SearchSwarm:深度研究的委派智能详解
SearchSwarm 在 Tongyi DeepResearch-30B-A3B 上微调 harness 委派轨迹,把 BrowseComp 从 43.4 拉到 68.1,居同规模榜首。
快速答案
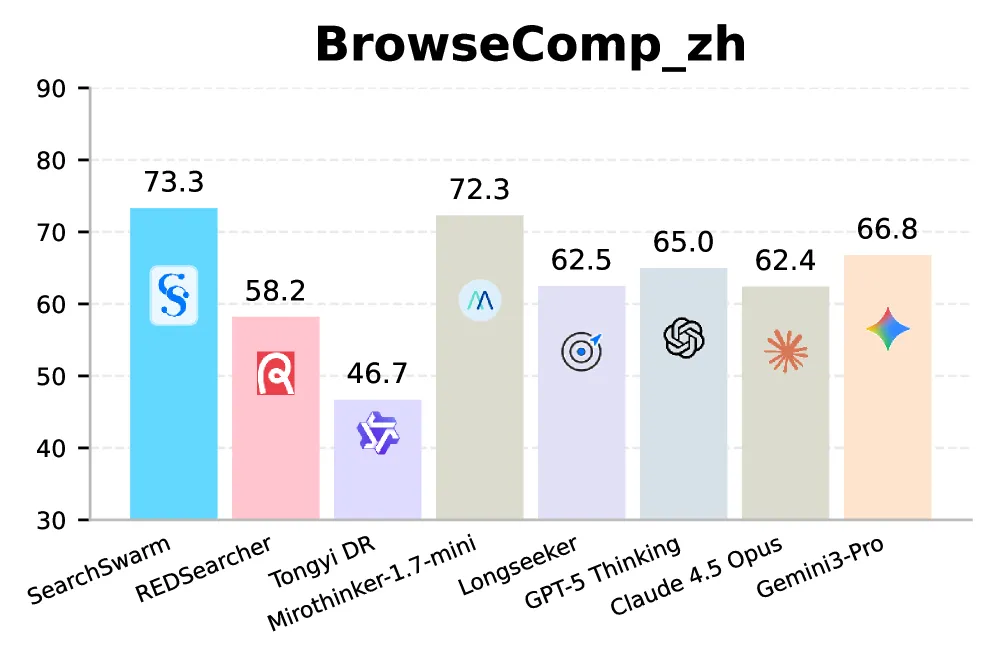
SearchSwarm 是一个 30B-A3B 深度研究模型,学会把子任务派给子智能体,而不是自己跑每一次检索。它在 BrowseComp 上拿 68.1,BrowseComp-ZH 73.3,GAIA 82.5,xbench-DeepSearch 80.8,是同规模开源模型里最高的。提升来自训练,不是底座:底座 Tongyi DeepResearch-30B-A3B 在 BrowseComp 上只有 43.4,微调加了 24.7 分。把同一套委派 harness 直接套在没训过的底座上,分数毫无变化,因为底座根本不调用子智能体工具。
这里的委派智能指什么
一个长程深度研究任务会把检索结果和网页内容塞满上下文窗口。常见做法是被动的:历史太长就总结一次,或者按固定规则丢掉旧的工具输出。SearchSwarm 用主动方案。主智能体先把任务拆开,通过 call_sub_agent 工具把有边界的子任务派给子智能体,只拿回一份简短报告。每个子智能体在自己的上下文里跑,所以主智能体窗口一直很小,工作量却能放大。
论文把这项缺的能力叫委派智能:何时拆任务、每个子任务怎么界定范围、怎么给子智能体下达背景、怎么把返回结果接回计划。这能力不是白来的。它需要展示正确委派决策的训练数据,而自然文本里几乎没有显式的多智能体协作。论文的核心动作是合成这种数据,而不是去爬。
harness 和训练怎么跑
harness 是一组推理期规则,把主智能体推向好的委派。它给出 call_sub_agent 做并行派发,要求主智能体给每个子智能体说清任务和它为什么重要,并强制子智能体返回引用,好让主智能体核对结论。主智能体保留对整体进度的独立判断,直接调工具时主要用来验证子智能体的结论。
跑这套 harness 会产出轨迹。团队把轨迹筛到那些编码了正确决策的(何时拆、范围怎么定、背景怎么给),再用作监督微调数据,训在 Tongyi DeepResearch-30B-A3B 上。结果是一个靠自身权重就会委派的模型,不再依赖 harness 脚手架才有这行为。
关键结果
- BrowseComp: SearchSwarm 68.1,底座 Tongyi DeepResearch 43.4,差 24.7 分。它略胜此前同规模最强的 MiroThinker-1.7-mini(67.9)。
- BrowseComp-ZH、GAIA、xbench: 73.3、82.5、80.8,三个都是 30B-A3B 类的最高分。
- 只用 harness 不顶用: 把 harness 套在没训过的底座上(称为 Tongyi DR Swarm),从不触发
call_sub_agent,表现和裸底座完全一样。委派必须训进去。 - harness 消融(DeepSeek V3.2,200 题 BrowseComp 子集): 基础框架 47.7,基础框架加一个光秃秃的委派工具 50.0(+2.3),完整 harness 57.7(+10.0)。大头来自下达背景和引用规则,不是工具本身。
- 开放式泛化: 在四个长文本基准上,SearchSwarm 平均 64.2,底座 50.0(+14.2),而训练只用了短答案查询。ScholarQA-v2 涨了 32.7 分。
