Mixture of Experts · Language Models · Diffusion Language Models
dMoE: Block-Level Expert Routing for Diffusion LLMs
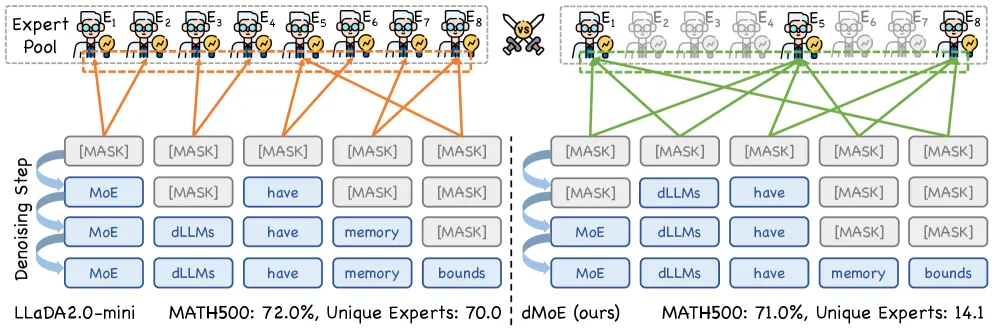
dMoE aligns token-level MoE routing with block-parallel decoding in diffusion LLMs. On LLaDA2.0-mini it cuts unique experts per block from 69.5 to 14.6, keeps 99.11% accuracy, and frees 76-80% of expert memory.
Quick answer
dMoE makes Mixture-of-Experts diffusion language models cheap to run by routing whole decoding blocks instead of individual tokens. On the open MoE diffusion model LLaDA2.0-mini, it drops the number of uniquely activated experts per block from 69.5 to 14.6 while retaining 99.11% of the original accuracy, cutting expert-weight memory by 76.64% to 79.84% and delivering a 1.14x to 1.66x end-to-end speedup. The fix is conceptual, not a heavier model: it aligns where experts get chosen with how diffusion LLMs actually decode.
The mismatch dMoE targets
Diffusion language models do not decode left to right. They unmask a whole block of tokens in parallel over several denoising steps. MoE routing, inherited from autoregressive transformers, still picks experts per token. When a block of tokens each independently selects its top-k experts, the union of experts the block touches explodes. The paper measures this directly: a single block on LLaDA2.0-mini activates 69.5 distinct experts on average, even though each token only uses a handful. Every one of those experts has to be resident in memory for the block’s forward pass, so block-parallel decoding turns MoE’s promised sparsity into a memory bottleneck instead of a saving.
That is the core observation: per-token routing and block-parallel decoding pull in opposite directions. Token routing wants maximal per-token freedom; block decoding wants a small shared working set so the parallel step stays cheap.
How block-level routing works
dMoE aggregates the token-level expert scores inside a block into one block-level distribution, then forces every token to choose from a shared coreset of experts.
The mechanism has four steps. First, compute the normal token-level routing scores for each token in the block. Second, sum the normalized scores across all tokens to form a single block-level expert distribution. Third, apply top-p selection on that distribution to pick an expert coreset whose cumulative routing mass passes a threshold. Fourth, restrict each token’s final expert choice to that coreset. Tokens still route individually, but only among the experts the block as a whole considers important.
The “learnable” part matters: the coreset is derived from the model’s own learned routing scores, not a fixed assignment, so high-traffic experts survive and long-tail experts that one stray token wanted get dropped. Because tokens in a diffusion block have bidirectional dependencies and are decoded together, the paper argues they should share an expert basis for coherence anyway, so the coreset is a feature, not just a compression hack.
Key results
- Activated experts: 69.5 to 14.6 unique experts per block on LLaDA2.0-mini, roughly a 79% cut in the block’s expert footprint.
- Accuracy retained: 99.11% of the original model’s performance across the evaluated benchmarks.
- Memory: 76.64% to 79.84% reduction in expert memory usage, the direct payoff of a smaller resident expert set.
- Latency: 1.14x to 1.66x end-to-end speedup, depending on the operating point.
- Benchmarks: evaluated on MATH500, GSM8K, ARC-C, and an MMLU math subset, against baselines including a Top-4 expert cap and the DES-S and DES-V dynamic expert-sharing methods.
Why this matters now
Diffusion LLMs are the most credible current challenge to autoregressive decoding, and the strongest open ones, like LLaDA2.0-mini, are already MoE models. That means the routing-versus-decoding mismatch is not a corner case; it sits on the main path of the most promising architecture combination in open language modeling. dMoE shows the mismatch is fixable at the routing layer without retraining a dense model or shrinking the expert pool, which is what makes MoE diffusion LLMs deployable on tighter memory budgets.
Limits and open questions
The paper is explicitly marked work-in-progress, so the evaluation is narrow. All numbers come from a single base model, LLaDA2.0-mini, so it is unproven whether the 14.6-expert coreset and the memory savings hold on larger MoE diffusion models or different expert counts. The benchmark set is reasoning-and-knowledge heavy (MATH500, GSM8K, ARC-C, MMLU math) and does not include open-ended generation, code, or long-context tasks where block coherence pressure may differ. The headline 99.11% retention is an average; the paper does not, in the material available, break out which benchmarks lose the most, and the top-p coreset threshold is a knob whose sensitivity is not fully characterized here.
FAQ
What problem does dMoE solve?
dMoE fixes the clash between block-parallel decoding in diffusion LLMs and per-token MoE routing. When every token in a parallel-decoded block independently picks experts, the block touches 69.5 distinct experts on average on LLaDA2.0-mini, all of which must sit in memory. dMoE collapses that to 14.6 by sharing one expert coreset across the block.
How much memory does dMoE save?
dMoE reduces expert-weight memory usage by 76.64% to 79.84% on LLaDA2.0-mini, with a 1.14x to 1.66x end-to-end latency speedup, because far fewer experts need to be resident for each parallel decoding step.
Does dMoE hurt accuracy?
dMoE retains 99.11% of LLaDA2.0-mini’s original accuracy across MATH500, GSM8K, ARC-C, and an MMLU math subset. The small drop reflects forcing every token in a block to route within a shared expert coreset instead of choosing freely.
What model does dMoE run on?
dMoE is demonstrated on LLaDA2.0-mini, an open-source Mixture-of-Experts diffusion language model. The paper is marked work-in-progress and reports results on that single base model, so generalization to other MoE diffusion LLMs is not yet shown.