Mixture of Experts · Efficient AI
Manifold Power Iteration: A Better Router for MoE Models
MPI redesigns MoE routers by aligning router rows with expert weight directions. On 11B MoE, average benchmark accuracy rises from 40.92 to 42.76 with only 0.2% training slowdown.
Quick answer
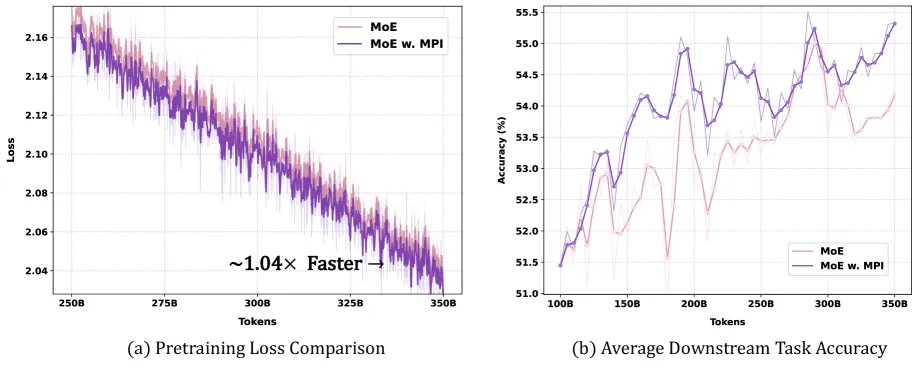
Manifold Power Iteration (MPI) is a router redesign for Mixture-of-Experts models. Instead of treating each router row as a free vector learned only by gradient updates, MPI nudges that row toward the principal singular direction of the corresponding expert weight matrix. The practical result is simple: in the paper’s 11B MoE experiment, average accuracy across seven reported downstream tasks improves from 40.92 to 42.76, while GSM8K jumps from 17.89 to 27.60. The method adds about 0.2% training slowdown and no runtime inference overhead, according to the authors.
What problem this router is trying to fix
In a sparse MoE layer, the router decides which experts should process each token. A standard router is usually a learned matrix: each row stands in for one expert, and the input token is routed to experts with the highest scores. That design works, but it leaves an odd gap. The router row is supposed to represent an expert, yet the usual training objective does not explicitly force that row to encode the expert’s own weight structure.
MPI attacks that gap directly. The paper’s argument is not that MoE needs a new dispatch interface. It keeps the standard router shape. The claim is narrower: if a router row is a compressed proxy for an expert, it should track the most informative direction of that expert’s weight matrix. That direction is the principal singular direction.
How Power-then-Retract works
Computing a full singular value decomposition for every expert at every training step would be too expensive. MPI uses one power-iteration step instead. For each router row, it fetches the associated expert weight, performs a lightweight matrix-vector update toward the dominant direction, then applies a retraction step that normalizes the row to a controlled scale.
That second step matters. Without a norm constraint, repeated power iteration can inflate or collapse router row norms. In an MoE router, scale is not harmless: a row with a larger norm can win more routing decisions and overload its expert. The paper calls this update pattern “Power-then-Retract”: move the router toward the expert direction, then put it back on a stable spherical constraint.
The authors also give a geometric derivation. MPI can be read as a steepest-ascent update for maximizing the projection between the router row and the expert weight direction under a manifold constraint. Readers do not need the derivation to use the idea, but it is the reason this is more than an extra regularizer.
Key results
- 1B optimizer sweep: across AdamW, AdamH, Muon, and MuonH, MPI improves average accuracy across 25 benchmarks from 42.26 to 43.56, 42.59 to 43.93, 43.01 to 43.55, and 42.78 to 43.98.
- 3B benchmark result: after midtraining, average accuracy over ARC-C, MMLU, TriviaQA, NaturalQs, BBH, GSM8K, and MBPP rises from 36.37 to 38.70.
- 11B benchmark result: the same average rises from 40.92 to 42.76. GSM8K is the largest visible jump: 17.89 to 27.60.
- Perplexity: at 11B, validation perplexity in bits per byte improves from 0.728 to 0.723; the Math set improves from 1.852 to 1.581.
- Load balance: for the 3B model, MaxVio Batch drops from 1.133 to 1.024, and MaxVio Global drops from 0.964 to 0.711.
- Efficiency: the 11B run sustains 34.97 billion tokens per day for the vanilla MoE, and MPI slows training by only 0.2%. The authors say inference has zero overhead because the transformed router weights can be prepared when the model loads.
The strongest evidence is not one isolated benchmark. It is the repeated pattern: MPI improves small 1B runs across optimizer choices, then keeps a gain at 3B and 11B.
Why the result matters now
MoE scaling is back in the center of language-model engineering because it offers more parameter capacity without activating every parameter for every token. But sparse models are only as useful as their routing. A bad router can waste experts, create load imbalance, or send tokens to experts whose weights are not a good fit.
This paper is useful because it treats routing as a representation problem, not only as a load-balancing problem. Many MoE papers add auxiliary losses or change top-k assignment. MPI asks whether the router row itself is a meaningful summary of the expert. That is a clean design question, and it can sit underneath other router tricks rather than replacing them.
Limits and open questions
The experiments are pretraining experiments run by the authors, not an open reproduction. The benchmark suite is broad enough to show a signal, but the paper does not prove that MPI will help every MoE architecture, every expert layout, or every training data mix. It also compares mainly against vanilla MoE routers, because the authors frame MPI as orthogonal to other router designs. That is reasonable, but it leaves the most useful engineering question partly open: how much gain remains when MPI is combined with the strongest current routing and load-balancing methods?
The reported overhead is attractive, but it should still be checked in real training stacks. A 0.2% slowdown in the authors’ 11B setup does not automatically cover every distributed implementation. The inference claim is also conditional on being able to precompute the router transform cleanly at load time.
FAQ
What is Manifold Power Iteration for MoE routers?
Manifold Power Iteration is a method that updates each MoE router row toward the principal singular direction of its corresponding expert weight matrix, then normalizes that row to keep routing stable.
How much does MPI improve an 11B MoE model?
In the paper’s 11B experiment, average accuracy across seven reported downstream tasks rises from 40.92 to 42.76. GSM8K improves from 17.89 to 27.60, while validation perplexity improves from 0.728 to 0.723 bits per byte.
Does MPI make MoE training slower?
The paper reports a 0.2% training slowdown in the 11B pretraining run. It also says MPI adds no inference overhead because the adjusted router weights can be computed when the model loads.
Is MPI only a load-balancing method?
No. MPI primarily aligns router rows with expert weight directions. Better load balance appears as a side effect in the reported 3B experiment, where MaxVio Global drops from 0.964 to 0.711.
What is the biggest limitation of the MPI router paper?
The main limitation is that MPI is compared mostly with vanilla MoE routing. The paper argues the method is compatible with other router designs, but the strongest combined baselines still need broader independent testing.
One line: MPI is interesting because it gives the MoE router a concrete job: represent the expert, not just win a top-k score. Read the original paper on arXiv.