Multimodal Models · AI Agents · Open Models
OpenSearch-VL: An Open Recipe for Multimodal Search Agents
OpenSearch-VL open-sources data, code, and weights for vision-language search agents that call real search, OCR, and image tools — its 30B-A3B model lifts seven benchmarks by 13.8 points on average over Qwen3-VL.
Quick answer
OpenSearch-VL is a fully open recipe — datasets, tool environment, training code, and weights — for vision-language models that answer questions by acting: issuing web and image searches, running OCR, and sharpening or cropping images mid-reasoning. The headline number is a 13.8-point average gain across seven multimodal-search benchmarks for the 30B-A3B model over its Qwen3-VL base, with the team reporting results comparable to proprietary models like GPT-5 and Gemini-2.5-Pro on several tasks. Three sizes ship: 8B, 30B-A3B (mixture-of-experts), and 32B.
The problem: a VLM that can search is not a search agent
A vision-language model that can call a search tool still fails at real multimodal questions for a mundane reason — long tool chains break. The released SFT trajectories average 6.3 tool calls each, and when a search returns garbage or OCR misreads a sign, the error cascades and the final answer collapses. Standard RL treats every step uniformly, so it never learns to recover from a bad tool result. OpenSearch-VL’s whole design targets this failure mode rather than chasing a bigger base model.
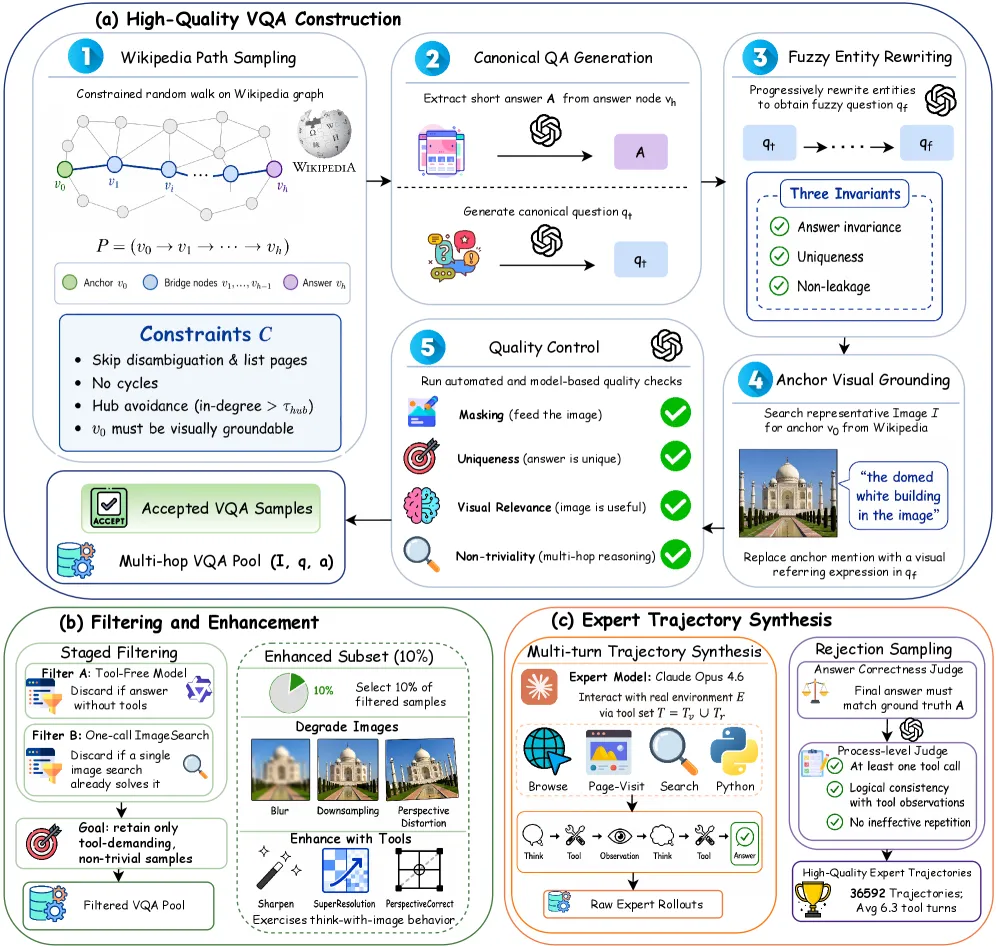
What’s in the SearchVL data
The recipe’s first asset is data, and it is more engineered than most agent datasets. Two sets are released:
- SearchVL-SFT-36k — 36,592 expert trajectories, averaging 6.3 tool-invocation turns, synthesized in a real tool environment and filtered by rejection sampling with both answer-correctness and process-level judges.
