Agent Memory · AI Agents · Long Context
EvoArena: Why Agent Memory Must Track Environment Changes
EvoArena turns static agent tasks into evolving chains and finds current agents average only 39.6% accuracy; EvoMem adds patch memory and improves chain-level accuracy by 3.7 points.
Quick answer
EvoArena tests whether LLM agents can handle environments that change over time. It converts terminal tasks, software repositories, and long-term user preferences into evolution chains, then scores both individual steps and full chains. Current agents average 39.6% across the evolving domains. EvoMem, a patch-based memory add-on, gives a modest 1.5-point average gain on EvoArena, including 2.6 points on step accuracy and 3.7 points on chain accuracy, with larger gains on standard GAIA and LoCoMo evaluations.
What EvoArena changes in agent evaluation
Most agent benchmarks freeze the world. The tool works the same way, the repository state is fixed, and the user preference is treated as a stable fact. Real deployments are messier. APIs change, dependencies move, validation rules are revised, and a user’s current preference may supersede an older preference only under certain conditions.
EvoArena turns that mess into a measurable benchmark. It builds versioned chains, then asks the agent to solve tasks at each stage while preserving relevant history. The stricter chain score counts whether the agent can keep succeeding across related versions, not just solve isolated snapshots.
The three domains
Terminal-Bench-Evo modifies terminal tasks through CLI, dependency, I/O, protocol, and validation changes. SWE-Chain-Evo builds software-evolution chains from repository milestones, where earlier implementation choices can affect later tasks. PersonaMem-Evo uses long mixed-topic conversations where preferences evolve, conflict, or become conditional.
The scale is useful. Terminal-Bench-Evo contains 441 total instances from 356 evolved task chains. SWE-Chain-Evo contains 493 chain-step instances across 50 evolution chains from 12 repositories. PersonaMem-Evo contains 505 questions with median conversation length around 174.7K tokens and median 597 turns.
How EvoMem works
EvoMem does not replace the agent’s memory system. It records non-additive memory updates as patches: what changed, why it changed, how the new state differs from the old state, and which evidence triggered the update. At retrieval time, the agent can fetch both the current memory and relevant patches.
That distinction is the mechanism. A normal memory update may overwrite the old rule. Patch memory preserves the transition, which matters when a later task depends on the fact that the rule changed, not only on the latest rule.
This is a small architectural change with a measurable diagnostic benefit.
Key results
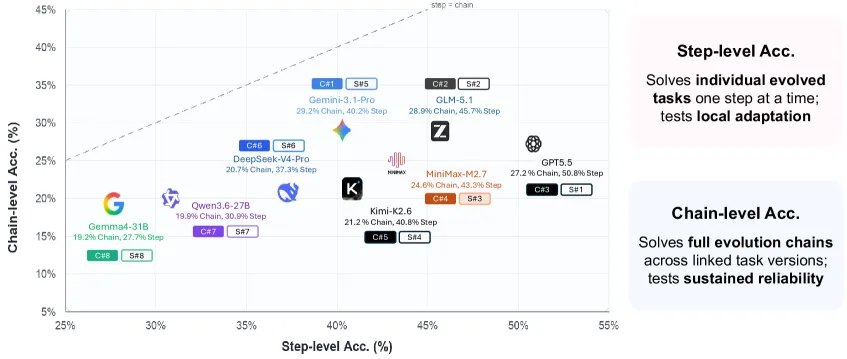
- Current-agent difficulty: base agents average 43.6% step accuracy on Terminal-Bench-Evo, 29.2% on SWE-Chain-Evo, and 46.5% on PersonaMem-Evo.
- Chain failure: base chain accuracy is much lower: 21.5% for Terminal-Bench-Evo, 10.6% for SWE-Chain-Evo, and 39.1% for PersonaMem-Evo.
- EvoMem gains: the abstract reports a 1.5-point average EvoArena gain; inside that, the table-level breakdown shows average step accuracy up 2.6 points and chain accuracy up 3.7 points.
- Standard benchmarks: the abstract reports GAIA +6.1 and LoCoMo +4.8. Table 4 uses a narrower displayed setting, where GAIA improves by 6.5 points and LoCoMo by 3.3 points.
- Mechanism evidence: PersonaMem-Evo evidence capture improves from 89.4% to 90.3%, a small but directionally relevant gain.
Limits and open questions
The benchmark is stronger than a static test, but it is still synthetic in how evolution is packaged. Real production environments change through partial documentation, ambiguous user feedback, and messy organizational memory. EvoArena makes those changes cleaner so they can be scored.
EvoMem’s gains are also modest on the core benchmark. A 3.7-point chain improvement is useful, but it does not make agents reliable. The result says patch memory is a better primitive than latest-state memory, not that memory is solved.
The missing evidence is practical. The paper does not yet show production environments with messy documentation, partial failures, changing permissions, and noisy user corrections. It also leaves open patch retrieval cost, token budget pressure, cases where models ignore retrieved patches, and which failure types dominate long chains after patch memory is added.
For builders, the right action is scoped. If you are building long-lived coding, operations, or personal-memory agents, keeping a patch history is worth testing. If your product is short-session QA or static retrieval, EvoMem is probably not the first migration to prioritize.
FAQ
Why does EvoArena chain accuracy drop below step accuracy?
Chain accuracy requires the agent to keep succeeding across related versions. A model can solve one snapshot but fail later when the CLI, dependency, repository state, or user preference changes, so chain scores expose brittleness hidden by isolated step scores.
What is EvoMem in the EvoArena paper?
EvoMem is a patch-based memory method. It records meaningful memory changes as structured patches and retrieves those patches alongside the latest memory when an agent faces a related task.
What does EvoMem improve beyond latest-state memory?
Latest-state memory can erase why a rule changed. EvoMem preserves transition patches, so an agent can recover the old state, the new state, and the evidence that caused the update when a later task depends on the change history.
How hard is EvoArena for current agents?
Current agents average 39.6% across the evolving domains. Chain-level scores are lower than step scores, including 21.5% on Terminal-Bench-Evo and 10.6% on SWE-Chain-Evo for base agents.
Does EvoMem solve agent memory?
No. EvoMem improves chain-level accuracy by 3.7 points on average, but the remaining failure rates are large. Its evidence is strongest as a design direction: memory systems should preserve update history, not only the latest state.
One line: EvoArena is useful because it tests whether agents remember how the world changed, not just what the world looks like now. Read the original paper on arXiv.