MRAgent:重建式图记忆,而非检索
MRAgent 给 LLM 智能体一张图记忆,让模型边推理边遍历,LoCoMo 的 LLM-Judge 从 68.3 升到 84.2,每样本只花 118k token。
快速答案
MRAgent 是给 LLM 智能体用的记忆层,把一次性检索换成了在图上来回推理的循环。LoCoMo 基准上(Gemini-2.5-Flash 后端),它把整体 LLM-Judge 分从 68.31(最强基线 Mem0)拉到 84.21,相对提升 23.3%;LongMemEval 上拿到 72.95,各基线只有 54-55 上下。反常的一点是它还最省:每样本 118k token,而 A-Mem 要 632k、LangMem 要 3,268k。这些提升来自记忆框架本身,不是换了更强的底模。基线用的是同一批后端。
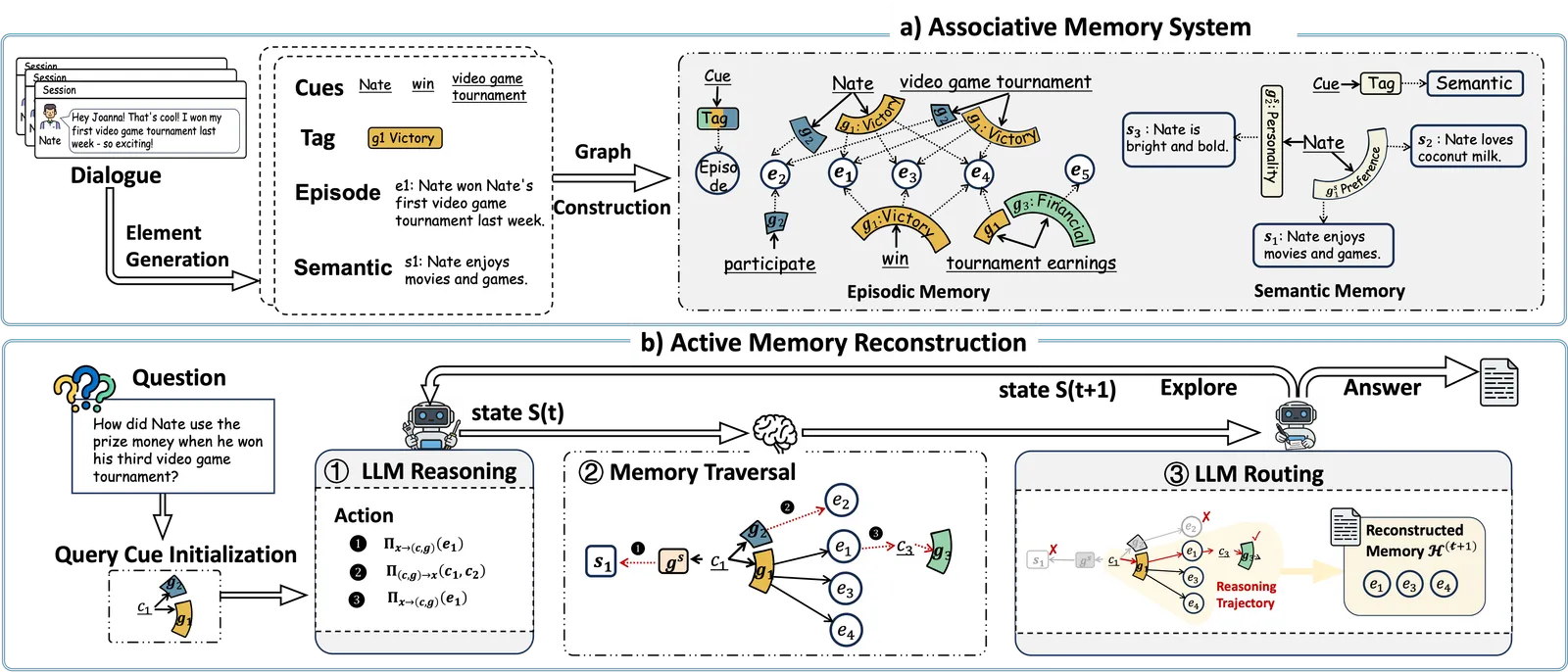
Cue-Tag-Content 图怎么搭
存的是一张异构图,不是向量库。三类节点:cue(实体、属性这类细粒度关键词)、content(真正的记忆内容)、tag(夹在二者之间,概括 cue 和 content 的关联)。一条三元组就是(cue, tag, content)。检索时智能体先挑几个相关 tag,再按 tag 取 content。这一两步走的设计让大图能跑得动:tag 让模型在加载昂贵的情景文本之前就先剪掉无关分支。
content 分层存。情景层放具体事件,挂在统一时间轴上,检索时能加时间约束;语义层放稳定事实(偏好、属性),锚在某个 cue 上,不用翻长历史就能直接取。建图阶段刻意做得轻,把重活留到查询时再算,这也是它 token 账单低的原因之一。
主动重建和”先检索后推理”差在哪
常规记忆智能体取固定 top-k 或走预设子图,然后对取回的东西推理一遍就结束。MRAgent 把两步交织起来。每一轮,LLM 读查询加已积累的证据,选遍历动作,图按动作扩展,LLM 再做路由:留下相关节点,剪掉其余,直到判定证据够答题为止。
作者倚重的机制是查询中途发现新线索。论文那个例子里,关于电竞比赛的查询,要等智能体从中间证据推出”七月”这个时间锚点、再找到对应事件,才答得上来。一次性把检索全提交的被动检索做不到这件事。论文还给了定理:检索预算 T 不小于 2 时,被动假设类严格包含于主动假设类。自适应检索能表达非自适应的一切,还能表达更多。
关键结果
- LoCoMo,Gemini 后端:整体 LLM-Judge 84.21,对 Mem0 的 68.31,相对提升 23.3%。时间类问题涨得最猛,从 Mem0 的 61.68 到 80.37。
- LoCoMo,Claude-Sonnet-4.5 后端:整体 88.32,对 LangMem 的 78.61,相对约 12.4%。后端越强,涨幅越小。
- LongMemEval,Gemini:整体 72.95,各基线在 53-55。混合变体(Claude 做检索、Gemini 建图)到 86.76,比最强基线相对高 32%。
- LongMemEval 开销:每样本 118k token、586 秒,A-Mem 是 632k token、MemoryOS 是 3,135 秒。MRAgent 在两个维度上同时拿到最好或接近最好。
- LoCoMo 多跳消融:加上推理循环,在每种图结构上都胜过只有结构的检索;只看纯结构变体时,准确率从 Cue-Episode 到 Cue-Tag-Episode 到 Cue-Tag-Content 单调上升。
- 多轮行为:单跳和时间类查询约三轮就接近满召回;多跳召回持续往上爬,逐步累计涨幅超过 30%。
