Efficient AI · Long Context · Transformers
Full Attention Strikes Back: RTPurbo Sparsifies LLMs in Hundreds of Steps
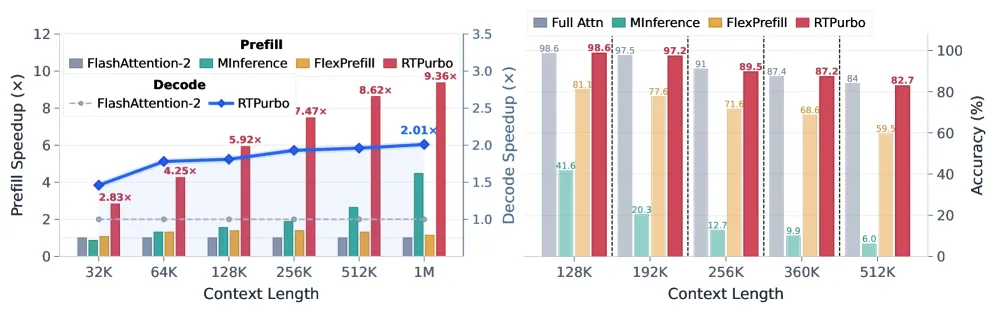
RTPurbo converts a trained full-attention LLM into a sparse one with about 600+600 adaptation steps, keeping LongBench accuracy (54.24 vs 53.80) while hitting 9.36x prefill speedup at 1M context.
Quick answer
RTPurbo turns an already-trained full-attention LLM into a sparse-attention model using two short adaptation stages of roughly 600 steps each — not from-scratch pretraining — and the result keeps quality while running far faster on long inputs. On Qwen3-Coder-30B-A3B it reaches a 9.36x prefill speedup at 1M-token context and about 2.01x decode speedup, while LongBench average actually edges up to 54.24 from the full-attention baseline’s 53.80. The trick: only 15% of attention heads keep the full context, and the other 85% run a 8192-token sliding window with 4 sink tokens.
The sparsity nobody used: head specialization
The starting observation is that attention heads in a trained model already specialize. A minority of heads do long-range retrieval — they actually reach back across the full context — while most heads only attend locally. Prior sparse-attention work either retrains the whole model with sparsity baked in, or applies one uniform sparse pattern to every head, which wastes the retrieval heads’ reach or starves the local heads of speedups. RTPurbo instead measures each head and assigns it a role: keep about 15% as full-context retrieval heads, and convert the rest to a fixed sliding window. The name “Full Attention Strikes Back” is the point — you do not throw away the trained full-attention model, you transfer it.
How RTPurbo works
The pipeline is deliberately cheap. Stage one trains a 16-dimensional low-rank indexer that lets retrieval heads pick which earlier tokens to attend to, converging in about 600 steps over roughly 30M tokens. Stage two does end-to-end self-distillation — the sparse model learns to match the original full-attention model’s outputs — converging in about 600 steps where only about 1.2M tokens are actual label tokens. So the “hundred training steps” framing in the title is real for each stage’s order of magnitude, though the honest total is closer to ~1,200 steps across both. Compared with the cost of pretraining a sparse model, that is negligible, and it is the paper’s central selling point.
Key results
- 9.36x prefill speedup at 1M-token context on Qwen3-Coder-30B-A3B, and about 2.01x decode speedup at that length; at a more common 32K context the prefill speedup is 2.83x.
- LongBench: 54.24 average vs 53.80 for the full-attention baseline — the sparse model slightly beats its own teacher, which is the strongest result in the paper.
- RULER at 64K: 85.49 vs 86.23 — a small, honest degradation rather than a wash.
- AIME24/25: 86.67%, matching full attention exactly on Qwen3-30B-A3B-Think, so the reasoning workload survives sparsification.
- Architecture: 15% retrieval heads (full context), 85% sliding-window heads (window 8192, plus 4 sink tokens), a 16-dimensional indexer for retrieval.
Why this matters now
Long-context inference is gated by attention cost, and most teams cannot afford to pretrain a sparse model from scratch. RTPurbo offers a path that reuses an existing strong checkpoint and pays only a few hundred steps to make it cheap at 1M tokens. The near-lossless LongBench and AIME numbers are the part that earns attention: a lot of sparse-attention papers show speedups but quietly lose a few points on hard long-context tasks. Edging past the baseline on LongBench, while matching reasoning accuracy, is a stronger claim than “negligible drop.”
Limits and open questions
The honesty is in the fine print. First, the method leans on stable head specialization — if a model’s heads do not cleanly split into retrieval and local roles, or if domain shift moves that partition, the fixed 15%/85% assignment may not hold. Second, prefill is not fully sparsified: the retrieval heads still run dense attention during prefill, so the prefill speedup, while large, is not the full theoretical ceiling. Third, the evaluation is concentrated on the Qwen3 family and on long-context plus reasoning workloads; the authors themselves say broader validation across other architectures and domains is still needed. The 9.36x headline is also a 1M-context number — at the 32K most users actually run, the gain is the more modest 2.83x.
FAQ
What is RTPurbo and what does it do?
RTPurbo is a framework from Nanjing University and Alibaba Group that transfers a trained full-attention LLM into a head-wise sparse-attention model using two short adaptation stages of about 600 steps each, rather than retraining from scratch. It keeps roughly 15% of heads at full context and runs the rest with a sliding window.
How much faster is RTPurbo at long context?
On Qwen3-Coder-30B-A3B, RTPurbo reaches a 9.36x prefill speedup at 1M-token context and about 2.01x decode speedup; at 32K context the prefill speedup is 2.83x.
Does RTPurbo lose accuracy compared with full attention?
Barely, and on LongBench it slightly improves: 54.24 average vs 53.80 for full attention. RULER at 64K drops a little to 85.49 from 86.23, and AIME24/25 matches full attention at 86.67%.
Why is RTPurbo called “Full Attention Strikes Back”?
Because it does not discard the trained full-attention model — it transfers that model into a sparse one cheaply, keeping a minority of full-context retrieval heads so long-range ability survives.
One line: reuse a strong full-attention checkpoint, spend a few hundred steps, and run 1M-token context at up to 9.36x prefill speedup with near-lossless accuracy. Read the original paper on arXiv.