- SearchVL-RL-8k — 8,000 examples held disjoint from SFT for reinforcement learning.
The questions are built from the English Wikipedia hyperlink graph: sample constrained multi-hop paths, generate canonical QA pairs, then rewrite them into fuzzy questions so the model cannot answer from memory and must actually search. Anchor entities are grounded with representative images, and a staged filter keeps only tool-demanding, non-trivial samples. An “image degradation then tool restoration” subset deliberately teaches think-with-image behavior — blur an image so the model learns to call SuperResolution or Sharpen.
Fatal-aware GRPO
The training contribution is multi-turn fatal-aware GRPO. The team defines a fatal step as K=3 consecutive tool errors, and the algorithm down-weights or isolates the credit assignment around those collapses so the policy learns to recover instead of being uniformly punished for a doomed rollout. With K=5 rollouts per instance and a composite reward (accuracy plus process quality, weighted at α=0.8), the fatal-aware variant reaches 71.8 versus 67.6 for vanilla GRPO on the 8B model — a 4.2-point gain attributable to the algorithm alone.
Key results
- 30B-A3B: +13.8 points average across the seven benchmarks over the Qwen3-VL base; the 8B model gains +3.9 points over prior SOTA.
- Per-benchmark (32B / 30B-A3B / 8B): MMSearch 72.3 / 68.7 / 64.5; LiveVQA 70.5 / 67.4 / 59.6; InfoSeek 74.8 / 72.4 / 70.2; SimpleVQA 76.2 / 74.9 / 71.6; FVQA 74.7 / 73.2 / 71.5; BrowseComp-VL 43.8 / 41.1 / 37.6; VDR 33.8 / 33.5 / 20.8.
- Ablations show the data engineering carries the result: removing source-anchor grounding costs 11.5 average points, dropping fuzzy-entity rewriting costs 10.3, and removing staged filtering costs 8.2.
- Tool suite: seven tools — TextSearch, ImageSearch, OCR, Sharpen, SuperResolution, PerspectiveCorrect, Crop.
- Cost: SFT runs ~2 days (8B) to 4 days (30B-A3B) on 256 H20 GPUs; RL is ~200 steps over 10 days on 64 H20 GPUs.
The honest read: the biggest levers here are data construction (the fuzzy-rewriting and grounding ablations each cost more than 10 points), with fatal-aware GRPO adding a real but smaller 4.2. This is a data-and-recipe paper more than an algorithm paper.
Limits and open questions
The hardest benchmark exposes the ceiling. BrowseComp-VL tops out at 43.8 and VDR at 33.8 — far from solved, so “comparable to proprietary models on several tasks” should not be read as parity everywhere. The questions are synthesized from English Wikipedia, which bounds both topical and linguistic coverage and risks overfitting to one knowledge source. The tool environment is the authors’ own harness; real-world search APIs are noisier and rate-limited, so live deployment numbers may differ. And the headline +13.8 is measured against the same-family Qwen3-VL base — fair as an ablation, but it is the recipe’s gain over its own starting point, not a claim of beating the strongest closed agents outright.
FAQ
What is OpenSearch-VL?
OpenSearch-VL is an open recipe — SearchVL datasets, a real tool environment, training code, and 8B / 30B-A3B / 32B weights — for vision-language models that answer questions by calling search, OCR, and image-editing tools across multiple turns.
How much does OpenSearch-VL improve over its base model?
The 30B-A3B model gains 13.8 points on average across seven multimodal-search benchmarks over its Qwen3-VL base, and the 8B model gains 3.9 points over prior state of the art.
What is fatal-aware GRPO in OpenSearch-VL?
It is a multi-turn reinforcement-learning algorithm that detects fatal steps — three consecutive tool errors — and adjusts credit assignment so the agent learns to recover from broken tool chains. It adds 4.2 points over vanilla GRPO on the 8B model.
Is OpenSearch-VL actually open?
Yes. The authors release the SearchVL-SFT-36k and SearchVL-RL-8k datasets, the tool environment, training code, and model weights, with a public GitHub repository.
One line: the gains come mostly from carefully synthesized search data, with fatal-aware GRPO teaching the agent to survive broken tool chains. Read the original paper on arXiv.