Multimodal Models · Vision Foundation Models · Efficient AI
LocateAnything: Parallel Box Decoding for Faster Vision Grounding
LocateAnything emits each bounding box in a single decoding step instead of digit-by-digit, hitting 12.7 boxes/sec in hybrid mode — about 2.5x faster than Rex-Omni-3B — while leading on COCO and LVIS at the same 3B size.
Quick answer
LocateAnything is NVIDIA’s vision-language grounding model that decodes a whole bounding box in one step instead of generating its coordinates as a string of digit tokens. That single change pushes throughput to 12.7 boxes per second in hybrid mode — roughly 2.5x faster than the closest prior model, Rex-Omni-3B (5.0 boxes/sec), and about 10x faster than a text-based Qwen3-VL (1.1 boxes/sec) — while the 3B model still tops COCO at 54.7 mean F1@mIoU and LVIS at 50.7, beating Rex-Omni at the same parameter count.
Why coordinate-as-text decoding is the bottleneck
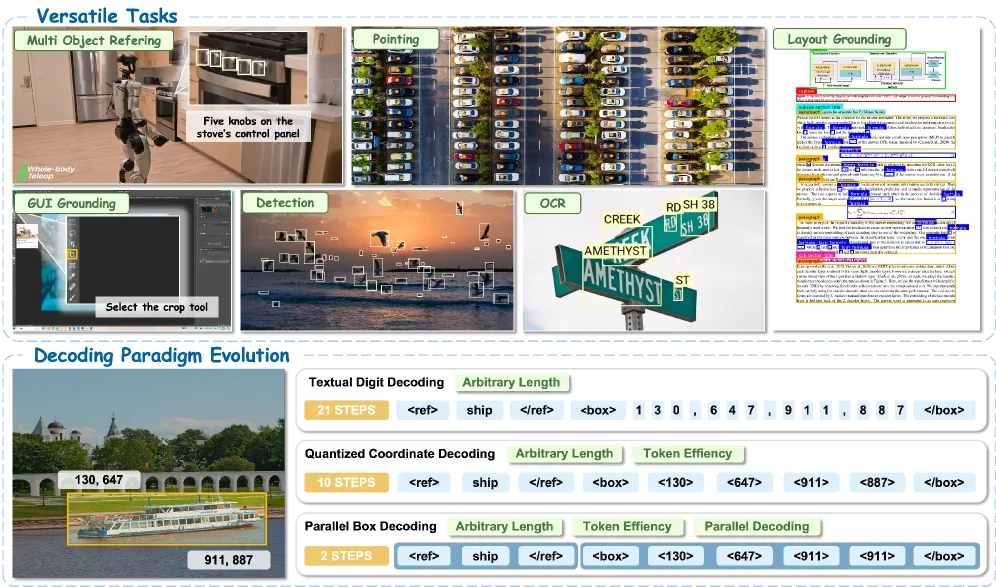
The dominant way to make a multimodal LLM “point at” objects is to have it write coordinates as text: a box becomes a string like 130, 647, 911, 887, and the model emits it one digit token at a time. That works, but it is slow and brittle. A single box can cost a dozen-plus autoregressive steps, and because each digit is sampled independently, the four numbers of one box are not guaranteed to stay geometrically coherent — the model can wander mid-box. When a scene has many objects, the step count explodes linearly with the number of boxes, so dense detection becomes painfully slow.
LocateAnything’s premise is that a box is one geometric object, not a sentence, and should be decoded as one atomic unit.
How Parallel Box Decoding works
Parallel Box Decoding (PBD) treats each geometric element — a bounding box or a point — as a single token-like unit emitted in one decoding step, rather than serializing its coordinates into a digit sequence. Two things follow. First, the four corners of a box are produced together, so intra-box geometric coherence is preserved by construction instead of hoped for. Second, multiple boxes can be decoded in parallel, which is where the throughput win comes from: the cost stops scaling with digits-per-box and scales much more gently with the number of objects.