- 单智能体迁移: 禁用
call_sub_agent后,SearchSwarm 在 200 题 BrowseComp 子集上仍胜底座(52.0 对 43.5),BrowseComp-ZH 也是(53.3 对 46.5),说明拆解习惯在没有委派工具时也留得住。
怎么读这些对比
68.1 这个头条数字旁边摆着大得多的模型,在 BrowseComp 上 SearchSwarm 追平 DeepSeek V3.2(671B-A37B,67.6),并超过 GPT-5.2-Thinking(65.8)。这要当成同规模的结论,不是前沿结论。SearchSwarm 带上下文管理跑(委派本身就算压缩),所以公平的对照是带星号、做了上下文管理的那批。在 GAIA 上它落后 Step-3.5-Flash(84.5),开放式集上落后 Dr.Tulu(65.6)。诚实的读法是:一个训好的 30B-A3B 能在这些特定基准上越级打,而收益归功于训练数据和 harness,不是更大的底座。
局限与存疑
换底座是最强证据,也是一处保留:同一份数据微调 Qwen3-30B-A3B-Thinking,在 200 题 BrowseComp 子集上拿 66.5,这令人鼓舞,但那是子集,不是完整的 1266 题基准,所以和 68.1 的头条数字不能直接比。论文没给跑并行子智能体的 token、墙钟或费用,所以委派相对单条长上下文的效率是断言,而非实测。子智能体数量、每个子任务的检索预算、Serper 加 Jina 的工具栈都会影响分数,拉动这些参数可能让结果朝任一方向移动。复现取决于承诺开源的 harness、权重和数据;没有筛选配方,那些正确委派轨迹很难重建。
常见问题
SearchSwarm 是什么,谁做的?
SearchSwarm 是蚂蚁集团联合清华、北大、人大做的 30B-A3B 深度研究模型。它在合成委派轨迹上微调 Tongyi DeepResearch,让主智能体学会通过 call_sub_agent 工具把子任务派给子智能体,BrowseComp 达到 68.1。
SearchSwarm 比它的底座 Tongyi DeepResearch 强吗?
强很多。SearchSwarm 在 BrowseComp 上 68.1,Tongyi DeepResearch 是 43.4,差 24.7 分,而且在四个短答案基准加开放式集上全都更高。
SearchSwarm 的 harness 不训练能单独用吗?
不能。把 harness 套在没训过的 Tongyi DeepResearch 底座上,从不调用子智能体工具,分数和裸底座一样。委派行为只有在 harness 生成轨迹上做监督微调之后才出现。
SearchSwarm 是多智能体系统还是单个模型?
看场景,两者都是。推理时它是主智能体加并行子智能体,但委派能力存在同一套微调权重里。禁用子智能体工具后,同一个单模型仍胜过底座,说明训练能迁到单智能体配置。
收益里 harness 占多少,模型占多少?
在 DeepSeek V3.2 的消融里,只加光秃秃的委派工具,200 题 BrowseComp 子集涨 2.3 分,完整 harness 涨 10.0 分。下达背景和引用规则扛起 harness 的大部分提升,而微调才是让模型真去用委派的关键。
一句话:SearchSwarm 表明委派智能可以合成成训练数据、烤进一个 30B-A3B 模型,把 43.4 的 BrowseComp 底座变成 68.1,不靠更大的模型。阅读 arXiv 原文。