Multimodal Models · Text-to-Image · Transformers
ARM: An AutoRegressive Multimodal Model with Unified Discrete Tokens
ARM is a 7B autoregressive model that does image understanding, text-to-image, and editing in one next-token framework, on a shared discrete tokenizer; RL lifts GenEval 0.79 to 0.86 and GEdit-EN overall 5.75 to 6.68.
Quick answer
ARM is a single 7B autoregressive model that predicts text and image tokens with one next-token objective, covering understanding, text-to-image generation, and instruction editing. The shared layer is a discrete visual tokenizer trained with four objectives at once, so the same tokens feed all three tasks. After supervised training, reinforcement learning raises GenEval from 0.79 to 0.86 and GEdit-Bench-EN overall from 5.75 to 6.68, and the RL on text-to-image and editing helps both tasks at once. The gains are a recipe result: one backbone, one token space, plus a preference-optimization stage on top.
What problem the tokenizer solves
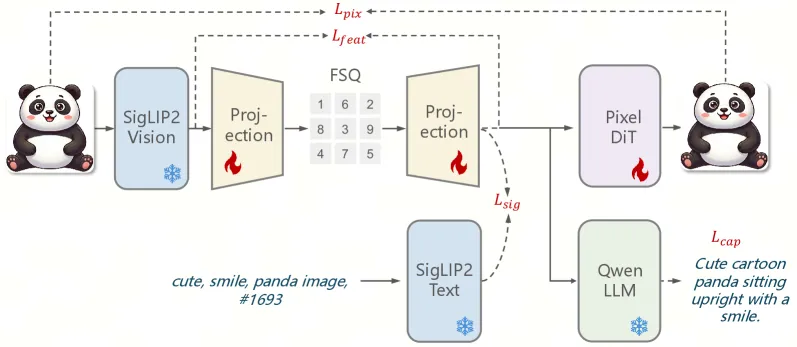
Unified models keep hitting a tokenizer trade-off. Semantic encoders like CLIP and SigLIP carry high-level meaning and help understanding, but they drop the fine detail needed to reconstruct or edit an image. Pixel-level VQ tokenizers reconstruct well but carry weak semantics, so understanding suffers. ARM tries to get both in one discrete code by supervising the tokenizer with four losses together (Eq. 4, weights 1, 5, 5, 1):
- A captioning loss that asks the quantized tokens to predict a caption, forcing language alignment.
- A pixel reconstruction loss from a lightweight diffusion decoder learning a rectified velocity field, for fidelity.
- A sigmoid contrastive (SigLIP-style) loss for semantic discriminability across a batch.
- A feature distillation loss matching the quantized embeddings to original SigLIP2 features by cosine distance.
Quantization uses Finite Scalar Quantization (FSQ), which gives high capacity without an explicit learned codebook. The ablation is the cleanest evidence the four objectives matter: with only caption + pixel losses, ImageNet zero-shot accuracy collapses to 0.2 and PSNR sits at 15.2. Add the sigmoid loss and zero-shot jumps to 79.4 but PSNR drops to 9.3. The full four-objective recipe reaches 80.2 zero-shot and 19.6 PSNR at once, with the highest codebook usage (75.6) and perplexity (0.28).
How one model covers three tasks
With that token space fixed, ARM trains a 7B autoregressive backbone on interleaved text and image tokens with a plain next-token loss (Eq. 6). Training runs in three stages (pretraining, continued training, supervised fine-tuning) on up to 200 GPUs at 80K sequence length, with text-to-image as the dominant data mix (0.70 falling to 0.50 across stages). Image generation and editing are just sequences of visual tokens the model emits and a latent diffusion decoder turns back into pixels. So understanding, generation, and editing are the same operation on different prompts, which is the point of the discrete-token design.
Key results
- Understanding (7B unified): ARM scores POPE 87.3, MMBench 80.7, MME-Perception 1463, MMMU 40.2, GQA 76.1, SEED 73.1. Among discrete-token unified models it leads POPE and MMBench, and it is competitive with continuous-representation unified models like Janus-Pro and Show-o2.
- Text-to-image (GenEval / DPG): ARM hits 0.79 GenEval and 84.48 DPG before RL; ARM-RL reaches 0.86 GenEval and 86.00 DPG, near Janus-Pro-7B (0.80) and below diffusion leaders like Qwen-Image (0.87).
