长上下文 · 高效 AI · Transformer
端到端上下文压缩:LCLM 大规模训练解读
LCLM 把 0.6B 编码器和 4B 解码器联合训练,把长上下文压成软 token,支持 1:4、1:8、1:16,显著降低预填充显存和首 token 延迟,精度接近未压缩基线。
快速答案
Latent Context Language Models(LCLM)用一个小编码器加一个大解码器联合训练来压缩长上下文,不是事后裁剪 KV 缓存。0.6B 的 Qwen3 编码器把每一块 N 个 token 池化成一个软 token,4B 的 Qwen3 解码器按 1:4、1:8、1:16 读取这些软 token。整套用约 350B token 训练,把通用任务精度、首 token 延迟、峰值显存这三者的帕累托前沿往外推,在 RULER 和 LongBench 上接近未压缩的 4B 解码器,而长上下文下的预填充显存只用一小部分。
LCLM 压缩到底怎么做
编码器是 Qwen3-Embedding-0.6B,解码器是 Qwen3-4B-Instruct。输入切成定长块,每块池化成一个连续向量(软 token),再用一个 MLP 适配器把它从编码器维度投到解码器隐藏维度。解码器把这些软 token 当普通输入 embedding 读。数量少了 4 到 16 倍,解码器的预填充更短,KV 缓存也更小。
关键在「端到端」。以往的压缩多数把语言模型冻住,裁剪或打分都在外面做。这里编码器和解码器一起训练,编码器学的是解码器真正需要的东西,而不是一个通用 embedding 目标奖励的东西。正因为有这个联合信号,一个被压了 16 倍的软 token 还能保留原块的足够信息去回答问题。
有两个设计点比看上去更重要。编码器用因果掩码,在架构扫描里赢过双向;适配器是普通 MLP,以更低成本赢过基于注意力的适配器。池化方式不是一招通用:1:16 时均值池化更好,1:4 时拼接更好。压得越狠,选的算子越要换。
训练配方,以及为什么两个目标都要
350B token 的预算分成四个阶段:适配器预热、编码器训练、端到端继续预训练、监督微调。数据混了 Nemotron 的文本、代码、推理,再加一段长上下文数据和一个重建辅助任务。
重建任务这一点值得注意。只用下一 token 预测,软 token 太粗,恢复不出细节;只用重建,表示又会坍缩。两个混着练,软 token 才既有足够细节可用、又不至于退化。这就是压缩后精度还能保住的机制:编码器被逼着保留可恢复的细节,解码器被训练去把它用在真任务上。
关键结果
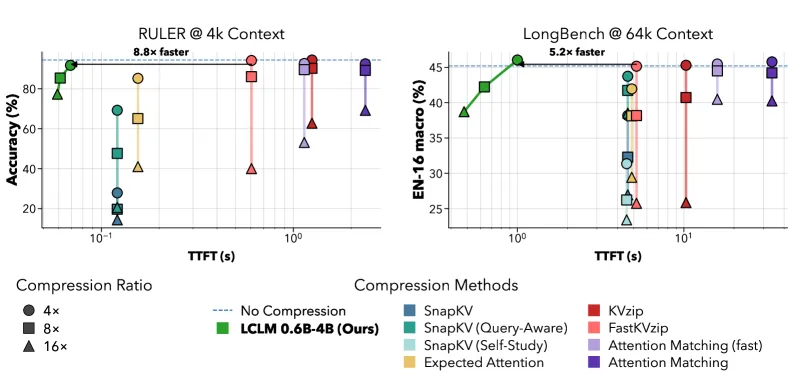
- 是帕累托前沿,不是单点胜出。 LCLM 在通用任务精度、压缩速度、峰值显存三者的联合前沿上,优于包括 SnapKV、KVzip、Attention Matching 在内的 KV 缓存基线(图 1)。它主张的是前沿上的相对位置,不是某个孤立的精度数字。
- 长上下文下显存走平。 高压缩比时,LCLM 的峰值显存随上下文增长而趋平;同样硬件上,Attention Matching 等方法在 512K 到 1M token 附近就爆显存(图 4)。这是最实在的效率结果。
- 压缩时间随压缩比下降。 KV 缓存方法不管压多少,压缩耗时基本固定(速度图上是竖线);LCLM 压得越狠反而越快,1:16 比 1:4 更便宜。
