AI Agents · Retrieval-Augmented Generation · LLM Reasoning
FORT-Searcher: Training Search Agents Without Shortcuts
FORT-Searcher trains a 3B-active search agent on shortcut-resistant tasks, scoring 66.2 overall among comparable open agents and delaying answer hit time from 18.7 to 46.9 versus REDSearcher data.
Quick answer
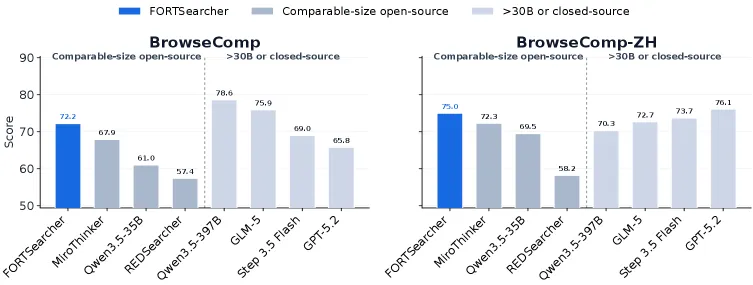
FORT-Searcher tackles a subtle data problem for deep search agents: a question can look hard on paper, yet collapse when one clue exposes the answer early or the model already knows the entity. FORT defines four shortcut risks and generates training tasks that keep evidence acquisition necessary. The resulting SFT-only agent reaches 66.2 overall among comparable-size open-source search agents, with 72.2 on BrowseComp and 75.0 on BrowseComp-ZH. The stronger evidence is in the diagnostics: FORT data raises average solving cost to 141.0 and answer hit time to 46.9, compared with 92.1 and 18.7 for REDSearcher.
Difficulty is measured by when evidence appears
The method starts by separating structural complexity from realized search difficulty. A multi-hop question may contain many facts, but if one rare clue identifies the answer in the first query, it is poor training data for deep search. FORT watches for evidence co-coverage, single-clue selectivity, exposed constants, and prior-knowledge binding.
Its synthesis pipeline controls those risks through entity selection, evidence-graph construction, question formulation, and adversarial refinement. The adversary is important because the generator does not get to assume the intended path survives contact with a strong search agent. Shortcut-prone drafts are repaired; over-fuzzed drafts are narrowed until they are solvable but still search-heavy.
The trained FORT-Searcher is intentionally modest. It uses Qwen3-30B-A3B-Thinking with about 3B active parameters and supervised fine-tuning only. That makes the paper more about data quality and trajectory protocol than about buying a larger model.
Key results
- FORT-Searcher scores 66.2 overall across five benchmarks with complete comparable-size results, ahead of MiroThinker-1.7-mini at 64.6 and Qwen3.5-35B-A3B at 59.9.
- It reaches 72.2 on BrowseComp, 75.0 on BrowseComp-ZH, 80.8 on xbench-DeepSearch-2505, 57.2 on xbench-DeepSearch-2510, and 46.0 on Seal-0.
- Context management matters: BrowseComp improves from 55.9 to 72.2, and BrowseComp-ZH from 62.1 to 75.0.
- FORT data at average solving cost 141.0 has answer hit time 46.9; REDSearcher has 92.1 and 18.7 under the same diagnostic setting.
- Removing shortcut controls makes synthetic questions easier: cumulative ablation moves accuracy from 29.0 to 81.6 and answer hit time from 46.5 to 11.8.
What builders should take from it
The practical takeaway is not to copy the headline number blindly. FORT-Searcher is useful when a team can reproduce the paper’s setup and when the measured bottleneck matches its own product or research loop. The paper-specific evidence above tells builders where the gain comes from, what comparator was used, and which parts are still protocol-dependent. A good follow-up is to rerun the same idea on a local task distribution before treating it as a general capability upgrade.
For search-agent builders, the diagnostic lesson is more portable than the exact trained checkpoint. Log when the answer first appears, whether the model guessed it before evidence, and how many independent sources are actually needed. Those traces reveal whether a dataset teaches search or teaches recognition of overexposed clues. A smaller but cleaner corpus may beat a larger corpus whose answers are found too early.
Limits and open questions
FORT-Searcher still relies on web-search style tasks with verifiable short answers. It does not prove the same recipe works for open-ended research, enterprise search, or tasks where answer quality is graded by judgment. Some diagnostics use a strong model judge to inspect trajectories, so the measurements are operational proxies rather than ground truth about all possible shortcuts.
The missing evidence that would change the judgment is a broader external replication: more independent harnesses, clearer release artifacts, and stress tests designed by groups that did not build the method. Until then, the paper is best read as a strong directional result with a concrete evaluation surface.
FAQ
What is FORT-Searcher?
FORT-Searcher is a deep search agent trained with supervised fine-tuning on tasks synthesized by FORT, a shortcut-resistant data pipeline.
How does FORT-Searcher compare with similar open agents?
Among comparable-size open-source agents with complete scores, it reports the best overall score at 66.2, ahead of MiroThinker-1.7-mini at 64.6.
Why is FORT different from making longer search tasks?
The paper measures answer hit time and prior-shortcut rate. FORT delays answer exposure and lowers shortcut opportunities, so the agent must acquire evidence before answering rather than spend many turns after already finding the answer.
One line: FORT-Searcher matters because it treats search-data difficulty as a trajectory property, not a graph-size label. Read the original paper on arXiv.