LongTraceRL:用搜索智能体轨迹做长上下文推理强化学习
清华 LongTraceRL 从搜索智能体轨迹挖更难的干扰文档,再加实体级 rubric 奖励,让 Qwen3-4B 五个长上下文基准平均分从 53.3 涨到 59.0。
快速答案
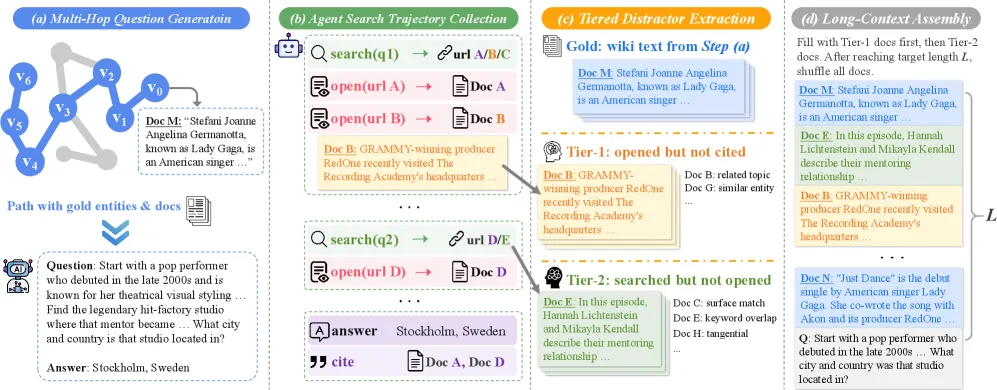
LongTraceRL 是一套针对长上下文推理的强化学习配方,专门修补标准 RLVR 的两个短板:干扰文档太好排除,奖励又只看最终答案对不对。两个补丁来自同一个来源,也就是搜索智能体在解多跳问题时留下的轨迹。智能体读过却没引用的文档,被拿来当作高难度干扰项;它推理时必须串联的实体,被拿来当作过程级别的奖励信号。
效果体现在 Qwen3-4B-Thinking-2507 上:五个基准的平均分从 53.3 升到 59.0,提升 5.7 分。涨幅最大的是检索密集型任务,MRCR +9.6、AA-LCR +8.6,正是”针藏在迷惑性上下文里”最吃力的地方。这是一套动机清晰、聚焦的方法,而非新架构;收益真实,但在不同基准上明显不均衡。
分层干扰文档是怎么造出来的
核心洞察是:搜索智能体本身就已经替你筛出了”看着相关其实不对”的文档。当一个智能体在维基百科上回答多跳问题时,它会发起检索、打开若干文档、阅读、最后引用几篇。LongTraceRL 把这个行为转化成难度信号:
- 第一层(高混淆度): 智能体打开并阅读了、但最终没有引用的文档。它们通过了足以让一个有能力的智能体点开的相关性筛选,所以是真正迷惑性的:话题相邻、实体重叠,但不是金标准证据。
- 第二层(低混淆度): 出现在检索结果里、但智能体从未打开的文档。表面相关,容易被排除。
把训练上下文塞满第一层文档,得到的题目要远比常见做法(拿随机采样的段落来填充)更难。随机填充只教会模型忽略明显无关的文本;第一层填充则逼它在两段都”长得像答案”的文字之间做区分。而这种区分能力,恰恰是长上下文问答的全部胜负手。
为什么 rubric 奖励是关键
只看结果的奖励有个众所周知的失效模式:模型可以猜对最终答案,却跳过或编造中间推理,而 RLVR 会照样强化这种行为。LongTraceRL 加了一个 rubric 奖励,对推理链上的实体召回打分。金标准实体就是搜索智能体为了到达答案而必须经过的那些节点,因此构成一组可核查的”路标”。
奖励算法很简单:模型回答里出现的金标准实体占全部金标准实体的比例。关键在于它是 仅正向(positive-only)施加的:只有当最终答案已经正确时,才给 rubric 加分。这是真正撑起整套方法的设计。如果对错误答案也奖励实体出现,模型就会学会往文本里乱撒金标准实体来刷分,而根本不去推理。把加分卡在”结果正确”这个前提上,就堵死了这条作弊路径。训练用 GRPO 跑完整个流程,复合奖励由结果项和 rubric 项按单个系数混合而成。
关键结果
先说数字,除特别标注外均在 Qwen3-4B-Thinking-2507 上:
- 五个基准平均分:53.3 到 59.0(+5.7)。
- MRCR:36.2 到 45.8(+9.6),涨幅最大,多轮指代检索任务。
- AA-LCR:33.2 到 41.8(+8.6),专家手工编写、约 10 万 token 的问题。
- LongReason:78.5 到 83.8(+5.3)。
- FRAMES:76.7 到 79.5(+2.8),LongBench v2:41.7 到 44.1(+2.4),这两个本来基线就高,涨得小。
- 跨规模成立:Qwen3-30B-A3B-Thinking-2507 从 60.5 升到 63.7,DeepSeek-R1-0528-Qwen3-8B 从 42.7 升到 43.8。
- 消融实验: 去掉 rubric 奖励(只保留分层干扰文档的 GRPO)落在 53.7,而带 rubric 在选定混合权重下是 59.0,单独验证了 rubric 奖励的贡献。
规律很一致:任务越是被”在混淆干扰项中找对针”主导(MRCR、AA-LCR),涨得越多;基线本来就高的(FRAMES、LongBench v2),涨得最少。
局限与存疑
诚实地说,适用范围很窄。训练数据从 KILT 维基百科知识图谱构造,所以问题多样性局限在百科式、多跳事实问答,不是代码、不是数学,也不是领域专家级长文档。这套挖干扰项的技巧能否迁移到非维基语料上,没有测过。
一切还都依赖搜索智能体的质量。干扰分层和金标准实体集,都由某个特定智能体读了什么、引用了什么来定义;更弱的智能体产出更容易的干扰项和更嘈杂的 rubric,更强的反之。这让方法多少有点自我指涉:监督信号继承了智能体的盲区。DeepSeek-R1-8B 那一档涨幅(+1.1)明显小于 4B 和 30B 的 Qwen,暗示这套配方最适合它开发时所用的 Qwen3-Thinking 系列。如果你的长上下文不是实体密集的维基问答,应该把头条的 +5.7 当成上限,而不是承诺。
常见问题
LongTraceRL 的分层干扰文档和普通 RLVR 的负样本采样有什么区别?
标准 RLVR 用随机采样的段落填充上下文,通常很容易排除。LongTraceRL 改用搜索智能体读了却没引用的文档(第一层),相关到足以骗过一个有能力的阅读者。这造出的区分任务比随机填充更难、更贴近真实。
LongTraceRL 的 rubric 奖励怎么避免被刷分(reward hacking)?
rubric 奖励对回答里出现多少金标准实体打分,但它是仅正向施加的:只有最终答案已经正确时才给加分。模型没法靠往错误答案里堆实体来钻空子,因为错误答案拿到的 rubric 分是零。
LongTraceRL 只对小模型有效吗?
不是。收益跨规模存在:Qwen3-4B-Thinking 平均 +5.7,30B-A3B 这个 MoE 模型 +3.2(60.5 到 63.7)。DeepSeek-R1-0528-Qwen3-8B 上涨幅较小(+1.1),说明这套配方最匹配它调试时所用的 Qwen3-Thinking 系列。