Diffusion Models · World Models · Efficient AI
Causal Forcing++: Few-Step Autoregressive Diffusion for Real-Time Video
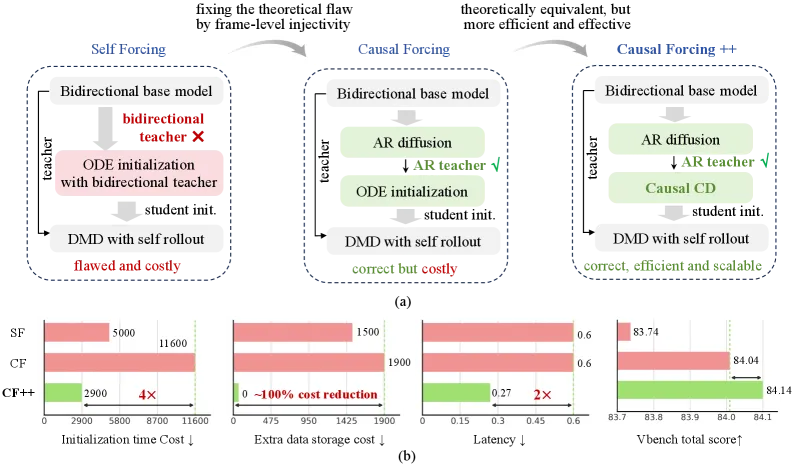
Causal Forcing++ distills bidirectional video diffusion into a 1-2 step frame-wise autoregressive generator at 14.1 FPS, halves first-frame latency, and cuts few-step training cost ~4x (11,600 to 2,900 A800 GPU hours).
Quick answer
Causal Forcing++ turns a bidirectional video diffusion model into a frame-wise autoregressive generator that produces video at 14.1 FPS with only 2 sampling steps per frame, while keeping VBench quality close to the 4-step baseline. On Wan2.1-1.3B it scores 84.14 VBench total at 2 steps (vs 84.04 for the 4-step Causal Forcing baseline) and cuts first-frame latency by 50% (0.27s vs 0.60s). The headline efficiency win is in training: its few-step initialization stage drops from 11,600 to 2,900 A800 GPU hours, a roughly 4x reduction, with no precomputed trajectory storage.
The latency problem this attacks
Interactive video generation, think game-like worlds and action-conditioned simulators, needs frames to stream out as fast as you can react, not minutes later. Bidirectional diffusion models generate a whole clip at once and cannot start until the last frame is decided, which kills interactivity. The autoregressive (AR) fix generates frame-by-frame, but naive AR diffusion still needs many denoising steps per frame, so real-time throughput stays out of reach. The earlier Causal Forcing line pushed AR diffusion to a few steps but did its few-step initialization with causal ODE distillation, which requires precomputing full denoising trajectories on real videos. That is expensive in both compute and storage.
How causal consistency distillation works
The core trade in Causal Forcing++ is replacing causal ODE distillation with causal consistency distillation (causal CD) for the few-step initialization stage. Instead of generating and storing complete denoising trajectories ahead of time, causal CD takes a single online teacher ODE step between adjacent timesteps on real videos and uses that as supervision. The paper argues this learns the same AR-conditional flow map as the trajectory-based version, so you keep the target distillation objective but obtain the signal on the fly. That removes the precompute pass and the auxiliary trajectory storage entirely, which is where the ~4x Stage 2 saving comes from.
The full recipe is three stages: (1) multi-step AR diffusion via teacher forcing, (2) the few-step initialization now done with causal CD, and (3) asymmetric diffusion model distillation with student self-rollout, where larger score models (Wan2.1-14B) supervise the small student. Stages 1 and 3 are inherited in spirit from prior distillation work; the contribution is making stage 2 cheap without losing the flow-map equivalence.
Key results
- Throughput: the 2-step frame-wise setting runs at 14.1 FPS, versus 8.69 FPS for the 4-step frame-wise setting and 10.4 FPS for the 4-step chunk-wise Causal Forcing baseline (Wan2.1-1.3B).
- Latency: first-frame latency is 0.27s for frame-wise settings vs 0.60s for the chunk-wise baseline, a 50% reduction.
- VBench: 84.14 total / 84.89 quality / 81.13 semantic at 2 steps, versus 84.04 / 84.59 / 81.84 for the 4-step Causal Forcing baseline, roughly on par overall and slightly better on quality.
- VisionReward: 6.661 at 2 steps and 6.798 at 4 steps, both above the 6.326 of the chunk-wise baseline.
- Training cost: the few-step initialization stage drops from 11,600 to 2,900 A800 GPU hours (~4x), with zero auxiliary trajectory storage.
The honest read: this is an efficiency and engineering paper, not a quality leap. The VBench total moves by about 0.1, within noise, so the value is delivering near-baseline quality at half the latency and a quarter of the relevant training cost, not generating visibly better video.
Limits and open questions
The biggest caveat is that the action-conditioned world-model variant stays chunk-wise at 4 steps. The regime that matters most for true interactive simulation is exactly where “fully real-time” is deferred, so the real-time claims are strongest for prompt-driven generation. Exposure bias still degrades later frames despite the AR training, a known failure mode for autoregressive rollout that this work mitigates rather than solves. The frame-wise 1-step setting has good motion but weak semantic understanding, so the practical sweet spot is 2 steps, not 1. All numbers are on Wan2.1-1.3B, a small backbone; whether the causal CD equivalence and the training savings hold on much larger video models is unverified here.
FAQ
What is Causal Forcing++?
Causal Forcing++ is a distillation method that converts a bidirectional video diffusion model into a frame-wise autoregressive generator needing only 1-2 sampling steps per frame, targeting real-time interactive video. It builds on the Causal Forcing line and replaces its expensive few-step initialization with causal consistency distillation.
How does Causal Forcing++ make video generation faster?
It generates frame-by-frame autoregressively at 2 steps per frame, reaching 14.1 FPS and 0.27s first-frame latency on Wan2.1-1.3B, a 50% latency cut over the 4-step chunk-wise baseline. The frame-wise design lets the first frame stream out before the whole clip is decided.
Why is causal consistency distillation cheaper than causal ODE distillation?
Causal ODE distillation precomputes and stores full denoising trajectories on real videos before training. Causal consistency distillation instead takes a single online teacher ODE step between adjacent timesteps, learning the same AR-conditional flow map without the precompute pass or trajectory storage. That cuts the Stage 2 cost from 11,600 to 2,900 A800 GPU hours.
Is Causal Forcing++ actually higher quality than Causal Forcing?
Not meaningfully. VBench total moves only about 0.1 (84.14 vs 84.04), within noise, though quality and VisionReward tick up slightly. The win is matching baseline quality at half the latency and a quarter of the few-step training cost, not better-looking video.
What model does Causal Forcing++ use?
Main experiments use Wan2.1-1.3B as the student, with Wan2.1-14B as the larger score model supervising the Stage 3 asymmetric distillation.
One line: same video quality, half the latency, a quarter of the few-step training cost, all by distilling the trajectory online instead of precomputing it. Read the original paper on arXiv.