- Reasoning generation (WISE): ARM overall 0.50, matching FLUX.1[Dev] and above Emu3 (0.39) and Janus-Pro-7B (0.35); RL lifts WISE to 0.56.
- Editing (GEdit-Bench-EN): ARM 5.75 overall before RL, ARM-RL 6.68, close to Step1X-Edit (6.70) and BAGEL (6.52). Perceptual quality G_PQ is 7.68, the highest in the table.
- RL synergy: training T2I RL then Edit RL then Joint RL moves GEdit from 5.75 to 6.68 and GenEval from 0.79 to 0.86 while understanding scores stay flat (MMMU 40.2 to 41.0, POPE around 87). The editing-only RL step also nudges T2I, and the T2I step nudges editing.
How to read the comparisons
ARM is a discrete-token autoregressive model, and its natural rivals are other unified models: Emu3, Janus / Janus-Pro, Show-o / Show-o2, Chameleon, Liquid, VILA-U. Against those it is strong on understanding and competitive on generation. Against pure diffusion specialists (Qwen-Image, FLUX, BAGEL on editing) it trails on the headline generation and editing scores but does so with one model that also reads images, which the specialists do not. The RL stage uses a GRPO-style objective (Eq. 7) with GPT-o3 and GPT-4.1 as reward models, so the post-training gain depends on an external judge, not a fixed metric.
Limits and open questions
ARM does not top diffusion specialists on raw generation or editing: GenEval 0.86 sits under Qwen-Image 0.87, and GEdit 6.68 sits under Step1X-Edit 6.70 and roughly ties BAGEL. MMMU at 40.2 trails continuous unified models like Bagel (55.3) and Show-o2 (48.9), so the understanding lead is benchmark-specific rather than across the board. The RL rewards come from proprietary GPT models, which makes the 0.79 to 0.86 and 5.75 to 6.68 jumps hard to reproduce without the same judges and prompts. The paper reports no FID and gives no compute or latency cost for the autoregressive decode plus diffusion detokenization path, so the practical generation speed against diffusion baselines is unstated.
Builder takeaway
If you are building a unified model and fighting the semantics-versus-fidelity tokenizer trade-off, the four-objective tokenizer ablation is the most portable idea here: the sigmoid and feature-distillation terms are what buy both 80.2 ImageNet zero-shot and 19.6 PSNR in one code. The RL-induces-synergy result is worth watching but is tied to GPT reward models, so treat the exact numbers as setup-specific. If you only need best-in-class image editing today, a diffusion editor still scores higher on GEdit; ARM’s argument is that one autoregressive model can be close on all three tasks at once.
FAQ
What is ARM (AutoRegressive Large Multimodal Model)?
ARM is a 7B autoregressive model from the Institute of Trustworthy Embodied AI and ByteDance Seed that unifies image understanding, text-to-image generation, and instruction editing under one next-token objective over a shared discrete visual tokenizer. After RL it reaches GenEval 0.86 and GEdit-Bench-EN overall 6.68.
How does ARM’s discrete visual tokenizer differ from CLIP or VQ tokenizers?
ARM supervises one tokenizer with four objectives at once: captioning, pixel reconstruction, a SigLIP-style sigmoid contrastive loss, and SigLIP2 feature distillation, with FSQ quantization. The ablation shows caption + pixel alone give 0.2 ImageNet zero-shot and 15.2 PSNR, while all four reach 80.2 and 19.6 together, which CLIP-only or VQ-only tokenizers do not.
Does ARM beat diffusion models like BAGEL or Qwen-Image?
Not on raw scores. ARM-RL hits GenEval 0.86 versus Qwen-Image 0.87, and GEdit-Bench-EN 6.68 versus Step1X-Edit 6.70 and BAGEL 6.52. ARM’s claim is parity-ish on generation and editing from a single model that also handles understanding, not a win on any one specialist metric.
What does reinforcement learning add in ARM?
RL with GRPO and GPT reward models lifts WISE from 0.50 to 0.56, GenEval from 0.79 to 0.86, and GEdit-Bench-EN overall from 5.75 to 6.68, while understanding scores stay flat. The paper also reports cross-task synergy: training text-to-image RL helps editing and vice versa.
One line: ARM packs understanding, text-to-image, and editing into one 7B autoregressive model on a four-objective discrete tokenizer, then uses GPT-judged RL to close most of the gap to diffusion specialists. Read the original paper on arXiv.