- 精度接近未压缩解码器。 在测试的压缩比下,RULER 和 LongBench 上的精度贴近未压缩 4B 解码器,压缩比越高差距越大。诚实的读法是:1:4 几乎免费,1:16 是拿可量化的精度换大块显存。
- 选择性展开能把检索找回来。 给智能体整段压缩上下文,再加一个 EXPAND(i) 工具返回原始 512-token 块,精确匹配在大海捞针上明显回升,接近未压缩基线(图 6)。光压缩会伤精确检索,这个工具把它买回来。
为什么现在重要
KV 缓存是长上下文推理的显存瓶颈,多数线上做法是在模型已经付出编码代价之后,再去淘汰或量化 token。LCLM 把压缩挪到前面的训练编码器里,解码器根本不看完整序列。对要服务长文档或长智能体历史的团队,好处是更短的预填充和更小的缓存,还省掉一套要调的淘汰策略。选择性展开是落地桥梁:平时全压着省上下文,只对模型自己判断要用的块去展开。
局限与存疑
解码器还是要为它读到的东西付钱。编码器窗口 W=1024,很长的输入要拆成多次编码,跨窗口边界的信息也被切开;作者试过窗口重叠,没有帮助。上下文足够长时,解码器自己的预填充显存又开始主导,这限制了编码器端节省能走多远。
1:16 的精度不是白来的。论文把结果定位成前沿,前沿存在的原因就是更高压缩要付精度代价,在需要精确召回的任务上最明显。把 16 倍压缩理解成无损,就是读过头了。
模型只有 0.6B 和 4B。这套联合训练配方、这些池化选择能不能迁到更大的解码器、能不能撑过 1:16,论文没给。EXPAND 也把成本挪回了原始 token,所以智能体那部分更像一个显存与精度的旋钮,不是免费检索。
常见问题
Latent Context Language Models(LCLM)是什么?
LCLM 是一类上下文压缩器,把 0.6B 编码器和 4B 解码器联合训练。编码器把每块输入 token 按 1:4、1:8、1:16 池化成一个软 token,解码器读这些软 token 而不读完整序列,从而降低预填充时间和 KV 缓存显存。
LCLM 和 SnapKV、KVzip 这类 KV 缓存淘汰方法有什么区别?
LCLM 在前面的训练编码器里压缩,解码器从不编码完整序列;SnapKV、KVzip 是编码之后再裁缓存。在精度、压缩速度、峰值显存的联合前沿上,LCLM 位置更靠前,而且长上下文下显存走平,这一点上 Attention Matching 在 1M token 附近会爆显存。
LCLM 1:16 压缩比未压缩模型掉精度吗?
会掉一点。LCLM 在 RULER 和 LongBench 上贴近未压缩的 4B 解码器,但差距随压缩比变大,精确召回类任务在 1:16 时受影响最大。1:4 几乎无损,1:16 是拿可量化的精度换大块显存。
LCLM 的架构为什么端到端训练编码器和解码器,而不冻住模型?
联合训练让编码器学到解码器真正需要从一个块里拿走什么,而不是去优化一个通用 embedding 目标。再配上混进下一 token 预测里的重建辅助任务,软 token 既能保留足够细节去回答问题,又避免了只做重建时的表示坍缩。
LCLM 智能体设置里的 EXPAND 工具如何工作?
EXPAND(i) 返回索引 i 对应的原始未压缩 512-token 块。智能体先廉价地读整段压缩上下文,再只展开它需要的块,这样大海捞针的精确匹配明显回升,接近未压缩的检索精度。
一句话:对长上下文来说,LCLM 是 KV 缓存淘汰之外一个站得住的上游方案,在中等压缩比和「默认压缩」的智能体记忆上最强,但 1:16 是真实的精度换显存,不是免费压缩。阅读 arXiv 原文。