Z-Reward:把推理内化进打分分布的图像奖励模型
Z-Reward 让图像奖励模型预测评分的整条分布而非标量。9B 学生只输出一个 token 就拿到 88.6% 准确率,下游 T2I 相比 SFT 净增 41.3% GSB。
快速答案
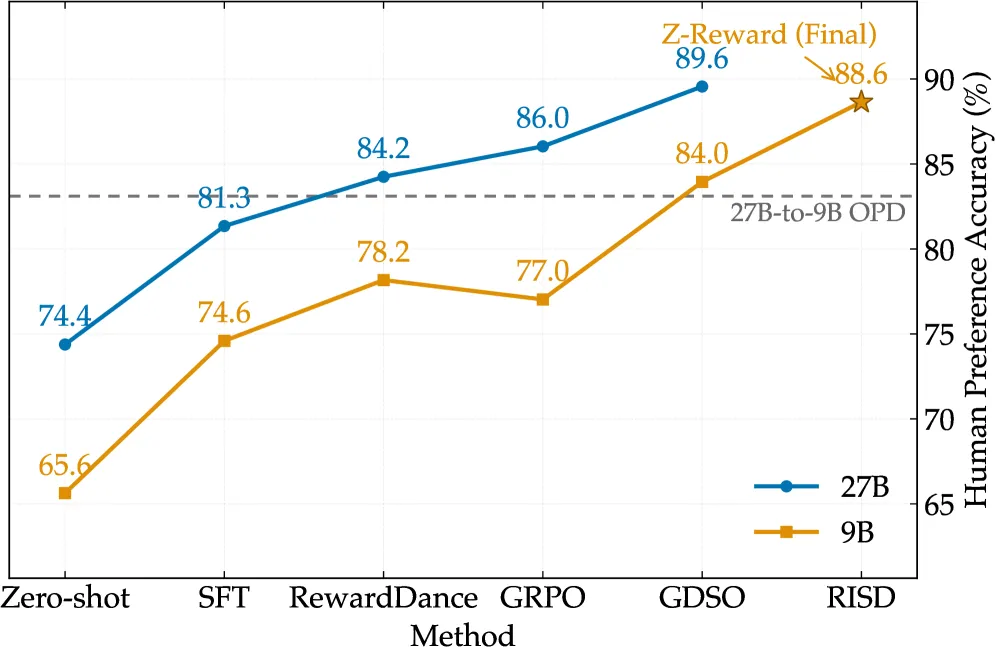
Z-Reward 是一个文生图奖励模型,它预测的是评分的整条分布,而不是吐出一个标量分数。用 Group-wise Direct Score Optimization(GDSO)训练的 27B 教师拿到 89.6% 人类偏好准确率;蒸馏出的 9B 学生达到 88.6%,而且推理时只输出一个 token。把这个奖励用到图像后训练上,作者报告相比 SFT 基线净增 41.3% 的 GSB(Good-Same-Bad)。卖点是校准加效率:保留推理模型会给出的信号,把推理成本从在线服务里去掉。
标量奖励丢了哪些信息
普通奖励模型把一次判断压成一个数字。RLHF 或 GRPO 类优化器追的就是这个数,但它扔掉了对图像很要紧的两样东西:打分者有多确定,以及两个候选到底差多远。5 分制下打 4.0 和 4.2 的两张图,差距很小,也很噪。标量头却把它和 2.0 对 4.5 当成一回事。标注者之间的分歧也一起没了。
Z-Reward 把判断保留成一条概率分布,落在 9 档半分制(1.0 到 5.0)上,覆盖四个维度:图文对齐、真实感、美学、物理合理性。分布直接编码了不确定性;它的期望给优化提供一个平滑的标量,而分布形状仍然留着用于监督。这是全文的核心赌注。
GDSO 怎么训练教师
GDSO 是教师的训练目标,它叠了三个信号而不是一个。一个是从预测分布的期望算出的策略梯度项,正是它把一条推理链接到了可用的奖励上。在它之上是两个监督项:一个逐点交叉熵损失,把每个分数档对齐到人工标签;一个成对项,逼着两张图之间的预测分差去匹配标注的分差。成对那一项是让模型在绝对校准漂移时仍能排对序的关键。
教师是一个先推理再打分的 27B 视觉语言模型。在内部标注测试集上,它报告 89.6% 的人类偏好准确率(HPA),PLCC 0.7620,SRCC 0.7132。在同一套设置下对比基线,这是实打实的差距:SFT 是 81.35% HPA,RewardDance 84.25%,GRPO 类奖励 86.04%。也就是说,大约 3 到 8 个点的 HPA 来自分布式目标,而不是更大的模型或更多数据。
关键结果
- 教师(27B,GDSO): 内部四维测试集上 89.6% 人类偏好准确率(HPA),PLCC 0.7620,SRCC 0.7132。
- 学生(9B,RISD): 88.6% HPA(PLCC 0.7391,SRCC 0.6882),推理时只输出一个 token,和教师差约一个点。
- 同设置下的奖励基线: SFT 81.35%,RewardDance 84.25%,GRPO 类奖励 86.04% HPA,都低于 89.6% 的教师。
- 蒸馏消融: RISD 一个 token 拿 88.64% HPA;on-policy distillation 约 750 token 才 83.11%。
- 下游 T2I: 相比 SFT 生成器基线,人工偏好净增 41.3% GSB。
每个数字都要结合设置读。HPA 和 GSB 都用作者自己的准则和标注者打分,说明方法在这里内部自洽、也胜过自家基线,但不代表这些数字能迁到公开基准或别的生成器上。
RISD 到底蒸了什么
Reasoning-Internalized Score Distillation(RISD)是让这套东西能部署的关键。教师的价值来自打分前对图像的推理,但在 RL 循环里每次奖励调用都跑一遍推理链太贵。RISD 用一个 KL 项,训练 9B 学生去匹配教师那条以推理为条件的打分分布,推理时不产出任何显式推理文字。学生只输出一个 token。