The system pairs a Moon-ViT vision encoder with a Qwen2.5 language backbone at 3B parameters, and exposes three decoding modes — a fast mode at 15.3 boxes/sec, a hybrid mode at 12.7, and a slow mode at 4.3 — letting you trade raw speed against quality without swapping models.
What is in LocateAnything-Data
The model is trained on a purpose-built corpus the authors call LocateAnything-Data: 138 million natural-language queries over 12 million unique images, with 785 million annotated bounding boxes. The point of that scale is breadth — the same model handles multi-object referring, pointing, layout grounding, GUI grounding, detection, and OCR-style localization rather than one narrow benchmark. This is a dataset contribution as much as a decoder contribution, and the size is a real moat: reproducing PBD without comparable grounding data would likely undercut the numbers.
Key results
- COCO detection: 54.7 mean F1@mIoU at 3B parameters, the top result in the paper’s main table.
- LVIS detection: 50.7 mean F1@mIoU, again leading at 3B; the authors report roughly +3.8% over Rex-Omni-3B on LVIS and +1.8% on COCO mean F1 at the same parameter count.
- RefCOCOg referring: 76.7 F1@mIoU on val and 77.6 on test.
- Throughput: 15.3 boxes/sec (fast), 12.7 (hybrid), 4.3 (slow) — versus 5.0 for Rex-Omni-3B and 1.1 for a text-based Qwen3-VL, i.e. about 2.5x and 10x faster respectively.
The headline is not a single accuracy record; it is that the speed gain comes without paying an accuracy tax at the same model size.
Why this matters now
Grounding throughput is becoming the limiting factor for agentic and embodied systems. A GUI agent that has to localize every clickable element, or a robot policy that needs box coordinates for many objects per frame, spends most of its latency budget on coordinate decoding. PBD attacks exactly that cost, and the fact that it is built on a standard Qwen2.5 + ViT stack means the idea is portable rather than tied to bespoke architecture. If the parallel-decoding trick generalizes, “emit the geometry, don’t spell it out” could become a default for grounding heads the way structured outputs became default for tool calls.
Limits and open questions
The reported wins are F1@mIoU, not the classical [email protected] accuracy most RefCOCO leaderboards use, so head-to-head comparison with older grounding work takes care — the metric is not directly interchangeable. Everything here is reported at 3B; the paper does not establish whether the parallel-decoding advantage holds, shrinks, or grows at 7B-plus scale, where text-based decoders may close the quality gap. The three-mode design is convenient but hints that the fastest setting trades away quality, and the paper’s own framing leans on its proprietary 138M-box dataset, so an outside team cannot cleanly separate “PBD is better” from “we trained on far more grounding data.” Independent reproduction on public data is the obvious next test.
FAQ
What makes LocateAnything faster than other grounding models?
LocateAnything decodes each bounding box as one atomic unit in a single step (Parallel Box Decoding) instead of emitting coordinates digit-by-digit, reaching 12.7 boxes/sec in hybrid mode versus 5.0 for Rex-Omni-3B and 1.1 for a text-based Qwen3-VL.
Does LocateAnything sacrifice accuracy for speed?
No, not at the same model size: the 3B model leads on COCO (54.7 mean F1@mIoU) and LVIS (50.7), beating Rex-Omni-3B by about +1.8% and +3.8% respectively while running roughly 2.5x faster.
What is Parallel Box Decoding in LocateAnything?
It is a decoding scheme that treats a bounding box or point as a single geometric unit, producing all coordinates together in one step. This preserves intra-box coherence and lets many boxes be decoded in parallel instead of scaling with the digit count per box.
What data was LocateAnything trained on?
LocateAnything-Data: 138 million natural-language queries across 12 million unique images, with 785 million annotated bounding boxes, spanning referring, pointing, layout, GUI, detection, and OCR localization.
Who built LocateAnything?
It comes from a team at NVIDIA, built on a Moon-ViT vision encoder and a Qwen2.5 language backbone at 3B parameters.
One line: decode the box, don’t spell out its digits — and grounding gets ~2.5x faster at no accuracy cost. Read the original paper on arXiv.