这些数字是关于记忆系统的证据,不是关于模型的。后端(Gemini-2.5-Flash、Claude-Sonnet-4.5)和基线一样,LLM-Judge 用的是 GPT-4o-mini。比的是框架对框架。
省钱和提分为什么能同时发生
多数记忆系统拿 token 换召回:反复总结历史、在建图时就预算好各种依赖。MRAgent 反过来。建图便宜,昂贵的关系运算只在查询时做,且只针对当前这一个问题。tag 再当一道便宜的过滤:模型先在短短的 tag 列表上推理,才去碰完整情景内容。于是访问是按需的、有选择的,不会把查询根本用不到的记忆也加载进来。这就是为什么一个每次查询都多做推理的系统,反而 token 账单最小。
消融把功劳来源钉死了:推理循环是更大的那根杠杆,不是图的形状。带推理的变体全面压过只有结构的;Cue-Tag-Content 结构的作用主要是给这个循环提供干净的关联路径去走、去剪。
局限与存疑
两个后端都是闭源前沿模型,没有开源权重的结果。换一个更弱的 LLM、未必能稳定推出”七月”这类线索时,提升还剩多少,不清楚。推理循环的上限取决于跑它的模型。
LongMemEval 上 86.76 这个最高分来自混合配置(Claude 检索、Gemini 建图),工程上说得通,但不是同一个模型的同条件数字。更干净的同模型分是 72.95。
打分靠 GPT-4o-mini 当裁判,外加 F1。LLM-Judge 可能偏爱流畅的回答、也会带上裁判自身的偏好,换个裁判,和基线的差距读数可能不同。评测只覆盖两个对话记忆基准(LoCoMo、LongMemEval);重建对工具调用日志、代码历史或非对话类智能体记忆有没有用,没测。建图成本也只按 token 算,没给索引那一遍的实际墙钟延迟,而这对线上智能体很要紧。
常见问题
MRAgent 里的 Cue-Tag-Content 图记忆架构是什么?
是 MRAgent 的记忆存储:一张图,cue(关键词)、content(记忆内容)、tag(概括 cue 怎么连到 content 的关系)组成三元组。查询时智能体先选 tag、再按 tag 取 content,这样能在加载昂贵情景文本前就剪掉无关分支。
MRAgent 在 LoCoMo 上比 Mem0 高多少?
LoCoMo 上用 Gemini-2.5-Flash 后端,MRAgent 整体 LLM-Judge 84.21,Mem0 是 68.31,相对提升 23.3%。换成 Claude-Sonnet-4.5 后端,相对涨幅收窄到约 12.4%。
MRAgent 重建胜过检索,是模型还是记忆框架的方法在起作用?
框架的。MRAgent 用的是和基线相同的冻结后端(Gemini-2.5-Flash、Claude-Sonnet-4.5);提升来自 Cue-Tag-Content 图加主动重建循环,而消融显示推理循环的贡献比图结构本身更大。
MRAgent 多做推理,为什么反而比 A-Mem、LangMem 便宜?
它把建图做得轻,关系运算推迟到查询时、只针对一个问题,tag 又在加载情景内容前先滤掉无关分支。LongMemEval 上它每样本 118k token,A-Mem 632k、LangMem 3,268k。
MRAgent 的主要局限是什么?
只在两个闭源前沿后端上测过,没有开源权重结果;LongMemEval 最高分 86.76 用的是混合后端而非单一模型;打分依赖 GPT-4o-mini 裁判;评测局限于对话记忆基准,没覆盖工具或代码历史。
一句话:MRAgent 说明让 LLM 边推理边走图记忆,在长对话任务上能胜过固定检索,而且更省,但证据只有两个对话基准、跑在闭源模型上。读arXiv 原文。