结果就是那个出人意料的细节:9B 学生拿到 88.6% HPA(PLCC 0.7391,SRCC 0.6882),和 27B 教师只差一个点出头。对比 on-policy distillation(OPD)的消融,是”蒸分布而不是蒸文字才有效”最干净的证据。保留显式推理的 OPD 落在 83.11% HPA,每次打分要花约 750 个输出 token。RISD 用一个 token 达到 88.64%。同样的学生规模、同样的教师,差别只在你复制的是推理轨迹还是它产出的分布。
那个下游数字从哪来
41.3% 净 GSB 提升是大多数人会引用的标题数字,它需要一个护栏。GSB 是人工并排偏好(Good 减 Bad 后归一化),拿后训练生成器的图和 SFT 基线的图比。它衡量的是这个奖励作为优化信号时,产出的图是不是更受人喜欢。它不是奖励模型的准确率,也不是 FID 或 GenEval 这类标准自动指标。所以这个结果说明:在他们自己的人评下,这个奖励比 SFT 起点是更好的优化目标。这是该测的东西,但打分用的偏好判断,和训练奖励用的是同一类。
局限与存疑
最大缺口是外部基准。准确率、相关性和 GSB 全都测在一个内部标注测试集上,用的是作者自定的四维评分准则。没有公开偏好基准,没有 FID/CLIPScore/GenEval 交叉验证,评分准则本身也是内部设计的,所以很难知道 89.6% 和 41.3% 换到别的团队数据或别的生成器上还成不成立。
成本是第二个问题。学生推理便宜,但先用推理训 27B 教师、再蒸成 9B 学生是两段式管线,需要大规模的、按准则对齐的分布标签。论文没有展示教师变小或档位变粗会不会让收益掉下来。
第三,GSB 是相对 SFT 基线报的,不是相对一个用 RewardDance 或 GRPO 奖励调过的强 RLHF 生成器。所以最干净的结论是”比没有奖励好”;更有意思的对比,也就是同一个 RL 循环里分布式奖励对强标量奖励,被留给了奖励准确率表,而没进生成评测。
常见问题
Z-Reward 和标量奖励模型有什么区别?
Z-Reward 预测的是 9 档评分准则(1.0 到 5.0)上、四个维度的概率分布,而不是一个标量。分布保留了标注者的不确定性和候选之间的差距大小,期望仍然给优化提供平滑标量。标量头把这些信息都丢了。
Z-Reward 的 9B 学生为什么一个 token 就能到 88.6%?
RISD 用 KL 损失训练 9B 学生去匹配 27B 教师那条以推理为条件的打分分布,所以学生根本不用生成推理链。它推理时只输出一个 token,拿到 88.6% 人类偏好准确率,和教师的 89.6% 只差一个点出头。
Z-Reward 为什么 RISD 比 on-policy distillation 好?
保留显式推理文字的 OPD 达到 83.11% 准确率,每次打分约 750 个输出 token。RISD 蒸的是分布本身而不是文字,用一个 token 达到 88.64%。消融说明推理的价值在它条件出的那条分布里,不在被复述的链条里。
41.3% 的 GSB 提升能证明 Z-Reward 在文生图上赢过其他 RLHF 奖励吗?
不能。41.3% 净 GSB 是相对 SFT 基线的人工并排偏好,说明这个奖励作为优化信号比没有奖励有用。它没有和用 RewardDance 或 GRPO 奖励调过的生成器比,也没有 FID 或 GenEval 交叉验证。
一句话:Z-Reward 保住了推理打分者的校准,服务成本却只有一个 token,但每个标题数字都在内部准则上,先复现管线再信数字。阅读 arXiv 原文。