过散度阈值、还在远离旧策略的更新,从不拦往旧策略拉回的更新。真正让训练稳住的是它,不只是精确 KL 的形式。
一句话:Flow-DPPO 把带噪的单样本裁剪换成免费、精确的逐步 KL 加一个方向掩码,SD3.5 上 GenEval2 拿 48.1 对 Flow-GRPO 的 39.9,策略漂移约只有四分之一。阅读 arXiv 原文。