Arbor: Autonomous Research With Hypothesis Trees
Arbor stores research attempts in a persistent hypothesis tree, then admits changes only through held-out evaluation. It reports best held-out results on six AO tasks and 86.36% Any Medal on MLE-Bench Lite.
Quick answer
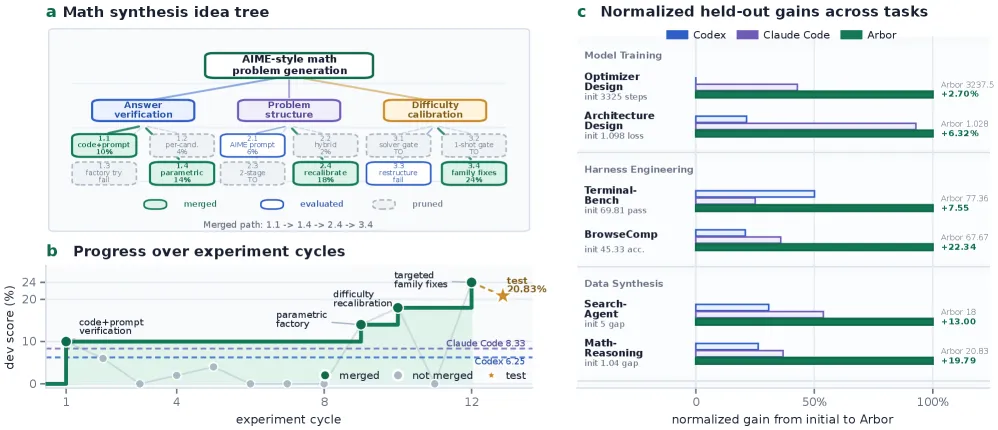
Arbor is an autonomous research framework built around Hypothesis Tree Refinement (HTR). A long-lived coordinator maintains a tree of hypotheses, artifacts, evidence, and distilled lessons; short-lived executors test one hypothesis at a time in isolated worktrees. The key result is that Arbor reports the best held-out result on all six real Autonomous Optimization tasks, with more than 2.5x the average relative held-out gain of Codex and Claude Code under the same interface and budget. On MLE-Bench Lite, Arbor with GPT-5.5 reaches 86.36% Any Medal.
Why this paper is worth a page
Most “AI scientist” systems are pipelines: generate an idea, write code, run experiments, summarize results. Arbor makes a sharper claim. Long-horizon research fails when the agent forgets what earlier attempts proved, keeps chasing dev-set improvements, or cannot explain why one branch should replace another. The paper treats autonomous research as state management.
That makes the contribution more useful than another all-in-one research bot. Arbor asks what object should persist across a multi-day research run. Its answer is a hypothesis tree, not a giant chat transcript. Each node binds a hypothesis to an artifact version, experiment evidence, a score, and an insight that can guide later branches.
How Hypothesis Tree Refinement works
The coordinator owns the tree. It decides which frontier nodes should be expanded, which should be pruned, and when a candidate branch deserves promotion. Executors are short-lived workers: they receive one hypothesis, implement it in an isolated worktree, run the evaluator, and return a compact result report.
The important discipline is the merge gate. Development feedback is used for search, but artifact-level progress is admitted only when it transfers to a held-out evaluator. That is the paper’s defense against metric chasing. A branch can look good during exploration and still be rejected if it does not beat the current best on the held-out side.
Key results
- Six AO tasks: Arbor reports the best held-out result on all six tasks, spanning model training, harness engineering, and data synthesis.
- Relative gain: the paper says Arbor achieves more than 2.5x the average relative held-out gain of Codex and Claude Code under the same task interface and resource budget.
- MLE-Bench Lite: Arbor with GPT-5.5 reaches 86.36% Any Medal, the strongest result in the comparison.
- Ablation: on MLE-Bench Lite with Claude Opus 4.6, full Arbor reaches 81.82% Any Medal, versus 63.64% without the tree and 54.54% without insight feedback.
- Budget: across six completed cost logs, Arbor uses 20.12M to 43.19M tokens, which the authors describe as comparable to single-trajectory baselines.
The ablation is the cleanest number. It suggests the tree is doing real work after the agent already knows how to produce runnable submissions. The gain is not only better execution; it is better refinement.
The honest reading
Arbor is strongest when the task has executable evaluators, a dev/test split, and a meaningful artifact that can be improved over time. That describes ML engineering and benchmark-harness work well. It does not automatically cover open-ended theory, wet-lab science, or research where human taste and problem selection dominate the value.
The paper is also a living technical report. That is useful because the system can evolve, but it means readers should treat the current numbers as a strong project report rather than a settled benchmark standard. The most valuable part may be the protocol: keep hypotheses, code branches, evidence, and merge decisions auditable.
Limits and open questions
The six AO tasks are real, but still a small slice of science. The baseline comparison against Codex and Claude Code is useful because those systems are strong general coding agents, yet the result may depend on the exact interface, evaluators, time limit, and artifact definitions. Cost is nontrivial even if token use is comparable, and wider tasks could make tree growth harder to control.
The main open question is whether HTR remains useful when the feedback signal is delayed, noisy, or partly subjective. If every branch needs expensive expert review, the held-out merge gate becomes the bottleneck.
FAQ
What is Arbor in autonomous research?
Arbor is an autonomous research framework that uses a coordinator, short-lived executors, and a persistent hypothesis tree to improve research artifacts through iterative experiments.
What is Hypothesis Tree Refinement?
Hypothesis Tree Refinement stores each research attempt as a tree node containing the hypothesis, artifact version, evidence, score, and distilled insight. The tree becomes both memory and search frontier.
How does Arbor compare with Codex and Claude Code?
On six Autonomous Optimization tasks, the paper reports that Arbor obtains the best held-out result on all six and more than 2.5x the average relative held-out gain of Codex and Claude Code under the same interface and budget.
Why does Arbor use a held-out merge gate?
The held-out gate prevents dev-set wins from being mistaken for real progress. A candidate branch is promoted only if its improvement transfers beyond the feedback used during exploration.
What is Arbor’s main limitation?
Arbor needs executable tasks, reliable evaluators, and artifact versions that can be compared. It is less proven for research settings where progress depends on subjective judgment, human collaboration, or long-delayed evidence.
One line: Arbor is interesting because it treats autonomous research as evidence management, not just a longer agent loop. Read the original paper on arXiv.