LLM Reasoning · Fine-Tuning & Adaptation · Language Models
DelTA: Discriminative Token Credit Assignment for RLVR Reasoning
DelTA reweights RLVR updates so credit lands on tokens that actually separate right answers from wrong ones, lifting Qwen3-8B-Base by 3.26 and Qwen3-14B-Base by 2.62 average points over the strongest baselines.
Quick answer
DelTA treats every policy-gradient step in RLVR as a linear discriminator over token-gradient vectors, then reweights the update so credit concentrates on tokens that genuinely separate correct from incorrect responses rather than on high-frequency filler. On seven mathematical reasoning benchmarks it raises average accuracy by 3.26 points on Qwen3-8B-Base (28.40 vs 25.14 for the best baseline) and 2.62 points on Qwen3-14B-Base (39.91 vs 37.29), beating DAPO, SAPO and FIPO.
The problem: response-level rewards, token-level updates
RLVR (reinforcement learning from verifiable rewards) hands the model a single scalar, namely whether the final answer was right, but the gradient has to translate that one number into thousands of per-token probability nudges. That translation is the credit-assignment problem, and standard sequence-level methods solve it crudely: every token in a correct response gets pushed up by the same advantage weight, every token in a wrong one gets pushed down.
The failure mode is concrete. Formatting tokens, connectives and boilerplate appear in almost every response, correct or not. Because they are so frequent, they dominate the averaged update direction even though they carry almost no signal about whether the reasoning was sound. The genuinely decisive tokens are rare: the step where the model commits to the right lemma, the digit it gets correct. Their contribution gets drowned out. You spend most of your gradient budget reinforcing tokens that do not distinguish a good trajectory from a bad one.
How DelTA reframes credit assignment
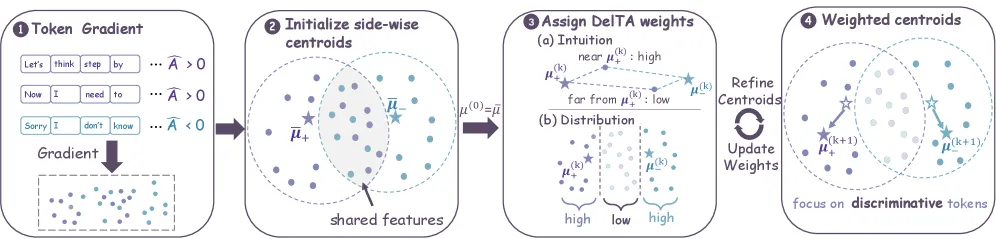
The paper’s reframing is the interesting part. It shows that a policy-gradient update is mathematically equivalent to building a linear discriminator over token-gradient vectors: the update direction is a centroid formed from advantage-weighted token vectors, and applying it is like nudging the policy toward the “correct” side and away from the “incorrect” side. Standard sequence-level RLVR builds that centroid by naive averaging, which is exactly why frequent, low-information tokens overwhelm it.
DelTA estimates per-token coefficients that amplify side-specific directions (tokens that point clearly toward correct or toward incorrect) while down-weighting shared or weakly discriminative ones (the boilerplate that points nowhere useful). It implements this by reweighting a self-normalized RLVR surrogate objective, producing a more contrastive centroid. The reweighting changes which tokens drive the update, but the resulting objective still updates the full policy parameters. This is not a partial fine-tune.
One honest caveat the authors flag themselves: to estimate the coefficients cheaply, DelTA uses a layer-restricted token-gradient proxy rather than the full-parameter token gradient. That is an approximation made for compute reasons, not a free lunch, and it is the most likely place the method could under-deliver on a different model family.
Key results
- Qwen3-8B-Base, seven math benchmarks: DelTA averages 28.40 vs 25.14 for the strongest baseline, a 3.26-point gain.
- Qwen3-14B-Base, same suite: 39.91 vs 37.29, a 2.62-point gain.
- AIME24: 43.13 (8B) and 56.87 (14B), up from 38.75 (SAPO) and 54.58 (FIPO).
- AIME25: 26.46 (8B) and 37.92 (14B), vs 24.37 and 35.00.
- HMMT25 (Feb): 18.33 (8B) and 26.04 (14B), vs 15.62 and 21.46.
- Brumo 25: 44.79 (8B) and 54.79 (14B), the largest single-benchmark margins.
- Baselines compared: DAPO, DAPO with Forking Tokens, SAPO and FIPO. DelTA leads the per-benchmark “best baseline” on essentially every dataset, not just on average.
- Beyond math: the paper reports gains on code generation (over a DAPO baseline), on an alternative base model (Olmo3-7B-Base), and on out-of-domain evaluation, though these sit in the appendix rather than the headline table.
Why this matters now
RLVR is the dominant recipe for post-training reasoning models, and almost every recent variant (DAPO, SAPO, FIPO) tweaks the advantage estimator or clipping. DelTA attacks a different and more fundamental joint: the token-level credit signal itself, justified by a discriminator argument rather than a heuristic. A 2-3 point average lift on hard, near-saturated math benchmarks like AIME and HMMT is meaningful at the frontier, and the centroid-contrast framing is reusable. It gives a principled answer to “which tokens should this reward actually move,” which any RLVR pipeline has to answer implicitly anyway.
Limits and open questions
The honest limits are clear in the paper. First, the headline gains are concentrated on mathematical reasoning; code and out-of-domain results exist but are appendix-scale, so the breadth of the win is not yet established. Second, DelTA adds computational overhead the authors describe as modest but real, leaning on a layer-restricted gradient proxy. Full-parameter token gradients would be more faithful but more expensive, and how much the proxy costs in accuracy is not pinned down. Third, all main results are on Qwen3-Base models at 8B and 14B plus one Olmo run; whether the method holds at larger scale, on instruct-tuned starting points, or on reward signals less clean than verifiable math is open. The discriminator framing is elegant, but its practical edge over simpler advantage reshaping should be re-checked on each new setting.
FAQ
What does DelTA actually change in RLVR training?
DelTA reweights the per-token contribution to the policy-gradient update so that tokens which discriminate correct from incorrect responses get amplified and frequent, low-signal tokens (formatting, connectives) get down-weighted. It does this by reweighting a self-normalized RLVR surrogate, leaving the full policy parameters updatable.
How much better is DelTA than DAPO, SAPO and FIPO?
On seven math benchmarks DelTA improves the average by 3.26 points on Qwen3-8B-Base (28.40 vs 25.14) and 2.62 points on Qwen3-14B-Base (39.91 vs 37.29) over the strongest of DAPO, DAPO-with-Forking-Tokens, SAPO and FIPO.
Why does standard RLVR over-credit formatting tokens?
Because sequence-level RLVR averages an advantage weight across all tokens in a response, and formatting and boilerplate tokens appear in nearly every response. Their high frequency lets them dominate the averaged update direction even though they carry little signal about whether the answer was correct.
Does DelTA only work on math reasoning?
The headline results are on seven math benchmarks, but the paper also reports gains on code generation, on the Olmo3-7B-Base model, and on out-of-domain evaluation. Those broader results are appendix-scale, so math is where the evidence is strongest.
What is the main weakness of DelTA?
It relies on a layer-restricted token-gradient proxy rather than full-parameter token gradients to keep the coefficient estimation cheap, and it adds modest compute overhead. Its main results are also limited to Qwen3-Base 8B/14B, so larger-scale and instruct-model behavior is untested.
One line: stop spending gradient on tokens that do not separate right from wrong. Read the original paper on arXiv.