SkillAdaptor: How LLM Agents Rewrite Their Own Skills
SkillAdaptor edits an agent's skill library from failed trajectories without touching model weights, lifting WebShop score +2.3 and PinchBench +1.5 over the frozen backbone.
Quick answer
SkillAdaptor is a training-free way to make an LLM agent better at multi-step tasks by editing the text of its skill library instead of fine-tuning the model. When a task fails, it finds the first step where things actually went wrong, blames the responsible skill, and rewrites that skill (or writes a new one). It then keeps the edit only if a re-run scores higher. The backbone model stays frozen.
The honest headline: the gains are real but small. Across three benchmarks the best deltas were +2.3 WebShop score (GLM-5), +1.7% WebShop success rate (Kimi-K2.5), +1.5 PinchBench average (GLM-5), and +1.8 Claw-Eval average (Kimi-K2.5). This is a careful, low-cost reliability patch, not a step change.
How SkillAdaptor edits a skill library
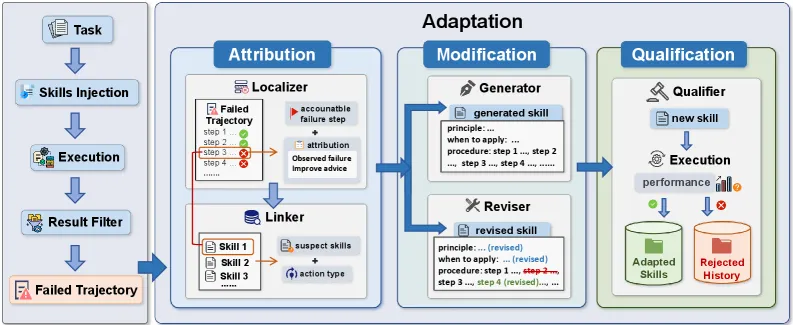
The loop has three named stages, and the design choice that matters is that nothing is updated until it has paid for itself.
- Attribution. A Localizer scans a failed trajectory and pins down the first actionable fault step. That is not the step where the task visibly broke, but the earliest point a different action would have changed the outcome. A Linker then spreads responsibility across candidate skills as weights and decides whether to revise an existing skill or mint a new one.
- Modification. A Modifier either rewrites the highest-weighted skill (revision mode) or synthesizes a new skill from the localized context (generation mode). A semantic-similarity filter blocks near-duplicate skills so the library does not bloat.
- Qualification. Every proposed update is re-executed under both the current skill set (K) and the candidate set (K+). The edit is accepted only when performance improves; the paper’s acceptance rule is Δ≥0.
At inference time the frozen LLM just retrieves relevant skills by embedding similarity plus reranking, then executes. So all the “learning” lives in editable natural-language skills, which is what makes it portable across backbones.
Why a frozen backbone is the point
The interesting bet here is refusing to touch weights at all. Fine-tuning an agent on its own failures needs gradients, a training stack, and a model you are allowed to update, none of which you get with a closed API model like GPT-5.2. By keeping the backbone frozen and putting all adaptation into a retrievable skill library, SkillAdaptor works the same whether the agent is Kimi-K2.5, GLM-5, or GPT-5.2. That is the practical reason to care: it is a wrapper, not a retraining pipeline.
The first-fault-step localization is also the part doing the heavy lifting. Most “learn from failures” agent loops dump the whole bad trajectory back into context and hope the model self-corrects. Localizing the earliest causal mistake and attaching credit to a specific skill is a sharper signal, and the Δ≥0 acceptance gate is what stops the library from drifting into junk over many rounds.
Key results
- WebShop: +2.3 score (GLM-5) and +1.7% success rate (Kimi-K2.5) over the frozen backbone.
- PinchBench: +1.5 average score percentage (GLM-5).
- Claw-Eval: +1.8 average score (Kimi-K2.5).
- vs. EvoSkill on WebShop: SkillAdaptor reached 41.6 score vs EvoSkill’s 40.4 for Kimi-K2.5, ahead but by roughly one point.
- Reported figures track accepted writes and gains across adaptation rounds, plus interaction-step and input-token statistics, so the cost side is at least measured rather than hidden.
The pattern across all three suites is consistent improvement in the low single digits. Consistency across backbones is the stronger story; the magnitude is modest.
Limits and open questions
The authors are candid about where this breaks. SkillAdaptor works best when failures expose observable intermediate signals and the required tool dependencies are available. Under sparse or delayed feedback, or when an external interface the agent needs is simply missing, the method weakens. That is a meaningful caveat, because those hard, under-instrumented environments are exactly where agents fail most.
Two things to weigh before adopting it. First, evaluation is limited to three public benchmarks with no long-term deployment study, so we do not know how the library behaves after thousands of rounds in the wild. Second, the per-task cost is real: the Qualification stage re-executes each candidate edit under two skill sets, which roughly doubles execution for accepted updates. If you are running cheap, high-volume tasks, that overhead may eat the +1.5-point benefit.
Who should skip it: anyone whose agent failures are dense-reward, weight-tunable, and tool-rich already has cheaper paths (just fine-tune). SkillAdaptor earns its keep specifically when the backbone is frozen and failures are legible.
FAQ
Does SkillAdaptor fine-tune the LLM?
No. SkillAdaptor never updates model weights; the backbone is frozen. All adaptation happens by editing a natural-language skill library that the agent retrieves at inference time, which is why the same method runs on closed models like GPT-5.2.
How much does SkillAdaptor actually improve agent performance?
Modestly and consistently. The best reported gains are +2.3 WebShop score, +1.7% WebShop success rate, +1.5 on PinchBench, and +1.8 on Claw-Eval over the frozen backbone. It is a reliability patch in the low single digits, not a large jump.
What makes SkillAdaptor different from replaying failed trajectories into context?
Instead of feeding the whole failed run back to the model, SkillAdaptor localizes the first actionable fault step, assigns credit to a specific skill, rewrites that skill, and accepts the change only if a re-run scores at least as well (Δ≥0).