MemGPT: Treating the LLM Context Window Like an Operating System
MemGPT borrows OS virtual memory — it lets the LLM page data in and out of its own context with function calls, lifting deep memory retrieval to 93.4% with GPT-4 vs 35.3% for recursive summarization.
Quick answer
MemGPT treats a fixed LLM context window the way an operating system treats limited RAM: the model itself decides what to keep in context and what to evict to external storage, using function calls to page data back in on demand. On the Deep Memory Retrieval benchmark — recalling a fact from earlier sessions — MemGPT hits 93.4% accuracy with a GPT-4 backend, versus 35.3% for the standard recursive-summarization baseline that just compresses old turns. The core claim is not a bigger window; it is that an agent can manage its own memory with no change to the underlying model.
The OS analogy, made concrete
The paper’s framing is the whole idea, so it is worth being precise about it. An operating system gives programs the illusion of unlimited memory by moving pages between fast RAM and slow disk. MemGPT does the same for an LLM: the context window is “main context” (RAM), and a vector store plus a recall database is “external context” (disk). When main context fills up, the system does not silently truncate or blindly summarize — the LLM is given tools to read and write its own memory, so eviction and retrieval become deliberate actions the model takes.
What makes this work is self-directed editing. MemGPT prompts the model with a description of its own memory hierarchy and a set of functions: append to working context, search recall storage, search archival storage, evict from the FIFO message queue. The model emits these as function calls in its normal output, and the system executes them and feeds results back. So the LLM is both the worker and the memory manager.
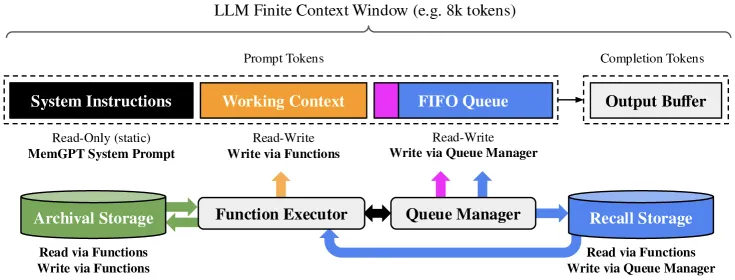
How the memory tiers and interrupts work
Main context has three parts: a fixed system instruction (the read-only “kernel” that explains the memory tools), working context (a scratchpad the model edits to hold durable facts like the user’s persona), and the FIFO queue of recent messages. External context has recall storage (the full message history, searchable) and archival storage (an arbitrary read/write vector database for documents and facts).
The control loop is the OS borrow that ties it together. MemGPT processes events — a user message, a system warning that the queue is near its token limit, a scheduled tick — and the LLM responds with function calls. A “yield” function ends the agent’s turn and waits for the next event; this is the interrupt mechanism. Crucially, when context pressure builds, the system injects a warning before overflow, giving the model a chance to flush important content to external storage and summarize the rest, rather than losing it. Function call → execution → result is chained until the model yields, which is how MemGPT can take multiple internal steps (search, read, write, reply) for a single user turn.
Key results
- Deep Memory Retrieval (DMR): 93.4% accuracy with GPT-4 (gpt-4-turbo), versus 35.3% for recursive summarization — the headline gap. The benchmark is 500 multi-session conversations, each 5 sessions of up to 12 messages, with a Q/A pair that can only be answered by recalling an earlier session.
- Conversation openers: MemGPT’s generated opening line beats a human-written persona opener on similarity-to-gold-persona across several backend models, because it actively pulls persona facts from working context.
- Nested key-value retrieval: MemGPT is the only method that keeps solving the task past 2 levels of nesting, where a flat-context GPT model degrades — it chains searches instead of needing everything in-window at once.
- Document QA: MemGPT analyzes documents far larger than the backend’s context window by paging passages through archival storage, sustaining accuracy where a truncated-context baseline falls off as documents grow.
Why this paper matters now
MemGPT is the paper that reframed “LLM memory” from make the window bigger to let the agent manage memory itself — and that framing became the default for the agent-memory field. The project later became Letta, and the pattern (tiered memory, self-editing via tool calls, an event loop with interrupts) shows up in most serious agent frameworks today. If you have ever seen an agent “remember” you across sessions or read a document that obviously exceeds its context, you are looking at a descendant of this design.
Limits and open questions
The honest catch is that MemGPT only works as well as the function-calling model behind it. Every memory operation is an LLM decision, so a weaker backend that forgets to save or searches badly will lose information — the system does not guarantee retention, it delegates it. The multi-step loop also multiplies cost and latency: a single user turn can fire several searches and writes, each its own model call. The benchmarks lean on conversational recall and synthetic retrieval (nested KV, DMR); they show the mechanism works, but they are narrower than “general long-term memory.” And retrieval quality is bounded by the embedding/search stack underneath — MemGPT manages what to store and fetch, not how well the vector store ranks it. Treat it as an architecture for self-managed memory, not a solved memory problem.
FAQ
What does MemGPT actually do differently from a long context window?
MemGPT does not enlarge the window — it gives the LLM tools to move data between the window and external storage, so the model itself decides what to keep, evict, and retrieve. A long-context model holds everything passively; a MemGPT agent manages a small window like an OS manages RAM with virtual memory.
What is virtual context management in MemGPT?
It is the technique of paging information between “main context” (the LLM’s active window) and “external context” (a searchable database), driven by the model’s own function calls. It is directly modeled on OS hierarchical memory, where data moves between fast and slow tiers to create the illusion of unlimited memory.
How much better is MemGPT at remembering past conversations?
On the Deep Memory Retrieval benchmark it reaches 93.4% accuracy with GPT-4, versus 35.3% for recursive summarization — because it searches its full recall storage for the relevant earlier message instead of relying on a lossy running summary.
Is MemGPT the same as Letta?
Yes, in lineage: the MemGPT research project from UC Berkeley became the open-source agent framework Letta. The paper is the foundational design; Letta is its productionized successor. This explainer covers the paper.
Does MemGPT require a special model?
No — it works on top of off-the-shelf LLMs (the paper uses GPT-4 and GPT-3.5) with no fine-tuning. It needs a model that can reliably emit function calls, since all memory operations are expressed as tool calls the system executes.
One line: stop trying to fit everything in the window — give the agent an OS-style memory hierarchy and let it page its own data. Read the original paper on arXiv.