MemGPT:把大模型上下文窗口当操作系统来管
MemGPT 借来操作系统的虚拟内存:让大模型用函数调用给自己的上下文分页换入换出,深度记忆检索在 GPT-4 上做到 93.4%,而递归摘要只有 35.3%。
快速答案
MemGPT 把固定的大模型上下文窗口,当成操作系统对待有限内存那样来管:由模型自己决定哪些内容留在上下文里、哪些换出到外部存储,再用函数调用按需把数据分页换回来。在深度记忆检索(Deep Memory Retrieval)基准上——回忆更早会话里出现过的事实——MemGPT 配 GPT-4 后端做到 93.4% 准确率,而标准的递归摘要基线(只把旧对话压缩掉)只有 35.3%。它的核心主张不是更大的窗口,而是:智能体能在不改动底层模型的前提下,自己管理自己的内存。
把「操作系统」这个类比说清楚
论文的整个思路就在这个类比里,所以值得说精确。操作系统通过在快速内存(RAM)和慢速磁盘之间搬运分页,给程序制造「内存无限」的错觉。MemGPT 给大模型做同一件事:上下文窗口是「主上下文」(RAM),向量库加召回数据库是「外部上下文」(磁盘)。当主上下文塞满时,系统不会偷偷截断、也不会盲目摘要——而是把读写自己内存的工具交给模型,于是换出与检索变成模型主动采取的动作。
让这套机制成立的关键是自主编辑。MemGPT 在提示里告诉模型它自己的内存层级结构,并给一组函数:往工作上下文追加、搜索召回存储、搜索归档存储、从 FIFO 消息队列里换出。模型在正常输出里发出这些函数调用,系统执行后再把结果喂回去。于是大模型既是干活的人,也是内存管理器。
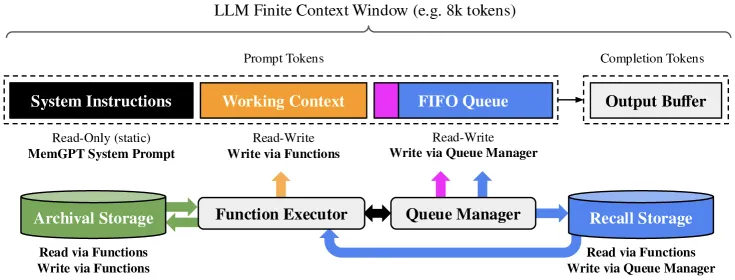
内存层级与中断怎么运作
主上下文有三部分:固定的系统指令(只读的「内核」,说明有哪些内存工具)、工作上下文(模型可编辑的便笺,存放用户画像这类持久事实)、以及最近消息的 FIFO 队列。外部上下文有召回存储(可搜索的完整消息历史)和归档存储(任意读写的向量数据库,放文档与事实)。
把这一切串起来的,是从操作系统借来的控制循环。MemGPT 处理事件——用户消息、提示队列逼近 token 上限的系统警告、定时心跳——模型则以函数调用回应。一个「让出」(yield)函数结束本轮、等待下一个事件,这就是中断机制。关键在于:当上下文压力堆积时,系统会在溢出之前注入警告,给模型一个把重要内容刷写到外部存储、并把其余内容摘要的机会,而不是把它丢掉。函数调用 → 执行 → 返回结果,如此链式进行直到模型让出——这正是 MemGPT 能为单个用户回合走多步内部操作(搜索、读取、写入、回复)的原因。
关键结果
- 深度记忆检索(DMR): GPT-4(gpt-4-turbo)后端 93.4% 准确率,递归摘要只有 35.3%——这是头条差距。基准为 500 段多会话对话,每段 5 个会话、每会话至多 12 条消息,配一个只有回忆起更早会话才能答对的问答对。
- 对话开场白: 在多个后端模型上,MemGPT 生成的开场白在「与黄金画像的相似度」上超过人工书写的画像开场白,因为它会主动从工作上下文里调取画像事实。
- 嵌套键值检索: 在嵌套超过 2 层后,MemGPT 是唯一仍能持续解题的方法,而平铺上下文的 GPT 模型在此处退化——它靠链式搜索,而不是把所有内容一次塞进窗口。
- 文档问答: MemGPT 通过归档存储分页换入段落,能分析远超后端窗口的文档;随着文档变大,截断上下文的基线准确率下滑,而它能维持住。
为什么现在重要
MemGPT 是把「大模型记忆」从把窗口做大重新定义为让智能体自己管理内存的那篇论文,而这个定义后来成了智能体记忆领域的默认范式。该项目后来发展为 Letta,而它的模式(分层内存、用工具调用自我编辑、带中断的事件循环)如今出现在大多数严肃的智能体框架里。如果你见过某个智能体跨会话「记住」你、或读懂明显超出其上下文的文档,你看到的就是这套设计的后裔。
局限与存疑
诚实的代价是:MemGPT 的上限就是背后那个函数调用模型的上限。每次内存操作都是一次模型决策,所以一个忘了保存、或搜得很差的弱后端会丢信息——系统不保证留存,它把留存委托出去了。多步循环还会放大成本与延迟:单个用户回合可能触发好几次搜索和写入,每次都是独立的模型调用。基准偏向对话回忆和合成检索(嵌套 KV、DMR),它们证明机制有效,但比「通用长期记忆」要窄。检索质量也被底层 embedding/搜索栈卡住——MemGPT 管的是存什么、取什么,而非向量库排得有多好。把它当作一套自管理内存的架构,而非已被解决的记忆问题。
常见问题
MemGPT 和长上下文窗口到底有什么不同?
MemGPT 不扩大窗口,而是给大模型工具,在窗口与外部存储之间搬数据,于是模型自己决定留什么、换出什么、检索什么。长上下文模型被动地把一切都端着;MemGPT 智能体像操作系统用虚拟内存管理 RAM 那样,主动管理一个小窗口。
MemGPT 里的虚拟上下文管理是什么?
它是在「主上下文」(模型的活动窗口)和「外部上下文」(可搜索数据库)之间分页搬运信息的技术,由模型自己的函数调用驱动。它直接模仿操作系统的分层内存:数据在快慢两层之间移动,制造内存无限的错觉。
MemGPT 记住过往对话的能力强多少?
在深度记忆检索基准上,配 GPT-4 时达到 93.4% 准确率,而递归摘要只有 35.3%——因为它会在完整召回存储里搜出相关的那条更早消息,而非依赖有损的滚动摘要。
MemGPT 和 Letta 是一回事吗?
血缘上是:来自 UC Berkeley 的 MemGPT 研究项目后来发展为开源智能体框架 Letta。论文是奠基设计,Letta 是其产品化的后继者。本文解读的是论文。
MemGPT 需要特殊模型吗?
不需要——它架在现成大模型之上(论文用 GPT-4 和 GPT-3.5),无需微调。它需要一个能稳定发出函数调用的模型,因为所有内存操作都表达为系统去执行的工具调用。
一句话:别再硬把所有东西塞进窗口——给智能体一套 OS 式的内存层级,让它给自己的数据分页。阅读 arXiv 原文。